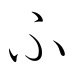U is one of the Japanese kana, each of which represents one mora. In the modern Japanese system of alphabetical order, they occupy the third place in the modern Gojūon (五十音) system of collating kana. In the Iroha, they occupied the 24th position, between む and ゐ. In the Gojūon chart, う lies in the first column and the third row. Both represent the sound. In the Ainu language, the small katakana ゥ represents a diphthong, and is written as w in the Latin alphabet.
Ha is one of the Japanese kana, each of which represent one mora. Both represent. They are also used as a grammatical particle and serve as the topic marker of the sentence. は originates from 波 and ハ from 八.
き, in hiragana, キ in katakana, is one of the Japanese kana, which each represent one mora. Both represent and are derived from a simplification of the 幾 kanji. The hiragana character き, like さ, is drawn with the lower line either connected or disconnected.
く, in hiragana or ク in katakana, is one of the Japanese kana, which each represent one mora. Both represent and their shapes come from the kanji 久.
け, or ケ, is one of the Japanese kana, each of which represents one mora. Both represent. The shape of these kana come from the kanji 計 and 介, respectively.
こ, in hiragana or コ in katakana, is one of the Japanese kana, each of which represents one mora. Both represent IPA:[ko]. The shape of these kana comes from the kanji 己.
し, in hiragana, or シ in katakana, is one of the Japanese kana, which each represent one mora. Both represent the phonemes, reflected in the Nihon-shiki and Kunrei-shiki romanization si, although for phonological reasons, the actual pronunciation is, which is reflected in the Hepburn romanization shi. The shapes of these kana have origins in the character 之. The katakana form has become increasingly popular as an emoticon in the Western world due to its resemblance to a smiling face.
せ, in hiragana, or セ in katakana, is one of the Japanese kana, each of which represents one mora. Both represent the sound, and when written with dakuten represent the sound [ze]. In the Ainu language, the katakana セ is sometimes written with a handakuten (which can be entered into a computer as either one character or two combined ones to represent the sound, and is interchangeable with ツェ.
Tsu is one of the Japanese kana, each of which represents one mora. Both are phonemically, reflected in the Nihon-shiki and Kunrei-shiki Romanization tu, although for phonological reasons, the actual pronunciation is, reflected in the Hepburn romanization tsu.
と, in hiragana, or ト in katakana, is one of the Japanese kana, each of which represents one mora. Both represent the sound, and when written with dakuten represent the sound. In the Ainu language, the katakana ト can be written with a handakuten (which can be entered in a computer as either one character or two combined characters to represent the sound, and is interchangeable with the katakana ツ゚.
Nu, ぬ in hiragana, or ヌ in katakana, is one of the Japanese kana each representing one mora. Both hiragana and katakana are made in two strokes and represent. They are both derived from the Chinese character 奴. In the Ainu language, katakana ヌ can be written as small ㇴ to represent a final n, and is interchangeable with the standard katakana ン.
ひ, in hiragana, or ヒ in katakana, is one of the Japanese kana, which each represent one mora. Both can be written in two strokes, sometimes one for hiragana, and both are phonemically although for phonological reasons, the actual pronunciation is. The pronunciation of the voiceless palatal fricative [ç] is similar to that of the English word hue [çuː] for some speakers.
ろ, in hiragana, or ロ in katakana, is one of the Japanese kana, each of which represents one mora. The hiragana is written in one stroke, katakana in three. Both represent and both originate from the Chinese character 呂. The Ainu language uses a small ㇿ to represent a final r sound after an o sound. The combination of an R-column kana letter with handakuten ゜ – ろ゚ in hiragana and ロ゚ in katakana – was introduced to represent [lo] in the early 20th century.
れ, in hiragana, or レ in katakana, is one of the Japanese kana, each of which represents one mora. The hiragana is written in two strokes, while katakana in one. Both represent the sound. The shapes of these kana have origins in the character 礼. The Ainu language uses a small katakana ㇾ to represent a final r sound after an e sound. The combination of an R-column kana letter with handakuten ゜- れ゚ in hiragana, and レ゚ in katakana was introduced to represent [le] in the early 20th century.
る, in hiragana, or ル in katakana, is one of the Japanese kana, each of which represent one mora. The hiragana is written in one stroke; the katakana in two. Both represent the sound. The Ainu language uses a small katakana ㇽ to represent a final r sound after an u sound. The combination of an R-column kana letter with handakuten ゜- る゚ in hiragana, and ル゚ in katakana was introduced to represent [lu] in the early 20th century.
Ri is one of the Japanese kana, each of which represent one mora. Both are written with two strokes and both represent the sound. Both originate from the character 利. The Ainu language uses a small katakana ㇼ to represent a final r sound after an i sound. The combination of an R-column kana letter with handakuten ゜- り゚ in hiragana, and リ゚ in katakana was introduced to represent [li] in the early 20th century.
Ra is one of the Japanese kana, which each represent one mora. Both versions are written with two strokes and have origins in the character 良; both characters represent the sound. The Ainu language uses a small katakana ㇻ to represent a final r sound after an a sound. The combination of an R-column kana letter with handakuten ゜- ら゚ in hiragana, and ラ゚ in katakana was introduced to represent [la] in the early 20th century.
Wa is one of the Japanese kana, which each represent one mora. The combination of a W-column kana letter with わ゙ in hiragana was introduced to represent [va] in the 19th century and 20th century. It represents and has origins in the character 和. There is also a small ゎ/ヮ, that is used to write the morae /kwa/ and /gwa/, which are almost obsolete in contemporary standard Japanese but still exist in the Ryukyuan languages. A few loanword such as シークヮーサー(shiikwaasa from Okinawan language) and ムジカ・アンティクヮ・ケルン contains this letter in Japanese. Katakana ワ is also sometimes written with dakuten, ヷ, to represent a sound in foreign words; however, most IMEs lack a convenient way to write this. It is far more common to represent the /va/ sound with the digraph ヴァ.
ゑ in hiragana, or ヱ in katakana, is an obsolete Japanese kana that is normally pronounced in current-day Japanese. The combination of a W-column kana letter with "ゑ゙" in hiragana was introduced to represent [ve] in the 19th and 20th centuries.
を, in hiragana, or ヲ in katakana, is one of the Japanese kana, each of which represents one mora. Historically, both are phonemically, reflected in the Nihon-shiki wo, although the contemporary pronunciation is, reflected in the Hepburn romanization and Kunrei-shiki romanization o. Thus it is pronounced identically to the kana o. Despite this phonemic merger, the kana wo is sometimes regarded as a distinct phoneme from /o/, represented as /wo/, to account for historical pronunciation and for orthographic purposes.