
Bioinformatics is an interdisciplinary field of science that develops methods and software tools for understanding biological data, especially when the data sets are large and complex. Bioinformatics uses biology, chemistry, physics, computer science, computer programming, information engineering, mathematics and statistics to analyze and interpret biological data. The subsequent process of analyzing and interpreting data is referred to as computational biology.

Protein secondary structure is the local spatial conformation of the polypeptide backbone excluding the side chains. The two most common secondary structural elements are alpha helices and beta sheets, though beta turns and omega loops occur as well. Secondary structure elements typically spontaneously form as an intermediate before the protein folds into its three dimensional tertiary structure.

Protein structure prediction is the inference of the three-dimensional structure of a protein from its amino acid sequence—that is, the prediction of its secondary and tertiary structure from primary structure. Structure prediction is different from the inverse problem of protein design. Protein structure prediction is one of the most important goals pursued by computational biology; it is important in medicine and biotechnology.

Structural bioinformatics is the branch of bioinformatics that is related to the analysis and prediction of the three-dimensional structure of biological macromolecules such as proteins, RNA, and DNA. It deals with generalizations about macromolecular 3D structures such as comparisons of overall folds and local motifs, principles of molecular folding, evolution, binding interactions, and structure/function relationships, working both from experimentally solved structures and from computational models. The term structural has the same meaning as in structural biology, and structural bioinformatics can be seen as a part of computational structural biology. The main objective of structural bioinformatics is the creation of new methods of analysing and manipulating biological macromolecular data in order to solve problems in biology and generate new knowledge.
In molecular biology, protein threading, also known as fold recognition, is a method of protein modeling which is used to model those proteins which have the same fold as proteins of known structures, but do not have homologous proteins with known structure. It differs from the homology modeling method of structure prediction as it is used for proteins which do not have their homologous protein structures deposited in the Protein Data Bank (PDB), whereas homology modeling is used for those proteins which do. Threading works by using statistical knowledge of the relationship between the structures deposited in the PDB and the sequence of the protein which one wishes to model.
Internal Coordinate Mechanics (ICM) is a software program and algorithm to predict low-energy conformations of molecules by sampling the space of internal coordinates defining molecular geometry. In ICM each molecule is constructed as a tree from an entry atom where each next atom is built iteratively from the preceding three atoms via three internal variables. The rings kept rigid or imposed via additional restraints. ICM is used for modelling peptides and interactions with substrates and coenzymes.

