Related Research Articles

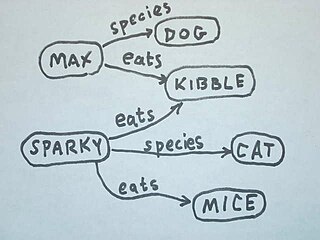
A semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map.
The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable.

A conceptual graph (CG) is a formalism for knowledge representation. In the first published paper on CGs, John F. Sowa used them to represent the conceptual schemas used in database systems. The first book on CGs applied them to a wide range of topics in artificial intelligence, computer science, and cognitive science.
A federated database system is a type of meta-database management system (DBMS), which transparently maps multiple autonomous database systems into a single federated database. The constituent databases are interconnected via a computer network and may be geographically decentralized. Since the constituent database systems remain autonomous, a federated database system is a contrastable alternative to the task of merging several disparate databases. A federated database, or virtual database, is a composite of all constituent databases in a federated database system. There is no actual data integration in the constituent disparate databases as a result of data federation.
Semantic integration is the process of interrelating information from diverse sources, for example calendars and to do lists, email archives, presence information, documents of all sorts, contacts, search results, and advertising and marketing relevance derived from them. In this regard, semantics focuses on the organization of and action upon information by acting as an intermediary between heterogeneous data sources, which may conflict not only by structure but also context or value.
The ultimate goal of semantic technology is to help machines understand data. To enable the encoding of semantics with the data, well-known technologies are RDF and OWL. These technologies formally represent the meaning involved in information. For example, ontology can describe concepts, relationships between things, and categories of things. These embedded semantics with the data offer significant advantages such as reasoning over data and dealing with heterogeneous data sources.
Ontology alignment, or ontology matching, is the process of determining correspondences between concepts in ontologies. A set of correspondences is also called an alignment. The phrase takes on a slightly different meaning, in computer science, cognitive science or philosophy.
Data integration involves combining data residing in different sources and providing users with a unified view of them. This process becomes significant in a variety of situations, which include both commercial and scientific domains. Data integration appears with increasing frequency as the volume and the need to share existing data explodes. It has become the focus of extensive theoretical work, and numerous open problems remain unsolved. Data integration encourages collaboration between internal as well as external users. The data being integrated must be received from a heterogeneous database system and transformed to a single coherent data store that provides synchronous data across a network of files for clients. A common use of data integration is in data mining when analyzing and extracting information from existing databases that can be useful for Business information.
Oracle Spatial and Graph, formerly Oracle Spatial, is a free option component of the Oracle Database. The spatial features in Oracle Spatial and Graph aid users in managing geographic and location-data in a native type within an Oracle database, potentially supporting a wide range of applications — from automated mapping, facilities management, and geographic information systems (AM/FM/GIS), to wireless location services and location-enabled e-business. The graph features in Oracle Spatial and Graph include Oracle Network Data Model (NDM) graphs used in traditional network applications in major transportation, telcos, utilities and energy organizations and RDF semantic graphs used in social networks and social interactions and in linking disparate data sets to address requirements from the research, health sciences, finance, media and intelligence communities.
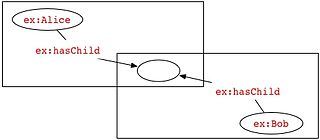
In RDF, a blank node is a node in an RDF graph representing a resource for which a URI or literal is not given. The resource represented by a blank node is also called an anonymous resource. According to the RDF standard a blank node can only be used as subject or object of an RDF triple.
Ontology-based data integration involves the use of one or more ontology to effectively combine data or information from multiple heterogeneous sources. It is one of the multiple data integration approaches and may be classified as Global-As-View (GAV). The effectiveness of ontology‑based data integration is closely tied to the consistency and expressivity of the ontology used in the integration process.
The terms schema matching and mapping are often used interchangeably for a database process. For this article, we differentiate the two as follows: Schema matching is the process of identifying that two objects are semantically related while mapping refers to the transformations between the objects. For example, in the two schemas DB1.Student and DB2.Grad-Student ; possible matches would be: DB1.Student ≈ DB2.Grad-Student; DB1.SSN = DB2.ID etc. and possible transformations or mappings would be: DB1.Marks to DB2.Grades.
Minimal mappings are the result of an advanced technique of semantic matching, a technique used in computer science to identify information which is semantically related.
A lightweight ontology is an ontology or knowledge organization system in which concepts are connected by rather general associations than strict formal connections. Examples of lightweight ontologies include associative network and multilingual classifications but the term is not used consistently.
In computing, a graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly and, in many cases, retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships is fast because they are perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them useful for heavily inter-connected data.
DSSim is an ontology mapping system, that has been conceived to achieve a certain level of the envisioned machine intelligence on the Semantic Web. The main driving factors behind its development was to provide an alternative to the existing heuristics or machine learning based approaches with a multi-agent approach that makes use of uncertain reasoning. The system provides a possible approach to establish machine understanding over Semantic Web data through multi-agent beliefs and conflict resolution.

In information science a conceptualization is an abstract simplified view of some selected part of the world, containing the objects, concepts, and other entities that are presumed of interest for some particular purpose and the relationships between them. An explicit specification of a conceptualization is an ontology, and it may occur that a conceptualization can be realized by several distinct ontologies. An ontological commitment in describing ontological comparisons is taken to refer to that subset of elements of an ontology shared with all the others. "An ontology is language-dependent", its objects and interrelations described within the language it uses, while a conceptualization is always the same, more general, its concepts existing "independently of the language used to describe it". The relation between these terms is shown in the figure to the right.
Semantic queries allow for queries and analytics of associative and contextual nature. Semantic queries enable the retrieval of both explicitly and implicitly derived information based on syntactic, semantic and structural information contained in data. They are designed to deliver precise results or to answer more fuzzy and wide open questions through pattern matching and digital reasoning.

UMBEL is a logically organized knowledge graph of 34,000 concepts and entity types that can be used in information science for relating information from disparate sources to one another. It was retired at the end of 2019. UMBEL was first released in July 2008. Version 1.00 was released in February 2011. Its current release is version 1.50.
In knowledge representation and reasoning, knowledge graph is a knowledge base that uses a graph-structured data model or topology to integrate data. Knowledge graphs are often used to store interlinked descriptions of entities – objects, events, situations or abstract concepts – with free-form semantics.
References
- ↑ Pavel Shvaiko; J´erˆome Euzenat. "A Survey of Schema-based Matching Approaches" (PDF). Dit.unitn.it. Retrieved 21 December 2018.
- ↑ Fausto Giunchiglia; Pavel Shvaiko; Mikalai Yatskevich. "S-MATCH: AN ALGORITHM AND AN IMPLEMENTATION OF SEMANTIC MATCHING" (PDF). Eprints.biblio.unitn.it. Retrieved 21 December 2018.
- ↑ Fausto Giunchiglia; Maurizio Marchese; Ilya Zaihrayeu. "ENCODING CLASSIFICATIONS AS LIGHTWEIGHT ONTOLOGIES" (PDF). Eprints.biblio.unitn.it. Retrieved 21 December 2018.
- ↑ Hasan, Souleiman, Sean O'Riain, and Edward Curry. 2012. "Approximate Semantic Matching of Heterogeneous Events." In 6th ACM International Conference on Distributed Event-Based Systems (DEBS 2012), 252–263. Berlin, Germany: ACM. "DOI".