Knowledge representation and reasoning is a field of artificial intelligence (AI) dedicated to representing information about the world in a form that a computer system can use to solve complex tasks, such as diagnosing a medical condition or having a natural-language dialog. Knowledge representation incorporates findings from psychology about how humans solve problems and represent knowledge, in order to design formalisms that make complex systems easier to design and build. Knowledge representation and reasoning also incorporates findings from logic to automate various kinds of reasoning.

The Semantic Web, sometimes known as Web 3.0, is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.
The Resource Description Framework (RDF) is a method to describe and exchange graph data. It was originally designed as a data model for metadata by the World Wide Web Consortium (W3C). It provides a variety of syntax notations and data serialization formats, of which the most widely used is Turtle.
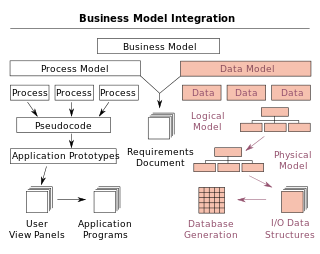
A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. For instance, a data model may specify that the data element representing a car be composed of a number of other elements which, in turn, represent the color and size of the car and define its owner.
The Web Ontology Language (OWL) is a family of knowledge representation languages for authoring ontologies. Ontologies are a formal way to describe taxonomies and classification networks, essentially defining the structure of knowledge for various domains: the nouns representing classes of objects and the verbs representing relations between the objects.
RDF Schema (Resource Description Framework Schema, variously abbreviated as RDFS, RDF(S), RDF-S, or RDF/S) is a set of classes with certain properties using the RDF extensible knowledge representation data model, providing basic elements for the description of ontologies. It uses various forms of RDF vocabularies, intended to structure RDF resources. RDF and RDFS can be saved in a triplestore, then one can extract some knowledge from them using a query language, like SPARQL.
SPARQL is an RDF query language—that is, a semantic query language for databases—able to retrieve and manipulate data stored in Resource Description Framework (RDF) format. It was made a standard by the RDF Data Access Working Group (DAWG) of the World Wide Web Consortium, and is recognized as one of the key technologies of the semantic web. On 15 January 2008, SPARQL 1.0 was acknowledged by W3C as an official recommendation, and SPARQL 1.1 in March, 2013.
A semantic wiki is a wiki that has an underlying model of the knowledge described in its pages. Regular, or syntactic, wikis have structured text and untyped hyperlinks. Semantic wikis, on the other hand, provide the ability to capture or identify information about the data within pages, and the relationships between pages, in ways that can be queried or exported like a database through semantic queries.
In information science, an upper ontology is an ontology that consists of very general terms that are common across all domains. An important function of an upper ontology is to support broad semantic interoperability among a large number of domain-specific ontologies by providing a common starting point for the formulation of definitions. Terms in the domain ontology are ranked under the terms in the upper ontology, e.g., the upper ontology classes are superclasses or supersets of all the classes in the domain ontologies.
Ontology alignment, or ontology matching, is the process of determining correspondences between concepts in ontologies. A set of correspondences is also called an alignment. The phrase takes on a slightly different meaning, in computer science, cognitive science or philosophy.
The ISO 15926 is a standard for data integration, sharing, exchange, and hand-over between computer systems.
Simple Knowledge Organization System (SKOS) is a W3C recommendation designed for representation of thesauri, classification schemes, taxonomies, subject-heading systems, or any other type of structured controlled vocabulary. SKOS is part of the Semantic Web family of standards built upon RDF and RDFS, and its main objective is to enable easy publication and use of such vocabularies as linked data.
Frames are an artificial intelligence data structure used to divide knowledge into substructures by representing "stereotyped situations".
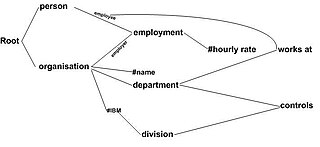
An ontology chart is a type of chart used in semiotics and software engineering to illustrate an ontology.
Domain-driven design (DDD) is a major software design approach, focusing on modeling software to match a domain according to input from that domain's experts. DDD is against the idea of having a single unified model; instead it divides a large system into bounded contexts, each of which have their own model.
Contemporary ontologies share many structural similarities, regardless of the ontology language in which they are expressed. Most ontologies describe individuals (instances), classes (concepts), attributes, and relations.
Knowledge extraction is the creation of knowledge from structured and unstructured sources. The resulting knowledge needs to be in a machine-readable and machine-interpretable format and must represent knowledge in a manner that facilitates inferencing. Although it is methodically similar to information extraction (NLP) and ETL, the main criterion is that the extraction result goes beyond the creation of structured information or the transformation into a relational schema. It requires either the reuse of existing formal knowledge or the generation of a schema based on the source data.
In information technology a reasoning system is a software system that generates conclusions from available knowledge using logical techniques such as deduction and induction. Reasoning systems play an important role in the implementation of artificial intelligence and knowledge-based systems.
A semantic triple, or RDF triple or simply triple, is the atomic data entity in the Resource Description Framework (RDF) data model. As its name indicates, a triple is a sequence of three entities that codifies a statement about semantic data in the form of subject–predicate–object expressions.

In knowledge representation and reasoning, a knowledge graph is a knowledge base that uses a graph-structured data model or topology to represent and operate on data. Knowledge graphs are often used to store interlinked descriptions of entities – objects, events, situations or abstract concepts – while also encoding the free-form semantics or relationships underlying these entities.