Related Research Articles
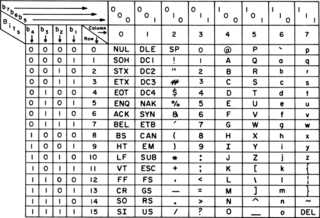
ASCII, abbreviated from American Standard Code for Information Interchange, is a character encoding standard for electronic communication. ASCII codes represent text in computers, telecommunications equipment, and other devices. Because of technical limitations of computer systems at the time it was invented, ASCII has just 128 code points, of which only 95 are printable characters, which severely limited its scope. Modern computer systems have evolved to use Unicode, which has millions of code points, but the first 128 of these are the same as the ASCII set.

The Baudot code is an early character encoding for telegraphy invented by Émile Baudot in the 1870s. It was the predecessor to the International Telegraph Alphabet No. 2 (ITA2), the most common teleprinter code in use before ASCII. Each character in the alphabet is represented by a series of five bits, sent over a communication channel such as a telegraph wire or a radio signal by asynchronous serial communication. The symbol rate measurement is known as baud, and is derived from the same name.

Character encoding is the process of assigning numbers to graphical characters, especially the written characters of human language, allowing them to be stored, transmitted, and transformed using digital computers. The numerical values that make up a character encoding are known as "code points" and collectively comprise a "code space", a "code page", or a "character map".
Extended Binary Coded Decimal Interchange Code is an eight-bit character encoding used mainly on IBM mainframe and IBM midrange computer operating systems. It descended from the code used with punched cards and the corresponding six-bit binary-coded decimal code used with most of IBM's computer peripherals of the late 1950s and early 1960s. It is supported by various non-IBM platforms, such as Fujitsu-Siemens' BS2000/OSD, OS-IV, MSP, and MSP-EX, the SDS Sigma series, Unisys VS/9, Unisys MCP and ICL VME.

In computing, plain text is a loose term for data that represent only characters of readable material but not its graphical representation nor other objects. It may also include a limited number of "whitespace" characters that affect simple arrangement of text, such as spaces, line breaks, or tabulation characters. Plain text is different from formatted text, where style information is included; from structured text, where structural parts of the document such as paragraphs, sections, and the like are identified; and from binary files in which some portions must be interpreted as binary objects.

In computer programming, a string is traditionally a sequence of characters, either as a literal constant or as some kind of variable. The latter may allow its elements to be mutated and the length changed, or it may be fixed. A string is generally considered as a data type and is often implemented as an array data structure of bytes that stores a sequence of elements, typically characters, using some character encoding. String may also denote more general arrays or other sequence data types and structures.
Unicode, formally The Unicode Standard, is a text encoding standard maintained by the Unicode Consortium designed to support the use of text written in all of the world's major writing systems. Version 15.1 of the standard defines 149813 characters and 161 scripts used in various ordinary, literary, academic, and technical contexts.
UTF-8 is a variable-length character encoding standard used for electronic communication. Defined by the Unicode Standard, the name is derived from Unicode Transformation Format – 8-bit.

