
In computing, a data warehouse, also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis and is considered a core component of business intelligence. Data warehouses are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place that are used for creating analytical reports for workers throughout the enterprise. This is beneficial for companies as it enables them to interrogate and draw insights from their data and make decisions.
Degeneracy, degenerate, or degeneration may refer to:

In computing, extract, transform, load (ETL) is a three-phase process where data is extracted, transformed and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on reoccurring schedules either as single jobs or aggregated into a batch of jobs.
Data profiling is the process of examining the data available from an existing information source and collecting statistics or informative summaries about that data. The purpose of these statistics may be to:
- Find out whether existing data can be easily used for other purposes
- Improve the ability to search data by tagging it with keywords, descriptions, or assigning it to a category
- Assess data quality, including whether the data conforms to particular standards or patterns
- Assess the risk involved in integrating data in new applications, including the challenges of joins
- Discover metadata of the source database, including value patterns and distributions, key candidates, foreign-key candidates, and functional dependencies
- Assess whether known metadata accurately describes the actual values in the source database
- Understanding data challenges early in any data intensive project, so that late project surprises are avoided. Finding data problems late in the project can lead to delays and cost overruns.
- Have an enterprise view of all data, for uses such as master data management, where key data is needed, or data governance for improving data quality.

In computing, the star schema is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts. The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.
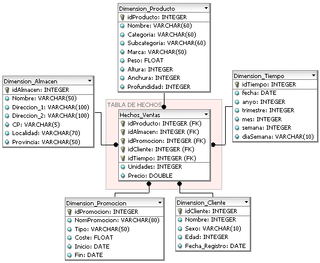
In data warehousing, a fact table consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables. Where multiple fact tables are used, these are arranged as a fact constellation schema. A fact table typically has two types of columns: those that contain facts and those that are a foreign key to dimension tables. The primary key of a fact table is usually a composite key that is made up of all of its foreign keys. Fact tables contain the content of the data warehouse and store different types of measures like additive, non-additive, and semi-additive measures.

In computing, a snowflake schema is a logical arrangement of tables in a multidimensional database such that the entity relationship diagram resembles a snowflake shape. The snowflake schema is represented by centralized fact tables which are connected to multiple dimensions. "Snowflaking" is a method of normalizing the dimension tables in a star schema. When it is completely normalized along all the dimension tables, the resultant structure resembles a snowflake with the fact table in the middle. The principle behind snowflaking is normalization of the dimension tables by removing low cardinality attributes and forming separate tables.

A dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. Commonly used dimensions are people, products, place and time.
In a data warehouse, a measure is a property on which calculations can be made. A measure can either be categorical, algebraic or holistic.
Ralph Kimball is an author on the subject of data warehousing and business intelligence. He is one of the original architects of data warehousing and is known for long-term convictions that data warehouses must be designed to be understandable and fast. His bottom-up methodology, also known as dimensional modeling or the Kimball methodology, is one of the two main data warehousing methodologies alongside Bill Inmon.
A slowly changing dimension (SCD) in data management and data warehousing is a dimension which contains relatively static data which can change slowly but unpredictably, rather than according to a regular schedule. Some examples of typical slowly changing dimensions are entities such as names of geographical locations, customers, or products.
Dimensional modeling (DM) is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, as a bottom-up approach. An alternative approach from Inmon advocates a top down design of the model of all the enterprise data using tools such as entity-relationship modeling (ER).

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
In the data warehouse practice of extract, transform, load (ETL), an early fact or early-arriving fact, also known as late-arriving dimension or late-arriving data, denotes the detection of a dimensional natural key during fact table source loading, prior to the assignment of a corresponding primary key or surrogate key in the dimension table. Hence, the fact which cites the dimension arrives early, relative to the definition of the dimension value.

Data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems. It is also a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault must be accompanied by record source and load date attributes, enabling an auditor to trace values back to the source. The concept was published in 2000 by Dan Linstedt.
The dimensional fact model (DFM) is an ad hoc and graphical formalism specifically devised to support the conceptual modeling phase in a data warehouse project. DFM is extremely intuitive and can be used by analysts and non-technical users as well. A short-term working is sufficient to realize a clear and exhaustive representation of multidimensional concepts. It can be used from the initial data warehouse life-cycle steps, to rapidly devise a conceptual model to share with customers.
The Kimball lifecycle is a methodology for developing data warehouses, and has been developed by Ralph Kimball and a variety of colleagues. The methodology "covers a sequence of high level tasks for the effective design, development and deployment" of a data warehouse or business intelligence system. It is considered a "bottom-up" approach to data warehousing as pioneered by Ralph Kimball, in contrast to the older "top-down" approach pioneered by Bill Inmon.
An aggregate is a type of summary used in dimensional models of data warehouses to shorten the time it takes to provide answers to typical queries on large sets of data. The reason why aggregates can make such a dramatic increase in the performance of a data warehouse is the reduction of the number of rows to be accessed when responding to a query.
The enterprise bus matrix is a data warehouse planning tool and model created by Ralph Kimball, and is part of the data warehouse bus architecture. The matrix is the logical definition of one of the core concepts of Kimball’s approach to dimensional modeling conformed dimension.
The following is provided as an overview of and topical guide to databases: