Related Research Articles

In computing, a data warehouse, also known as an enterprise data warehouse (EDW), is a system used for reporting and data analysis and is considered a core component of business intelligence. Data warehouses are central repositories of integrated data from one or more disparate sources. They store current and historical data in one single place that are used for creating reports. This is beneficial for companies as it enables them to interrogate and draw insights from their data and make decisions.
Database normalization is the process of structuring a relational database in accordance with a series of so-called normal forms in order to reduce data redundancy and improve data integrity. It was first proposed by British computer scientist Edgar F. Codd as part of his relational model.
A relational database (RDB) is a database based on the relational model of data, as proposed by E. F. Codd in 1970. A database management system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems are equipped with the option of using SQL for querying and updating the database.

In computing, extract, transform, load (ETL) is a three-phase process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collated from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.
A foreign key is a set of attributes in a table that refers to the primary key of another table, linking these two tables. In the context of relational databases, a foreign key is subject to an inclusion dependency constraint that the tuples consisting of the foreign key attributes in one relation, R, must also exist in some other relation, S; furthermore that those attributes must also be a candidate key in S.

Referential integrity is a property of data stating that all its references are valid. In the context of relational databases, it requires that if a value of one attribute (column) of a relation (table) references a value of another attribute, then the referenced value must exist.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.

In computing, the star schema or star model is the simplest style of data mart schema and is the approach most widely used to develop data warehouses and dimensional data marts. The star schema consists of one or more fact tables referencing any number of dimension tables. The star schema is an important special case of the snowflake schema, and is more effective for handling simpler queries.
A temporal database stores data relating to time instances. It offers temporal data types and stores information relating to past, present and future time. Temporal databases can be uni-temporal, bi-temporal or tri-temporal.
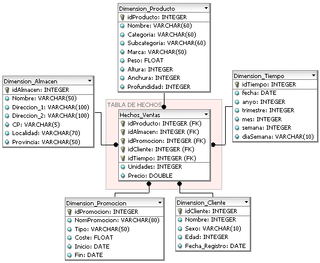
In data warehousing, a fact table consists of the measurements, metrics or facts of a business process. It is located at the center of a star schema or a snowflake schema surrounded by dimension tables. Where multiple fact tables are used, these are arranged as a fact constellation schema. A fact table typically has two types of columns: those that contain facts and those that are a foreign key to dimension tables. The primary key of a fact table is usually a composite key that is made up of all of its foreign keys. Fact tables contain the content of the data warehouse and store different types of measures like additive, non-additive, and semi-additive measures.
A table is a collection of related data held in a table format within a database. It consists of columns and rows.

A dimension is a structure that categorizes facts and measures in order to enable users to answer business questions. Commonly used dimensions are people, products, place and time.
Data cleansing or data cleaning is the process of detecting and correcting corrupt or inaccurate records from a record set, table, or database and refers to identifying incomplete, incorrect, inaccurate or irrelevant parts of the data and then replacing, modifying, or deleting the dirty or coarse data. Data cleansing may be performed interactively with data wrangling tools, or as batch processing through scripting or a data quality firewall.
According to Ralph Kimball, in a data warehouse, a degenerate dimension is a dimension key in the fact table that does not have its own dimension table, because all the interesting attributes have been placed in analytic dimensions. The term "degenerate dimension" was originated by Ralph Kimball.
A slowly changing dimension (SCD) in data management and data warehousing is a dimension which contains relatively static data which can change slowly but unpredictably, rather than according to a regular schedule. Some examples of typical slowly changing dimensions are entities such as names of geographical locations, customers, or products.
An entity–attribute–value model (EAV) is a data model optimized for the space-efficient storage of sparse—or ad-hoc—property or data values, intended for situations where runtime usage patterns are arbitrary, subject to user variation, or otherwise unforeseeable using a fixed design. The use-case targets applications which offer a large or rich system of defined property types, which are in turn appropriate to a wide set of entities, but where typically only a small, specific selection of these are instantiated for a given entity. Therefore, this type of data model relates to the mathematical notion of a sparse matrix. EAV is also known as object–attribute–value model, vertical database model, and open schema.
Dimensional modeling (DM) is part of the Business Dimensional Lifecycle methodology developed by Ralph Kimball which includes a set of methods, techniques and concepts for use in data warehouse design. The approach focuses on identifying the key business processes within a business and modelling and implementing these first before adding additional business processes, as a bottom-up approach. An alternative approach from Inmon advocates a top down design of the model of all the enterprise data using tools such as entity-relationship modeling (ER).

A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.

Datavault or data vault modeling is a database modeling method that is designed to provide long-term historical storage of data coming in from multiple operational systems. It is also a method of looking at historical data that deals with issues such as auditing, tracing of data, loading speed and resilience to change as well as emphasizing the need to trace where all the data in the database came from. This means that every row in a data vault must be accompanied by record source and load date attributes, enabling an auditor to trace values back to the source. The concept was published in 2000 by Dan Linstedt.
The following is provided as an overview of and topical guide to databases:
References
- ↑ "Kimball, Ralph. Design Tip #57: Early Arriving Facts. August, 2004" (PDF). Archived from the original (PDF) on 2007-10-12. Retrieved 2008-04-25.
- ↑ Early Arriving Facts / Late Arriving Dimensions - LeapFrogBI
- ↑ A gentle introduction to bitemporal data challenges - Roelant Vos