Biomolecular structure is the intricate folded, three-dimensional shape that is formed by a molecule of protein, DNA, or RNA, and that is important to its function. The structure of these molecules may be considered at any of several length scales ranging from the level of individual atoms to the relationships among entire protein subunits. This useful distinction among scales is often expressed as a decomposition of molecular structure into four levels: primary, secondary, tertiary, and quaternary. The scaffold for this multiscale organization of the molecule arises at the secondary level, where the fundamental structural elements are the molecule's various hydrogen bonds. This leads to several recognizable domains of protein structure and nucleic acid structure, including such secondary-structure features as alpha helixes and beta sheets for proteins, and hairpin loops, bulges, and internal loops for nucleic acids. The terms primary, secondary, tertiary, and quaternary structure were introduced by Kaj Ulrik Linderstrøm-Lang in his 1951 Lane Medical Lectures at Stanford University.
Nucleic acid structure prediction is a computational method to determine secondary and tertiary nucleic acid structure from its sequence. Secondary structure can be predicted from one or several nucleic acid sequences. Tertiary structure can be predicted from the sequence, or by comparative modeling.
Protein–ligand docking is a molecular modelling technique. The goal of protein–ligand docking is to predict the position and orientation of a ligand when it is bound to a protein receptor or enzyme. Pharmaceutical research employs docking techniques for a variety of purposes, most notably in the virtual screening of large databases of available chemicals in order to select likely drug candidates. There has been rapid development in computational ability to determine protein structure with programs such as AlphaFold, and the demand for the corresponding protein-ligand docking predictions is driving implementation of software that can find accurate models. Once the protein folding can be predicted accurately along with how the ligands of various structures will bind to the protein, the ability for drug development to progress at a much faster rate becomes possible.
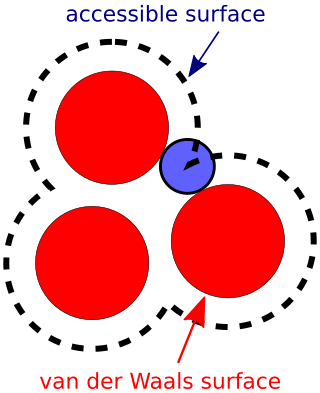
The accessible surface area (ASA) or solvent-accessible surface area (SASA) is the surface area of a biomolecule that is accessible to a solvent. Measurement of ASA is usually described in units of square angstroms. ASA was first described by Lee & Richards in 1971 and is sometimes called the Lee-Richards molecular surface. ASA is typically calculated using the 'rolling ball' algorithm developed by Shrake & Rupley in 1973. This algorithm uses a sphere of a particular radius to 'probe' the surface of the molecule.
In computational biology, de novo protein structure prediction refers to an algorithmic process by which protein tertiary structure is predicted from its amino acid primary sequence. The problem itself has occupied leading scientists for decades while still remaining unsolved. According to Science, the problem remains one of the top 125 outstanding issues in modern science. At present, some of the most successful methods have a reasonable probability of predicting the folds of small, single-domain proteins within 1.5 angstroms over the entire structure.
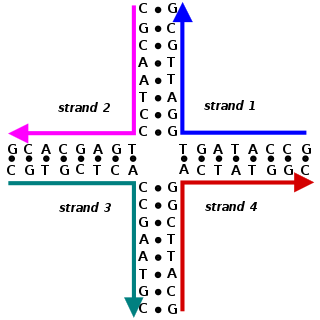
Nucleic acid design is the process of generating a set of nucleic acid base sequences that will associate into a desired conformation. Nucleic acid design is central to the fields of DNA nanotechnology and DNA computing. It is necessary because there are many possible sequences of nucleic acid strands that will fold into a given secondary structure, but many of these sequences will have undesired additional interactions which must be avoided. In addition, there are many tertiary structure considerations which affect the choice of a secondary structure for a given design.
This is a list of notable computer programs that are used for nucleic acids simulations.

Nucleic acid secondary structure is the basepairing interactions within a single nucleic acid polymer or between two polymers. It can be represented as a list of bases which are paired in a nucleic acid molecule. The secondary structures of biological DNAs and RNAs tend to be different: biological DNA mostly exists as fully base paired double helices, while biological RNA is single stranded and often forms complex and intricate base-pairing interactions due to its increased ability to form hydrogen bonds stemming from the extra hydroxyl group in the ribose sugar.
Phyre and Phyre2 are free web-based services for protein structure prediction. Phyre is among the most popular methods for protein structure prediction having been cited over 1500 times. Like other remote homology recognition techniques, it is able to regularly generate reliable protein models when other widely used methods such as PSI-BLAST cannot. Phyre2 has been designed to ensure a user-friendly interface for users inexpert in protein structure prediction methods. Its development is funded by the Biotechnology and Biological Sciences Research Council.
RaptorX is a software and web server for protein structure and function prediction that is free for non-commercial use. RaptorX is among the most popular methods for protein structure prediction. Like other remote homology recognition/protein threading techniques, RaptorX is able to regularly generate reliable protein models when the widely used PSI-BLAST cannot. However, RaptorX is also significantly different from those profile-based methods in that RaptorX excels at modeling of protein sequences without a large number of sequence homologs by exploiting structure information. RaptorX Server has been designed to ensure a user-friendly interface for users inexpert in protein structure prediction methods.
Discovery Studio is a suite of software for simulating small molecule and macromolecule systems. It is developed and distributed by Dassault Systemes BIOVIA.
PSI-blast based secondary structure PREDiction (PSIPRED) is a method used to investigate protein structure. It uses artificial neural network machine learning methods in its algorithm. It is a server-side program, featuring a website serving as a front-end interface, which can predict a protein's secondary structure from the primary sequence.
LeDock is a molecular docking software, designed for protein-ligand interactions, that is compatible with Linux, macOS, and Windows.
