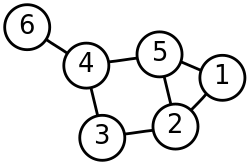
Given an enumerated set of data points, the similarity matrix may be defined as a symmetric matrix, where represents a measure of the similarity between data points with indices and . The general approach to spectral clustering is to use a standard clustering method (there are many such methods, k-means is discussed below) on relevant eigenvectors of a Laplacian matrix of . There are many different ways to define a Laplacian which have different mathematical interpretations, and so the clustering will also have different interpretations. The eigenvectors that are relevant are the ones that correspond to several smallest eigenvalues of the Laplacian except for the smallest eigenvalue which will have a value of 0. For computational efficiency, these eigenvectors are often computed as the eigenvectors corresponding to the largest several eigenvalues of a function of the Laplacian.
Spectral clustering is well known to relate to partitioning of a mass-spring system, where each mass is associated with a data point and each spring stiffness corresponds to a weight of an edge describing a similarity of the two related data points, as in the spring system. Specifically, the classical reference [1] explains that the eigenvalue problem describing transversal vibration modes of a mass-spring system is exactly the same as the eigenvalue problem for the graph Laplacian matrix defined as
The masses that are tightly connected by the springs in the mass-spring system evidently move together from the equilibrium position in low-frequency vibration modes, so that the components of the eigenvectors corresponding to the smallest eigenvalues of the graph Laplacian can be used for meaningful clustering of the masses. For example, assuming that all the springs and the masses are identical in the 2-dimensional spring system pictured, one would intuitively expect that the loosest connected masses on the right-hand side of the system would move with the largest amplitude and in the opposite direction to the rest of the masses when the system is shaken — and this expectation will be confirmed by analyzing components of the eigenvectors of the graph Laplacian corresponding to the smallest eigenvalues, i.e., the smallest vibration frequencies.
The goal of normalization is making the diagonal entries of the Laplacian matrix to be all unit, also scaling off-diagonal entries correspondingly. In a weighted graph, a vertex may have a large degree because of a small number of connected edges but with large weights just as well as due to a large number of connected edges with unit weights.
Knowing the -by- matrix of selected eigenvectors, mapping — called spectral embedding — of the original data points is performed to a -dimensional vector space using the rows of . Now the analysis is reduced to clustering vectors with components, which may be done in various ways.
In the simplest case , the selected single eigenvector , called the Fiedler vector, corresponds to the second smallest eigenvalue. Using the components of one can place all points whose component in is positive in the set and the rest in , thus bi-partitioning the graph and labeling the data points with two labels. This sign-based approach follows the intuitive explanation of spectral clustering via the mass-spring model — in the low frequency vibration mode that the Fiedler vector represents, one cluster data points identified with mutually strongly connected masses would move together in one direction, while in the complement cluster data points identified with remaining masses would move together in the opposite direction. The algorithm can be used for hierarchical clustering by repeatedly partitioning the subsets in the same fashion.
In the general case , any vector clustering technique can be used, e.g., DBSCAN.
Algorithms
Basic Algorithm
Calculate the Laplacian (or the normalized Laplacian)
Calculate the first eigenvectors (the eigenvectors corresponding to the smallest eigenvalues of )
Consider the matrix formed by the first eigenvectors; the -th row defines the features of graph node
Cluster the graph nodes based on these features (e.g., using k-means clustering)
If the similarity matrix has not already been explicitly constructed, the efficiency of spectral clustering may be improved if the solution to the corresponding eigenvalue problem is performed in a matrix-free fashion (without explicitly manipulating or even computing the similarity matrix), as in the Lanczos algorithm.
For large-sized graphs, the second eigenvalue of the (normalized) graph Laplacian matrix is often ill-conditioned, leading to slow convergence of iterative eigenvalue solvers. Preconditioning is a key technology accelerating the convergence, e.g., in the matrix-free LOBPCG method. Spectral clustering has been successfully applied on large graphs by first identifying their community structure, and then clustering communities.[4]
Spectral clustering is closely related to nonlinear dimensionality reduction, and dimension reduction techniques such as locally-linear embedding can be used to reduce errors from noise or outliers.[5]
Costs
Denoting the number of the data points by , it is important to estimate the memory footprint and compute time, or number of arithmetic operations (AO) performed, as a function of . No matter the algorithm of the spectral clustering, the two main costly items are the construction of the graph Laplacian and determining its eigenvectors for the spectral embedding. The last step — determining the labels from the -by- matrix of eigenvectors — is typically the least expensive requiring only AO and creating just a -by- vector of the labels in memory.
