
In formal language theory, a context-free grammar (CFG) is a formal grammar whose production rules are of the form
In formal language theory, a context-free grammar, G, is said to be in Chomsky normal form if all of its production rules are of the form:

In the theory of computation, a branch of theoretical computer science, a pushdown automaton (PDA) is a type of automaton that employs a stack.
In computer science, an LL parser is a top-down parser for a subset of context-free languages. It parses the input from Left to right, performing Leftmost derivation of the sentence.
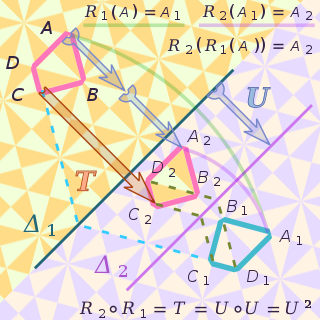
In mathematics, an isometry is a distance-preserving transformation between metric spaces, usually assumed to be bijective.
In physics, an operator is a function over a space of physical states onto another space of physical states. The simplest example of the utility of operators is the study of symmetry. Because of this, they are very useful tools in classical mechanics. Operators are even more important in quantum mechanics, where they form an intrinsic part of the formulation of the theory.
Tree-adjoining grammar (TAG) is a grammar formalism defined by Aravind Joshi. Tree-adjoining grammars are somewhat similar to context-free grammars, but the elementary unit of rewriting is the tree rather than the symbol. Whereas context-free grammars have rules for rewriting symbols as strings of other symbols, tree-adjoining grammars have rules for rewriting the nodes of trees as other trees.
A finite-state transducer (FST) is a finite-state machine with two memory tapes, following the terminology for Turing machines: an input tape and an output tape. This contrasts with an ordinary finite-state automaton, which has a single tape. An FST is a type of finite-state automaton (FSA) that maps between two sets of symbols. An FST is more general than an FSA. An FSA defines a formal language by defining a set of accepted strings, while an FST defines relations between sets of strings.
In mathematics, the Fréchet derivative is a derivative defined on normed spaces. Named after Maurice Fréchet, it is commonly used to generalize the derivative of a real-valued function of a single real variable to the case of a vector-valued function of multiple real variables, and to define the functional derivative used widely in the calculus of variations.
Interaction nets are a graphical model of computation devised by Yves Lafont in 1990 as a generalisation of the proof structures of linear logic. An interaction net system is specified by a set of agent types and a set of interaction rules. Interaction nets are an inherently distributed model of computation in the sense that computations can take place simultaneously in many parts of an interaction net, and no synchronisation is needed. The latter is guaranteed by the strong confluence property of reduction in this model of computation. Thus interaction nets provide a natural language for massive parallelism. Interaction nets are at the heart of many implementations of the lambda calculus, such as efficient closed reduction and optimal, in Lévy's sense, Lambdascope.
In computer science, in the area of formal language theory, frequent use is made of a variety of string functions; however, the notation used is different from that used for computer programming, and some commonly used functions in the theoretical realm are rarely used when programming. This article defines some of these basic terms.
Indexed grammars are a generalization of context-free grammars in that nonterminals are equipped with lists of flags, or index symbols. The language produced by an indexed grammar is called an indexed language.
An embedded pushdown automaton or EPDA is a computational model for parsing languages generated by tree-adjoining grammars (TAGs). It is similar to the context-free grammar-parsing pushdown automaton, but instead of using a plain stack to store symbols, it has a stack of iterated stacks that store symbols, giving TAGs a generative capacity between context-free and context-sensitive grammars, or a subset of mildly context-sensitive grammars. Embedded pushdown automata should not be confused with nested stack automata which have more computational power.
In formal language theory, a grammar describes how to form strings from a language's alphabet that are valid according to the language's syntax. A grammar does not describe the meaning of the strings or what can be done with them in whatever context—only their form. A formal grammar is defined as a set of production rules for strings in a formal language.
In computer science, more specifically in automata and formal language theory, nested words are a concept proposed by Alur and Madhusudan as a joint generalization of words, as traditionally used for modelling linearly ordered structures, and of ordered unranked trees, as traditionally used for modelling hierarchical structures. Finite-state acceptors for nested words, so-called nested word automata, then give a more expressive generalization of finite automata on words. The linear encodings of languages accepted by finite nested word automata gives the class of visibly pushdown languages. The latter language class lies properly between the regular languages and the deterministic context-free languages. Since their introduction in 2004, these concepts have triggered much research in that area.
In mathematical logic, a term denotes a mathematical object while a formula denotes a mathematical fact. In particular, terms appear as components of a formula. This is analogous to natural language, where a noun phrase refers to an object and a whole sentence refers to a fact.
Literal movement grammars (LMGs) are a grammar formalism introduced by Groenink in 1995 intended to characterize certain extraposition phenomena of natural language such as topicalization and cross-serial dependency. LMGs extend the class of context free grammars (CFGs) by adding introducing pattern-matched function-like rewrite semantics, as well as the operations of variable binding and slash deletion.
Range concatenation grammar (RCG) is a grammar formalism developed by Pierre Boullier in 1998 as an attempt to characterize a number of phenomena of natural language, such as Chinese numbers and German word order scrambling, which are outside the bounds of the Mildly context-sensitive languages.
Controlled grammars are a class of grammars that extend, usually, the context-free grammars with additional controls on the derivations of a sentence in the language. A number of different kinds of controlled grammars exist, the four main divisions being Indexed grammars, grammars with prescribed derivation sequences, grammars with contextual conditions on rule application, and grammars with parallelism in rule application. Because indexed grammars are so well established in the field, this article will address only the latter three kinds of controlled grammars.
In computational linguistics, the term mildly context-sensitive grammar formalisms refers to several grammar formalisms that have been developed in an effort to provide adequate descriptions of the syntactic structure of natural language.























