Related Research Articles

In speech science and phonetics, a formant is the broad spectral maximum that results from an acoustic resonance of the human vocal tract. In acoustics, a formant is usually defined as a broad peak, or local maximum, in the spectrum. For harmonic sounds, with this definition, the formant frequency is sometimes taken as that of the harmonic that is most augmented by a resonance. The difference between these two definitions resides in whether "formants" characterise the production mechanisms of a sound or the produced sound itself. In practice, the frequency of a spectral peak differs slightly from the associated resonance frequency, except when, by luck, harmonics are aligned with the resonance frequency, or when the sound source is mostly non-harmonic, as in whispering and vocal fry.
Time stretching is the process of changing the speed or duration of an audio signal without affecting its pitch. Pitch scaling is the opposite: the process of changing the pitch without affecting the speed. Pitch shift is pitch scaling implemented in an effects unit and intended for live performance. Pitch control is a simpler process which affects pitch and speed simultaneously by slowing down or speeding up a recording.

In Fourier analysis, the cepstrum is the result of computing the inverse Fourier transform (IFT) of the logarithm of the estimated signal spectrum. The method is a tool for investigating periodic structures in frequency spectra. The power cepstrum has applications in the analysis of human speech.

In music, timbre, also known as tone color or tone quality, is the perceived sound quality of a musical note, sound or tone. Timbre distinguishes different types of sound production, such as choir voices and musical instruments. It also enables listeners to distinguish different instruments in the same category.

Pitch is a perceptual property that allows sounds to be ordered on a frequency-related scale, or more commonly, pitch is the quality that makes it possible to judge sounds as "higher" and "lower" in the sense associated with musical melodies. Pitch is a major auditory attribute of musical tones, along with duration, loudness, and timbre.
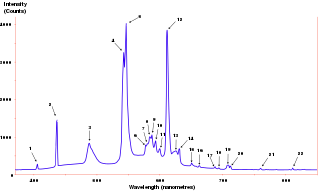
In signal processing, the power spectrum of a continuous time signal describes the distribution of power into frequency components composing that signal. According to Fourier analysis, any physical signal can be decomposed into a number of discrete frequencies, or a spectrum of frequencies over a continuous range. The statistical average of any sort of signal as analyzed in terms of its frequency content, is called its spectrum.

The pitch being perceived with the first harmonic being absent in the waveform is called the missing fundamental phenomenon.

A spectrum analyzer measures the magnitude of an input signal versus frequency within the full frequency range of the instrument. The primary use is to measure the power of the spectrum of known and unknown signals. The input signal that most common spectrum analyzers measure is electrical; however, spectral compositions of other signals, such as acoustic pressure waves and optical light waves, can be considered through the use of an appropriate transducer. Spectrum analyzers for other types of signals also exist, such as optical spectrum analyzers which use direct optical techniques such as a monochromator to make measurements.
Harmonic Vector Excitation Coding, abbreviated as HVXC is a speech coding algorithm specified in MPEG-4 Part 3 standard for very low bit rate speech coding. HVXC supports bit rates of 2 and 4 kbit/s in the fixed and variable bit rate mode and sampling frequency of 8 kHz. It also operates at lower bitrates, such as 1.2 - 1.7 kbit/s, using a variable bit rate technique. The total algorithmic delay for the encoder and decoder is 36 ms.

In music, transcription is the practice of notating a piece or a sound which was previously unnotated and/or unpopular as a written music, for example, a jazz improvisation or a video game soundtrack. When a musician is tasked with creating sheet music from a recording and they write down the notes that make up the piece in music notation, it is said that they created a musical transcription of that recording. Transcription may also mean rewriting a piece of music, either solo or ensemble, for another instrument or other instruments than which it was originally intended. The Beethoven Symphonies transcribed for solo piano by Franz Liszt are an example. Transcription in this sense is sometimes called arrangement, although strictly speaking transcriptions are faithful adaptations, whereas arrangements change significant aspects of the original piece.
Bandwidth extension of signal is defined as the deliberate process of expanding the frequency range (bandwidth) of a signal in which it contains an appreciable and useful content, and/or the frequency range in which its effects are such. Its significant advancement in recent years has led to the technology being adopted commercially in several areas including psychacoustic bass enhancement of small loudspeakers and the high frequency enhancement of coded speech and audio.
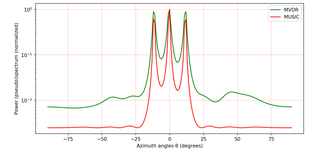
MUSIC is an algorithm used for frequency estimation and radio direction finding.
Computational auditory scene analysis (CASA) is the study of auditory scene analysis by computational means. In essence, CASA systems are "machine listening" systems that aim to separate mixtures of sound sources in the same way that human listeners do. CASA differs from the field of blind signal separation in that it is based on the mechanisms of the human auditory system, and thus uses no more than two microphone recordings of an acoustic environment. It is related to the cocktail party problem.
In statistical signal processing, the goal of spectral density estimation (SDE) or simply spectral estimation is to estimate the spectral density of a signal from a sequence of time samples of the signal. Intuitively speaking, the spectral density characterizes the frequency content of the signal. One purpose of estimating the spectral density is to detect any periodicities in the data, by observing peaks at the frequencies corresponding to these periodicities.