The need to construct the graph Laplacian is common for all distance- or correlation-based clustering methods. Computing the eigenvectors is specific to spectral clustering only.
Constructing graph Laplacian
The graph Laplacian can be and commonly is constructed from the adjacency matrix. The construction can be performed matrix-free, i.e., without explicitly forming the matrix of the graph Laplacian and no AO. It can also be performed in-place of the adjacency matrix without increasing the memory footprint. Either way, the costs of constructing the graph Laplacian is essentially determined by the costs of constructing the -by- graph adjacency matrix.
Moreover, a normalized Laplacian has exactly the same eigenvectors as the normalized adjacency matrix, but with the order of the eigenvalues reversed. Thus, instead of computing the eigenvectors corresponding to the smallest eigenvalues of the normalized Laplacian, one can equivalently compute the eigenvectors corresponding to the largest eigenvalues of the normalized adjacency matrix, without even talking about the Laplacian matrix.
Naive constructions of the graph adjacency matrix, e.g., using the RBF kernel, make it dense, thus requiring memory and AO to determine each of the entries of the matrix. Nystrom method[6] can be used to approximate the similarity matrix, but the approximate matrix is not elementwise positive,[7] i.e. cannot be interpreted as a distance-based similarity.
Algorithms to construct the graph adjacency matrix as a sparse matrix are typically based on a nearest neighbor search, which estimate or sample a neighborhood of a given data point for nearest neighbors, and compute non-zero entries of the adjacency matrix by comparing only pairs of the neighbors. The number of the selected nearest neighbors thus determines the number of non-zero entries, and is often fixed so that the memory footprint of the -by- graph adjacency matrix is only , only sequential arithmetic operations are needed to compute the non-zero entries, and the calculations can be trivially run in parallel.
Computing eigenvectors
The cost of computing the -by- (with ) matrix of selected eigenvectors of the graph Laplacian is normally proportional to the cost of multiplication of the -by- graph Laplacian matrix by a vector, which varies greatly whether the graph Laplacian matrix is dense or sparse. For the dense case the cost thus is . The very commonly cited in the literature cost comes from choosing and is clearly misleading, since, e.g., in a hierarchical spectral clustering as determined by the Fiedler vector.
In the sparse case of the -by- graph Laplacian matrix with non-zero entries, the cost of the matrix-vector product and thus of computing the -by- with matrix of selected eigenvectors is , with the memory footprint also only — both are the optimal low bounds of complexity of clustering data points. Moreover, matrix-free eigenvalue solvers such as LOBPCG can efficiently run in parallel, e.g., on multiple GPUs with distributed memory, resulting not only in high quality clusters, which spectral clustering is famous for, but also top performance.[8]
The ideas behind spectral clustering may not be immediately obvious. It may be useful to highlight relationships with other methods. In particular, it can be described in the context of kernel clustering methods, which reveals several similarities with other approaches.[15]
Relationship with k-means
Spectral clustering is closely related to the k-means algorithm, especially in how cluster assignments are ultimately made. Although the two methods differ fundamentally in their initial formulations—spectral clustering being graph-based and k-means being centroid-based—the connection becomes clear when spectral clustering is viewed through the lens of kernel methods.
In particular, weighted kernel k-means provides a key theoretical bridge between the two. Kernel k-means is a generalization of the standard k-means algorithm, where data is implicitly mapped into a high-dimensional feature space through a kernel function, and clustering is performed in that space. Spectral clustering, especially the normalized versions, performs a similar operation by mapping the input data (or graph nodes) to a lower-dimensional space defined by the eigenvectors of the graph Laplacian. These eigenvectors correspond to the solution of a relaxation of the normalized cut or other graph partitioning objectives.
Mathematically, the objective function minimized by spectral clustering can be shown to be equivalent to the objective function of weighted kernel k-means in this transformed space. This was formally established in works such as [16] where they demonstrated that normalized cuts are equivalent to a weighted version of kernel k-means applied to the rows of the normalized Laplacian’s eigenvector matrix.
Because of this equivalence, spectral clustering can be viewed as performing kernel k-means in the eigenspace defined by the graph Laplacian. This theoretical insight has practical implications: the final clustering step in spectral clustering typically involves running the standard k-means algorithm on the rows of the matrix formed by the first k eigenvectors of the Laplacian. These rows can be thought of as embedding each data point or node in a low-dimensional space where the clusters are more well-separated and hence, easier for k-means to detect.
