
In probability theory and statistics, the binomial distribution with parameters n and p is the discrete probability distribution of the number of successes in a sequence of n independent experiments, each asking a yes–no question, and each with its own Boolean-valued outcome: success or failure. A single success/failure experiment is also called a Bernoulli trial or Bernoulli experiment, and a sequence of outcomes is called a Bernoulli process; for a single trial, i.e., n = 1, the binomial distribution is a Bernoulli distribution. The binomial distribution is the basis for the popular binomial test of statistical significance.

In statistics, the standard deviation is a measure of the amount of variation of a random variable expected about its mean. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range. The standard deviation is commonly used in the determination of what constitutes an outlier and what does not.

In probability theory and statistics, skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean. The skewness value can be positive, zero, negative, or undefined.

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables, each of which clusters around a mean value.

In mathematics, the pigeonhole principle states that if n items are put into m containers, with n > m, then at least one container must contain more than one item. For example, of three gloves, at least two must be right-handed or at least two must be left-handed, because there are three objects but only two categories of handedness to put them into. This seemingly obvious statement, a type of counting argument, can be used to demonstrate possibly unexpected results. For example, given that the population of London is more than one unit greater than the maximum number of hairs that can be on a human's head, the principle requires that there must be at least two people in London who have the same number of hairs on their heads.
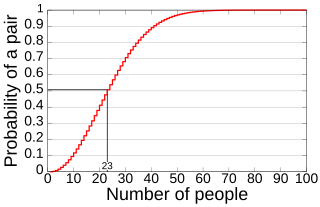
In probability theory, the birthday problem asks for the probability that, in a set of n randomly chosen people, at least two will share a birthday. The birthday paradox refers to the counterintuitive fact that only 23 people are needed for that probability to exceed 50%.

In number theory and combinatorics, a partition of a non-negative integer n, also called an integer partition, is a way of writing n as a sum of positive integers. Two sums that differ only in the order of their summands are considered the same partition. For example, 4 can be partitioned in five distinct ways:

In mathematics, the error function, often denoted by erf, is a function defined as:
The principle of maximum entropy states that the probability distribution which best represents the current state of knowledge about a system is the one with largest entropy, in the context of precisely stated prior data.

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.
In information theory, the asymptotic equipartition property (AEP) is a general property of the output samples of a stochastic source. It is fundamental to the concept of typical set used in theories of data compression.
In statistics, gambler's ruin is the fact that a gambler playing a game with negative expected value will eventually go broke, regardless of their betting system.
In probability theory, the multinomial distribution is a generalization of the binomial distribution. For example, it models the probability of counts for each side of a k-sided dice rolled n times. For n independent trials each of which leads to a success for exactly one of k categories, with each category having a given fixed success probability, the multinomial distribution gives the probability of any particular combination of numbers of successes for the various categories.

In mathematics, Monte Carlo integration is a technique for numerical integration using random numbers. It is a particular Monte Carlo method that numerically computes a definite integral. While other algorithms usually evaluate the integrand at a regular grid, Monte Carlo randomly chooses points at which the integrand is evaluated. This method is particularly useful for higher-dimensional integrals.
In information theory, the cross-entropy between two probability distributions and over the same underlying set of events measures the average number of bits needed to identify an event drawn from the set if a coding scheme used for the set is optimized for an estimated probability distribution , rather than the true distribution .

In probability theory and directional statistics, a wrapped normal distribution is a wrapped probability distribution that results from the "wrapping" of the normal distribution around the unit circle. It finds application in the theory of Brownian motion and is a solution to the heat equation for periodic boundary conditions. It is closely approximated by the von Mises distribution, which, due to its mathematical simplicity and tractability, is the most commonly used distribution in directional statistics.
In statistics, the generalized Marcum Q-function of order is defined as
Inverse probability weighting is a statistical technique for estimating quantities related to a population other than the one from which the data was collected. Study designs with a disparate sampling population and population of target inference are common in application. There may be prohibitive factors barring researchers from directly sampling from the target population such as cost, time, or ethical concerns. A solution to this problem is to use an alternate design strategy, e.g. stratified sampling. Weighting, when correctly applied, can potentially improve the efficiency and reduce the bias of unweighted estimators.
Maximal entropy random walk (MERW) is a popular type of biased random walk on a graph, in which transition probabilities are chosen accordingly to the principle of maximum entropy, which says that the probability distribution which best represents the current state of knowledge is the one with largest entropy. While standard random walk chooses for every vertex uniform probability distribution among its outgoing edges, locally maximizing entropy rate, MERW maximizes it globally by assuming uniform probability distribution among all paths in a given graph.
A Stein discrepancy is a statistical divergence between two probability measures that is rooted in Stein's method. It was first formulated as a tool to assess the quality of Markov chain Monte Carlo samplers, but has since been used in diverse settings in statistics, machine learning and computer science.










































