The Laplacian matrix is the easiest to define for a simple graph but more common in applications for an edge-weighted graph, i.e., with weights on its edges — the entries of the graph adjacency matrix. Spectral graph theory relates properties of a graph to a spectrum, i.e., eigenvalues and eigenvectors of matrices associated with the graph, such as its adjacency matrix or Laplacian matrix. Imbalanced weights may undesirably affect the matrix spectrum, leading to the need of normalization — a column/row scaling of the matrix entries — resulting in normalized adjacency and Laplacian matrices.
Definitions for simple graphs
Laplacian matrix
Given a simple graph with vertices , its Laplacian matrix is defined element-wise as[1]
or equivalently by the matrix
where D is the degree matrix, and A is the graph's adjacency matrix. Since is a simple graph, only contains 1s or 0s and its diagonal elements are all 0s.
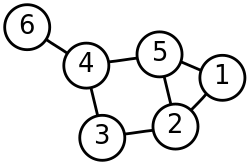
Here is a simple example of a labelled, undirected graph and its Laplacian matrix.
We observe for the undirected graph that both the adjacency matrix and the Laplacian matrix are symmetric and that the row- and column-sums of the Laplacian matrix are all zeros (which directly implies that the Laplacian matrix is singular).
In the directed graph, the adjacency matrix and Laplacian matrix are asymmetric. In its Laplacian matrix, column-sums or row-sums are zero, depending on whether the indegree or outdegree has been used.
Laplacian matrix for an undirected graph via the oriented incidence matrix
The oriented incidence matrixB with element Bve for the vertex v and the edge e (connecting vertices and , with i≠j) is defined by
Even though the edges in this definition are technically directed, their directions can be arbitrary, still resulting in the same symmetric Laplacian matrix L defined as
An alternative product defines the so-called edge-based Laplacian, as opposed to the original commonly used vertex-based Laplacian matrix L.
Symmetric Laplacian for a directed graph
The Laplacian matrix of a directed graph is by definition generally non-symmetric, while, e.g., traditional spectral clustering is primarily developed for undirected graphs with symmetric adjacency and Laplacian matrices. A trivial approach to applying techniques requiring the symmetry is to turn the original directed graph into an undirected graph and build the Laplacian matrix for the latter.
In the matrix notation, the adjacency matrix of the undirected graph could, e.g., be defined as a Boolean sum of the adjacency matrix of the original directed graph and its matrix transpose, where the zero and one entries of are treated as logical, rather than numerical, values, as in the following example:
A vertex with a large degree, also called a heavy node, results in a large diagonal entry in the Laplacian matrix dominating the matrix properties. Normalization is aimed to make the influence of such vertices more equal to that of other vertices, by dividing the entries of the Laplacian matrix by the vertex degrees. To avoid division by zero, isolated vertices with zero degrees are excluded from the process of the normalization.
Symmetrically normalized Laplacian
The symmetrically normalized Laplacian matrix is defined as:[1]
Similarly, the right normalized Laplacian matrix is defined as
.
The left or right normalized Laplacian matrix is symmetric if the adjacency matrix is symmetric and the graph is regular. Otherwise, the left or right normalized Laplacian matrix is asymmetric. For example,
The example also demonstrates that if has no isolated vertices, then right stochastic and hence is the matrix of a random walk, so that the left normalized Laplacian has each row summing to zero. Thus we sometimes alternatively call the random-walk normalized Laplacian. In the less uncommonly used right normalized Laplacian each column sums to zero since is left stochastic.
For a non-symmetric adjacency matrix of a directed graph, one also needs to choose indegree or outdegree for normalization:
The left out-degree normalized Laplacian with row-sums all 0 relates to right stochastic , while the right in-degree normalized Laplacian with column-sums all 0 contains left stochastic.
Definitions for graphs with weighted edges
Common in applications graphs with weighted edges are conveniently defined by their adjacency matrices where values of the entries are numeric and no longer limited to zeros and ones. In spectral clustering and graph-based signal processing, where graph vertices represent data points, the edge weights can be computed, e.g., as inversely proportional to the distances between pairs of data points, leading to all weights being non-negative with larger values informally corresponding to more similar pairs of data points. Using correlation and anti-correlation between the data points naturally leads to both positive and negative weights. Most definitions for simple graphs are trivially extended to the standard case of non-negative weights, while negative weights require more attention, especially in normalization.
Graph self-loops, manifesting themselves by non-zero entries on the main diagonal of the adjacency matrix, are allowed but do not affect the graph Laplacian values.
Symmetric Laplacian via the incidence matrix
A 2-dimensional spring system.
For graphs with weighted edges one can define a weighted incidence matrix B and use it to construct the corresponding symmetric Laplacian as . An alternative cleaner approach, described here, is to separate the weights from the connectivity: continue using the incidence matrix as for regular graphs and introduce a matrix just holding the values of the weights. A spring system is an example of this model used in mechanics to describe a system of springs of given stiffnesses and unit length, where the values of the stiffnesses play the role of the weights of the graph edges.
