Examples
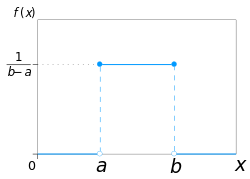
One of the simplest examples of a discrete univariate distribution is the discrete uniform distribution, where all elements of a finite set are equally likely. It is the probability model for the outcomes of tossing a fair coin, rolling a fair die, etc. The univariate continuous uniform distribution on an interval [a, b] has the property that all sub-intervals of the same length are equally likely.

Other examples of discrete univariate distributions include the binomial, geometric, negative binomial, and Poisson distributions. [1] At least 750 univariate discrete distributions have been reported in the literature. [2]
Examples of commonly applied continuous univariate distributions [3] include the normal distribution, Student's t distribution, chisquare distribution, F distribution, exponential and gamma distributions.