Related Research Articles

The Sinhala script, also known as Sinhalese script, is a writing system used by the Sinhalese people and most Sri Lankans in Sri Lanka and elsewhere to write the Sinhala language as well as the liturgical languages Pali and Sanskrit. The Sinhalese Akṣara Mālāva, one of the Brahmic scripts, is a descendant of the Ancient Indian Brahmi script. It ultimately descended from the Grantha script.

The Tamil script is an abugida script that is used by Tamils and Tamil speakers in India, Sri Lanka, Malaysia, Singapore, Indonesia and elsewhere to write the Tamil language. It is one of the official scripts of the Indian Republic. Certain minority languages such as Saurashtra, Badaga, Irula and Paniya are also written in the Tamil script.
Indian Standard Code for Information Interchange (ISCII) is a coding scheme for representing various writing systems of India. It encodes the main Indic scripts and a Roman transliteration. The supported scripts are: Bengali–Assamese, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. ISCII does not encode the writing systems of India that are based on Persian, but its writing system switching codes nonetheless provide for Kashmiri, Sindhi, Urdu, Persian, Pashto and Arabic. The Persian-based writing systems were subsequently encoded in the PASCII encoding.
Sinhala may refer to:
Sinhala language software for computers have been present since the late 1980s but no standard character representation system was put in place which resulted in proprietary character representation systems and fonts. In the wake of this CINTEC introduced Sinhala within the UNICODE standard. ICTA concluded the work started by CINTEC for approving and standardizing Sinhala Unicode in Sri Lanka.
The rupee sign "₨" is a currency sign used to represent the monetary unit of account in Pakistan, Sri Lanka, Nepal, Mauritius, Seychelles, and formerly in India. It resembles, and is often written as, the Latin character sequence "Rs", of which it is an orthographic ligature.
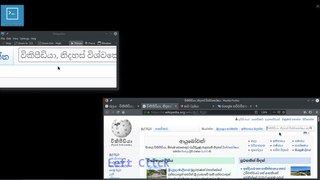
Sinhala input methods are ways of writing the Sinhala language, spoken primarily in Sri Lanka, using a computer. Sinhala input methods can be broadly classified into two main groups: ones based on typewriter keyboard layouts, and ones that are meant to be typed on QWERTY keyboards using an input method, known as "Singlish".
Devanagari is a Unicode block containing characters for writing languages such as Hindi, Marathi, Bodo, Maithili, Sindhi, Nepali, and Sanskrit, among others. In its original incarnation, the code points U+0900..U+0954 were a direct copy of the characters A0-F4 from the 1988 ISCII standard. The Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Bengali Unicode block contains characters for the Bengali, Assamese, Bishnupriya Manipuri, Daphla, Garo, Hallam, Khasi, Mizo, Munda, Naga, Riang, and Santali languages. In its original incarnation, the code points U+0981..U+09CD were a direct copy of the Bengali characters A1-ED from the 1988 ISCII standard, as well as several Assamese ISCII characters in the U+09F0 column. The Devanagari, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, Kannada, and Malayalam blocks were similarly all based on ISCII encodings.
Gurmukhi is a Unicode block containing characters for the Punjabi language, in the Gurmukhi script. In its original incarnation, the code points U+0A02..U+0A4C were a direct copy of the Gurmukhi characters A2-EC from the 1988 ISCII standard. The Devanagari, Bengali, Gujarati, Oriya, Tamil, Telugu, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Gujarati is a Unicode block containing characters for writing the Gujarati language. In its original incarnation, the code points U+0A81..U+0AD0 were a direct copy of the Gujarati characters A1-F0 from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Oriya, Tamil, Telugu, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Oriya is a Unicode block containing characters for the Odia, Khondi and Santali languages of the state of Odisha in India. In its original incarnation, the code points U+0B01..U+0B4D were a direct copy of the Odia characters A1-ED from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Gujarati, Tamil, Telugu, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Tamil is a Unicode block containing characters for the Tamil, and Saurashtra languages of Tamil Nadu India, Sri Lanka, Singapore, and Malaysia. In its original incarnation, the code points U+0B82..U+0BCD were a direct copy of the Tamil characters A2-ED from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Telugu, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Telugu is a Unicode block containing characters for the Telugu, Gondi, and Lambadi languages of Indian states of Andhra Pradesh and Telangana. In its original incarnation, the code points U+0C01..U+0C4D were a direct copy of the Telugu characters A1-ED from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Kannada, and Malayalam blocks were similarly all based on their ISCII encodings.
Kannada is a Unicode block containing characters for the Kannada, Sanskrit, Konkani, Sankethi, Havyaka, Tulu and Kodava languages. In its original incarnation, the code points U+0C82..U+0CCD were a direct copy of the Kannada characters A2-ED from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, and Malayalam blocks were similarly all based on their ISCII encodings.
Malayalam is a Unicode block containing characters of the Malayalam script. In its original incarnation, the code points U+0D02..U+0D4D were a direct copy of the Malayalam characters A2-ED from the 1988 ISCII standard. The Devanagari, Bengali, Gurmukhi, Gujarati, Oriya, Tamil, Telugu, and Kannada blocks were similarly all based on their ISCII encodings.
Tibetan is a Unicode block containing characters for the Tibetan, Dzongkha, and other languages of China, Bhutan, Nepal, Mongolia, northern India, eastern Pakistan and Russia.
Tamil All Character Encoding (TACE16) is a scheme for encoding the Tamil script in the Private Use Area of Unicode, implementing a syllabary-based character model differing from the modified-ISCII model used by Unicode's existing Tamil implementation.
Sinhala Archaic Numbers is a Unicode block containing Sinhala Illakkam number characters.
Cherokee Supplement is a Unicode block containing the syllabic characters for writing the Cherokee language. When Cherokee was first added to Unicode in version 3.0 it was treated as a unicameral alphabet, but in version 8.0 it was redefined as a bicameral script. The Cherokee Supplement block contains lowercase letters only, whereas the Cherokee block contains all the uppercase letters, together with six lowercase letters. For backwards compatibility, the Unicode case folding algorithm—which usually converts a string to lowercase characters—maps Cherokee characters to uppercase.
References
- ↑ "Unicode character database". The Unicode Standard. Retrieved 2023-07-26.
- ↑ "Enumerated Versions of The Unicode Standard". The Unicode Standard. Retrieved 2023-07-26.
| Stages |  | ||||
|---|---|---|---|---|---|
| Dialects | |||||
| Academic | |||||
| Sinhala and other languages |
| ||||
| Writing system | |||||
| Computerization | |||||
| Grammar and vocabulary | |||||
| Phonology | |||||
| Events | |||||