We thus reuse the definition of the weightless incidence matrixB with element Bve for the vertex v and the edge e (connecting vertexes and , with i>j) defined by
We now also define a diagonal matrix W containing the edge weights. Even though the edges in the definition of B are technically directed, their directions can be arbitrary, still resulting in the same symmetric Laplacian matrix L defined as
Just like for simple graphs, the Laplacian matrix of a directed weighted graph is by definition generally non-symmetric. The symmetry can be enforced by turning the original directed graph into an undirected graph first before constructing the Laplacian. The adjacency matrix of the undirected graph could, e.g., be defined as a sum of the adjacency matrix of the original directed graph and its matrix transpose as in the following example:
where the zero and one entries of are treated as numerical, rather than logical as for simple graphs, values, explaining the difference in the results - for simple graphs, the symmetrized graph still needs to be simple with its symmetrized adjacency matrix having only logical, not numerical values, e.g., the logical sum is 1 v 1 = 1, while the numeric sum is 1 + 1 = 2.
Alternatively, the symmetric Laplacian matrix can be calculated from the two Laplacians using the indegree and outdegree, as in the following example:
The sum of the out-degree Laplacian transposed and the in-degree Laplacian equals to the symmetric Laplacian matrix.
Laplacian matrix normalization
The goal of normalization is, like for simple graphs, to make the diagonal entries of the Laplacian matrix to be all unit, also scaling off-diagonal entries correspondingly. In a weighted graph, a vertex may have a large degree because of a small number of connected edges but with large weights just as well as due to a large number of connected edges with unit weights.
Graph self-loops, i.e., non-zero entries on the main diagonal of the adjacency matrix, do not affect the graph Laplacian values, but may need to be counted for calculation of the normalization factors.
Symmetrically normalized Laplacian
The symmetrically normalized Laplacian is defined as
where L is the unnormalized Laplacian, A is the adjacency matrix, D is the degree matrix, and is the Moore–Penrose inverse. Since the degree matrix D is diagonal, its reciprocal square root is just the diagonal matrix whose diagonal entries are the reciprocals of the square roots of the diagonal entries of D. If all the edge weights are nonnegative then all the degree values are automatically also nonnegative and so every degree value has a unique positive square root. To avoid the division by zero, vertices with zero degrees are excluded from the process of the normalization, as in the following example:
The symmetrically normalized Laplacian is a symmetric matrix if and only if the adjacency matrix A is symmetric and the diagonal entries of D are nonnegative, in which case we can use the term the symmetric normalized Laplacian.
The symmetric normalized Laplacian matrix can be also written as
using the weightless incidence matrixB and the diagonal matrix W containing the edge weights and defining the new weighted incidence matrix whose rows are indexed by the vertices and whose columns are indexed by the edges of G such that each column corresponding to an edge e = {u, v} has an entry in the row corresponding to u, an entry in the row corresponding to v, and has 0 entries elsewhere.
Random walk normalized Laplacian
The random walk normalized Laplacian is defined as
where D is the degree matrix. Since the degree matrix D is diagonal, its inverse is simply defined as a diagonal matrix, having diagonal entries which are the reciprocals of the corresponding diagonal entries of D. For the isolated vertices (those with degree 0), a common choice is to set the corresponding element to 0. The matrix elements of are given by
The name of the random-walk normalized Laplacian comes from the fact that this matrix is , where is simply the transition matrix of a random walker on the graph, assuming non-negative weights. For example, let denote the i-th standard basis vector. Then is a probability vector representing the distribution of a random walker's locations after taking a single step from vertex ; i.e., . More generally, if the vector is a probability distribution of the location of a random walker on the vertices of the graph, then is the probability distribution of the walker after steps.
The random walk normalized Laplacian can also be called the left normalized Laplacian since the normalization is performed by multiplying the Laplacian by the normalization matrix on the left. It has each row summing to zero since is right stochastic, assuming all the weights are non-negative.
In the less uncommonly used right normalized Laplacian each column sums to zero since is left stochastic.
For a non-symmetric adjacency matrix of a directed graph, one also needs to choose indegree or outdegree for normalization:
The left out-degree normalized Laplacian with row-sums all 0 relates to right stochastic , while the right in-degree normalized Laplacian with column-sums all 0 contains left stochastic.
Negative weights
Negative weights present several challenges for normalization:
The presence of negative weights may naturally result in zero row- and/or column-sums for non-isolated vertices. A vertex with a large row-sum of positive weights and equally negatively large row-sum of negative weights, together summing up to zero, could be considered a heavy node and both large values scaled, while the diagonal entry remains zero, like for an isolated vertex.