Additionally, multi-level methods have been developed to directly optimize this shared objective function. These methods work by iteratively coarsening the graph to reduce problem size, solving the problem on a coarse graph, and then refining the solution on successively finer graphs. This leads to more efficient optimization for large-scale problems, while still capturing the global structure preserved by the spectral embedding.[17]
Relationship to DBSCAN
Spectral clustering is also conceptually related to DBSCAN (Density-Based Spatial Clustering of Applications with Noise), particularly in the special case where the spectral method is used to identify connected graph components of a graph. In this trivial case—where the goal is to identify subsets of nodes with no interconnecting edges between them—the spectral method effectively reduces to a connectivity-based clustering approach, much like DBSCAN.[18]
DBSCAN operates by identifying density-connected regions in the input space: points that are reachable from one another via a sequence of neighboring points within a specified radius (ε), and containing a minimum number of points (minPts). The algorithm excels at discovering clusters of arbitrary shape and separating out noise without needing to specify the number of clusters in advance.
In spectral clustering, when the similarity graph is constructed using a hard connectivity criterion (i.e., binary adjacency based on whether two nodes are within a threshold distance), and no normalization is applied to the Laplacian, the resulting eigenstructure of the graph Laplacian directly reveals disconnected components of the graph. This mirrors DBSCAN's ability to isolate density-connected components. The zeroth eigenvectors of the unnormalized Laplacian correspond to these components, with one eigenvector per connected region.
This connection is most apparent when spectral clustering is used not to optimize a soft partition (like minimizing the normalized cut), but to identify exact connected components—which corresponds to the most extreme form of “density-based” clustering, where only directly or transitively connected nodes are grouped together. Therefore, spectral clustering in this regime behaves like a spectral version of DBSCAN, especially in sparse graphs or when constructing ε-neighborhood graphs.
While DBSCAN operates directly in the data space using density estimates, spectral clustering transforms the data into an eigenspace where global structure and connectivity are emphasized. Both methods are non-parametric in spirit, and neither assumes convex cluster shapes, which further supports their conceptual alignment.
Measures to compare clusterings
Ravi Kannan, Santosh Vempala and Adrian Vetta[19] proposed a bicriteria measure to define the quality of a given clustering. They said that a clustering was an (α, ε)-clustering if the conductance of each cluster (in the clustering) was at least α and the weight of the inter-cluster edges was at most ε fraction of the total weight of all the edges in the graph. They also look at two approximation algorithms in the same paper.
Ideas and network measures related to spectral clustering also play an important role in a number of applications apparently different from clustering problems. For instance, networks with stronger spectral partitions take longer to converge in opinion-updating models used in sociology and economics.[26][27]
↑Arias-Castro, E.; Chen, G.; Lerman, G. (2011), "Spectral clustering based on local linear approximations.", Electronic Journal of Statistics, 5: 1537–87, arXiv:1001.1323, doi:10.1214/11-ejs651, S2CID88518155
↑Kannan, Ravi; Vempala, Santosh; Vetta, Adrian (2004). "On Clusterings: Good, Bad and Spectral". Journal of the ACM. 51 (3): 497–515. doi:10.1145/990308.990313. S2CID207558562.
↑Cheeger, Jeff (1969). "A lower bound for the smallest eigenvalue of the Laplacian". Proceedings of the Princeton Conference in Honor of Professor S. Bochner.
↑Donath, William; Hoffman, Alan (1972). "Algorithms for partitioning of graphs and computer logic based on eigenvectors of connections matrices". IBM Technical Disclosure Bulletin.
↑Guattery, Stephen; Miller, Gary L. (1995). "On the performance of spectral graph partitioning methods". Annual ACM-SIAM Symposium on Discrete Algorithms.
↑Daniel A. Spielman and Shang-Hua Teng (1996). "Spectral Partitioning Works: Planar graphs and finite element meshes". Annual IEEE Symposium on Foundations of Computer Science.
↑Golub, Benjamin; Jackson, Matthew O. (2012-07-26). "How Homophily Affects the Speed of Learning and Best-Response Dynamics". The Quarterly Journal of Economics. 127 (3). Oxford University Press (OUP): 1287–1338. doi:10.1093/qje/qjs021. ISSN0033-5533.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.