UTF-16 (16-bit Unicode Transformation Format) is a character encoding capable of encoding all 1,112,064 valid code points of Unicode (in fact this number of code points is dictated by the design of UTF-16). The encoding is variable-length, as code points are encoded with one or two 16-bit code units. UTF-16 arose from an earlier obsolete fixed-width 16-bit encoding now known as UCS-2 (for 2-byte Universal Character Set), once it became clear that more than 216 (65,536) code points were needed, including most emoji and important CJK characters such as for personal and place names.
UTF-32 (32-bit Unicode Transformation Format) is a fixed-length encoding used to encode Unicode code points that uses exactly 32 bits (four bytes) per code point (but a number of leading bits must be zero as there are far fewer than 232 Unicode code points, needing actually only 21 bits). UTF-32 is a fixed-length encoding, in contrast to all other Unicode transformation formats, which are variable-length encodings. Each 32-bit value in UTF-32 represents one Unicode code point and is exactly equal to that code point's numerical value.
UTF-7 is an obsolete variable-length character encoding for representing Unicode text using a stream of ASCII characters. It was originally intended to provide a means of encoding Unicode text for use in Internet E-mail messages that was more efficient than the combination of UTF-8 with quoted-printable.
A telegraph code is one of the character encodings used to transmit information by telegraphy. Morse code is the best-known such code. Telegraphy usually refers to the electrical telegraph, but telegraph systems using the optical telegraph were in use before that. A code consists of a number of code points, each corresponding to a letter of the alphabet, a numeral, or some other character. In codes intended for machines rather than humans, code points for control characters, such as carriage return, are required to control the operation of the mechanism. Each code point is made up of a number of elements arranged in a unique way for that character. There are usually two types of element, but more element types were employed in some codes not intended for machines. For instance, American Morse code had about five elements, rather than the two of International Morse Code.
A wide character is a computer character datatype that generally has a size greater than the traditional 8-bit character. The increased datatype size allows for the use of larger coded character sets.
A variable-width encoding is a type of character encoding scheme in which codes of differing lengths are used to encode a character set for representation, usually in a computer. Most common variable-width encodings are multibyte encodings, which use varying numbers of bytes (octets) to encode different characters. (Some authors, notably in Microsoft documentation, use the term multibyte character set, which is a misnomer, because representation size is an attribute of the encoding, not of the character set.)
This article compares Unicode encodings. Two situations are considered: 8-bit-clean environments, and environments that forbid use of byte values that have the high bit set. Originally such prohibitions were to allow for links that used only seven data bits, but they remain in some standards and so some standard-conforming software must generate messages that comply with the restrictions. Standard Compression Scheme for Unicode and Binary Ordered Compression for Unicode are excluded from the comparison tables because it is difficult to simply quantify their size.
UTF-1 is a method of transforming ISO/IEC 10646/Unicode into a stream of bytes. Its design does not provide self-synchronization, which makes searching for substrings and error recovery difficult. It reuses the ASCII printing characters for multi-byte encodings, making it unsuited for some uses. UTF-1 is also slow to encode or decode due to its use of division and multiplication by a number which is not a power of 2. Due to these issues, it did not gain acceptance and was quickly replaced by UTF-8.
Braille ASCII is a subset of the ASCII character set which uses 64 of the printable ASCII characters to represent all possible dot combinations in six-dot braille. It was developed around 1969 and, despite originally being known as North American Braille ASCII, it is now used internationally.
A six-bit character code is a character encoding designed for use on computers with word lengths a multiple of 6. Six bits can only encode 64 distinct characters, so these codes generally include only the upper-case letters, the numerals, some punctuation characters, and sometimes control characters. The 7-track magnetic tape format was developed to store data in such codes, along with an additional parity bit.
The Universal Coded Character Set is a standard set of characters defined by the international standard ISO/IEC 10646, Information technology — Universal Coded Character Set (UCS), which is the basis of many character encodings, improving as characters from previously unrepresented typing systems are added.
In mobile telephony GSM 03.38 or 3GPP 23.038 is a character encoding used in GSM networks for SMS, CB and USSD. The 3GPP TS 23.038 standard defines GSM 7-bit default alphabet which is mandatory for GSM handsets and network elements, but the character set is suitable only for English and a number of Western-European languages. Languages such as Chinese, Korean or Japanese must be transferred using the 16-bit UCS-2 character encoding. A limited number of languages, like Portuguese, Spanish, Turkish and a number of languages used in India written with a Brahmic scripts may use 7-bit encoding with national language shift table defined in 3GPP 23.038. For binary messages, 8-bit encoding is used.
References
- 1 2 Alan G. Hobbs (1999-03-05). "Five-unit codes". NADCOMM Museum. Archived from the original on 1999-11-04.
- 1 2 Gil Smith (2001). "Teletypewriter Communication Codes" (PDF).
- ↑ "Paper Tape Readers & Punches". The Ferranti Orion Web Site. Archived from the original on 2011-07-21.
- 1 2 3 4 "Telecipher Devices". John Savard's Home Page.