Negative weights may also give negative row- and/or column-sums, so that the corresponding diagonal entry in the non-normalized Laplacian matrix would be negative and a positive square root needed for the symmetric normalization would not exist.
Arguments can be made to take the absolute value of the row- and/or column-sums for the purpose of normalization, thus treating a possible value -1 as a legitimate unit entry of the main diagonal of the normalized Laplacian matrix.
Properties
For an (undirected) graph G and its Laplacian matrix L with eigenvalues:
The Laplacian is an operator on the n-dimensional vector space of functions , where is the vertex set of G, and .
When G is k-regular, the normalized Laplacian is: , where A is the adjacency matrix and I is an identity matrix.
For a graph with multiple connected components, L is a block diagonal matrix, where each block is the respective Laplacian matrix for each component, possibly after reordering the vertices (i.e. L is permutation-similar to a block diagonal matrix).
The trace of the Laplacian matrix L is equal to where is the number of edges of the considered graph.
Now consider an eigendecomposition of , with unit-norm eigenvectors and corresponding eigenvalues :
Because can be written as the inner product of the vector with itself, this shows that and so the eigenvalues of are all non-negative.
All eigenvalues of the normalized symmetric Laplacian satisfy 0 = μ0 ≤ … ≤ μn−1 ≤ 2. These eigenvalues (known as the spectrum of the normalized Laplacian) relate well to other graph invariants for general graphs.[1]
One can check that:
,
i.e., is similar to the normalized Laplacian . For this reason, even if is in general not symmetric, it has real eigenvalues — exactly the same as the eigenvalues of the normalized symmetric Laplacian .
Interpretation as the discrete Laplace operator approximating the continuous Laplacian
The graph Laplacian matrix can be further viewed as a matrix form of the negative discrete Laplace operator on a graph approximating the negative continuous Laplacian operator obtained by the finite difference method. (See Discrete Poisson equation)[2] In this interpretation, every graph vertex is treated as a grid point; the local connectivity of the vertex determines the finite difference approximation stencil at this grid point, the grid size is always one for every edge, and there are no constraints on any grid points, which corresponds to the case of the homogeneous Neumann boundary condition, i.e., free boundary. Such an interpretation allows one, e.g., generalizing the Laplacian matrix to the case of graphs with an infinite number of vertices and edges, leading to a Laplacian matrix of an infinite size.
Generalizations and extensions of the Laplacian matrix
Notice the ordinary Laplacian is a generalized Laplacian.
Admittance matrix of an AC circuit
The Laplacian of a graph was first introduced to model electrical networks. In an alternating current (AC) electrical network, real-valued resistances are replaced by complex-valued impedances. The weight of edge (i, j) is, by convention, minus the reciprocal of the impedance directly between i and j. In models of such networks, the entries of the adjacency matrix are complex, but the Kirchhoff matrix remains symmetric, rather than being Hermitian. Such a matrix is usually called an "admittance matrix", denoted , rather than a "Laplacian". This is one of the rare applications that give rise to complex symmetric matrices.
There are other situations in which entries of the adjacency matrix are complex-valued, and the Laplacian does become a Hermitian matrix. The Magnetic Laplacian for a directed graph with real weights is constructed as the Hadamard product of the real symmetric matrix of the symmetrized Laplacian and the Hermitian phase matrix with the complex entries
which encode the edge direction into the phase in the complex plane. In the context of quantum physics, the magnetic Laplacian can be interpreted as the operator that describes the phenomenology of a free charged particle on a graph, which is subject to the action of a magnetic field and the parameter is called electric charge.[4] In the following example :
where I is the identity matrix, A is the adjacency matrix, D is the degree matrix, and s is a (complex-valued) number. [5] The standard Laplacian is just and is the signless Laplacian.
Signless Laplacian
The signless Laplacian is defined as
where is the degree matrix, and is the adjacency matrix.[6] Like the signed Laplacian , the signless Laplacian also is positive semi-definite as it can be factored as
where is the incidence matrix. has a 0-eigenvector if and only if it has a bipartite connected component (isolated vertices being bipartite connected components). This can be shown as
This has a solution where if and only if the graph has a bipartite connected component.
Directed multigraphs
An analogue of the Laplacian matrix can be defined for directed multigraphs.[7] In this case the Laplacian matrix L is defined as
where D is a diagonal matrix with Di,i equal to the outdegree of vertex i and A is a matrix with Ai,j equal to the number of edges from i to j (including loops).
↑ Smola, Alexander J.; Kondor, Risi (2003), "Kernels and regularization on graphs", Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24–27, 2003, Proceedings, Lecture Notes in Computer Science, vol.2777, Springer, pp.144–158, CiteSeerX10.1.1.3.7020, doi:10.1007/978-3-540-45167-9_12, ISBN978-3-540-40720-1 .
↑ Godsil, C.; Royle, G. (2001). Algebraic Graph Theory, Graduate Texts in Mathematics. Springer-Verlag.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.