Least-squares spectral analysis (LSSA) is a method of estimating a frequency spectrum based on a least-squares fit of sinusoids to data samples, similar to Fourier analysis. Fourier analysis, the most used spectral method in science, generally boosts long-periodic noise in the long and gapped records; LSSA mitigates such problems. Unlike in Fourier analysis, data need not be equally spaced to use LSSA.
Harmonic pitch class profiles (HPCP) is a group of features that a computer program extracts from an audio signal, based on a pitch class profile—a descriptor proposed in the context of a chord recognition system. HPCP are an enhanced pitch distribution feature that are sequences of feature vectors that, to a certain extent, describe tonality, measuring the relative intensity of each of the 12 pitch classes of the equal-tempered scale within an analysis frame. Often, the twelve pitch spelling attributes are also referred to as chroma and the HPCP features are closely related to what is called chroma features or chromagrams.

Audio forensics is the field of forensic science relating to the acquisition, analysis, and evaluation of sound recordings that may ultimately be presented as admissible evidence in a court of law or some other official venue.
The Blackman–Tukey transformation is a digital signal processing method to transform data from the time domain to the frequency domain. It was originally programmed around 1953 by James Cooley for John Tukey at John von Neumann's Institute for Advanced Study as a way to get "good smoothed statistical estimates of power spectra without requiring large Fourier transforms." It was published by Ralph Beebe Blackman and John Tukey in 1958.
Multidimension spectral estimation is a generalization of spectral estimation, normally formulated for one-dimensional signals, to multidimensional signals or multivariate data, such as wave vectors.
Ernst Terhardt is a German engineer and psychoacoustician who made significant contributions in diverse areas of audio communication including pitch perception, music cognition, and Fourier transformation. He was professor in the area of acoustic communication at the Institute of Electroacoustics, Technical University of Munich, Germany.
References
- ↑ D. Gerhard. Pitch Extraction and Fundamental Frequency: History and Current Techniques, technical report, Dept. of Computer Science, University of Regina, 2003.
- ↑ de Cheveigné, Alain; Kawahara, Hideki (2002). "YIN, a fundamental frequency estimator for speech and music" (PDF). The Journal of the Acoustical Society of America. 111 (4). Acoustical Society of America (ASA): 1917–1930. Bibcode:2002ASAJ..111.1917D. doi:10.1121/1.1458024. ISSN 0001-4966. PMID 12002874. S2CID 1607434.
- ↑ P. McLeod and G. Wyvill. A smarter way to find pitch. In Proceedings of the International Computer Music Conference (ICMC’05), 2005.
- ↑ Hayes, Monson (1996). Statistical Digital Signal Processing and Modeling. John Wiley & Sons, Inc. p. 393. ISBN 0-471-59431-8.
- ↑ Pitch Detection Algorithms, online resource from Connexions
- ↑ A. Michael Noll, “Pitch Determination of Human Speech by the Harmonic Product Spectrum, the Harmonic Sum Spectrum and a Maximum Likelihood Estimate,” Proceedings of the Symposium on Computer Processing in Communications, Vol. XIX, Polytechnic Press: Brooklyn, New York, (1970), pp. 779–797.
- ↑ A. Michael Noll, “Cepstrum Pitch Determination,” Journal of the Acoustical Society of America, Vol. 41, No. 2, (February 1967), pp. 293–309.
- ↑ Mitre, Adriano; Queiroz, Marcelo; Faria, Régis. Accurate and Efficient Fundamental Frequency Determination from Precise Partial Estimates. Proceedings of the 4th AES Brazil Conference. 113-118, 2006.
- ↑ Brown JC and Puckette MS (1993). A high resolution fundamental frequency determination based on phase changes of the Fourier transform. J. Acoust. Soc. Am. Volume 94, Issue 2, pp. 662–667
- ↑ Zahorian, Stephen A.; Hu, Hongbing (2008). "A spectral/temporal method for robust fundamental frequency tracking" (PDF). The Journal of the Acoustical Society of America. 123 (6). Acoustical Society of America (ASA): 4559–4571. Bibcode:2008ASAJ..123.4559Z. doi:10.1121/1.2916590. ISSN 0001-4966. PMID 18537404.
- ↑ Stephen A. Zahorian and Hongbing Hu. YAAPT Pitch Tracking MATLAB Function
- 1 2 Huang, Xuedong; Alex Acero; Hsiao-Wuen Hon (2001). Spoken Language Processing. Prentice Hall PTR. p. 325. ISBN 0-13-022616-5.