
An alpha helix is a sequence of amino acids in a protein that are twisted into a coil.
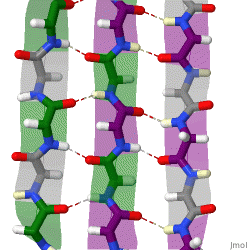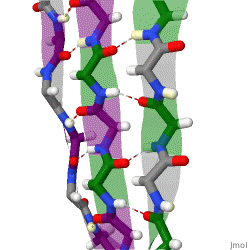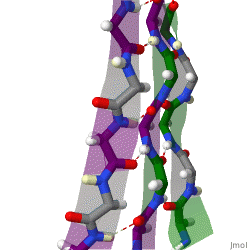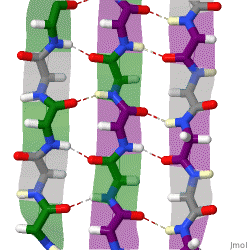
The beta sheet is a common motif of the regular protein secondary structure. Beta sheets consist of beta strands (β-strands) connected laterally by at least two or three backbone hydrogen bonds, forming a generally twisted, pleated sheet. A β-strand is a stretch of polypeptide chain typically 3 to 10 amino acids long with backbone in an extended conformation. The supramolecular association of β-sheets has been implicated in the formation of the fibrils and protein aggregates observed in amyloidosis, Alzheimer's disease and other proteinopathies.
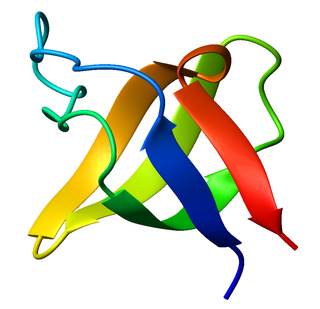
The SRC Homology 3 Domain is a small protein domain of about 60 amino acid residues. Initially, SH3 was described as a conserved sequence in the viral adaptor protein v-Crk. This domain is also present in the molecules of phospholipase and several cytoplasmic tyrosine kinases such as Abl and Src. It has also been identified in several other protein families such as: PI3 Kinase, Ras GTPase-activating protein, CDC24 and cdc25. SH3 domains are found in proteins of signaling pathways regulating the cytoskeleton, the Ras protein, and the Src kinase and many others. The SH3 proteins interact with adaptor proteins and tyrosine kinases. Interacting with tyrosine kinases, SH3 proteins usually bind far away from the active site. Approximately 300 SH3 domains are found in proteins encoded in the human genome. In addition to that, the SH3 domain was responsible for controlling protein-protein interactions in the signal transduction pathways and regulating the interactions of proteins involved in the cytoplasmic signaling.
Proline (symbol Pro or P) is an organic acid classed as a proteinogenic amino acid (used in the biosynthesis of proteins), although it does not contain the amino group -NH
2 but is rather a secondary amine. The secondary amine nitrogen is in the protonated form (NH2+) under biological conditions, while the carboxyl group is in the deprotonated −COO− form. The "side chain" from the α carbon connects to the nitrogen forming a pyrrolidine loop, classifying it as a aliphatic amino acid. It is non-essential in humans, meaning the body can synthesize it from the non-essential amino acid L-glutamate. It is encoded by all the codons starting with CC (CCU, CCC, CCA, and CCG).

Protein structure prediction is the inference of the three-dimensional structure of a protein from its amino acid sequence—that is, the prediction of its secondary and tertiary structure from primary structure. Structure prediction is different from the inverse problem of protein design. Protein structure prediction is one of the most important goals pursued by computational biology; it is important in medicine and biotechnology.

Protein structure is the three-dimensional arrangement of atoms in an amino acid-chain molecule. Proteins are polymers – specifically polypeptides – formed from sequences of amino acids, which are the monomers of the polymer. A single amino acid monomer may also be called a residue, which indicates a repeating unit of a polymer. Proteins form by amino acids undergoing condensation reactions, in which the amino acids lose one water molecule per reaction in order to attach to one another with a peptide bond. By convention, a chain under 30 amino acids is often identified as a peptide, rather than a protein. To be able to perform their biological function, proteins fold into one or more specific spatial conformations driven by a number of non-covalent interactions, such as hydrogen bonding, ionic interactions, Van der Waals forces, and hydrophobic packing. To understand the functions of proteins at a molecular level, it is often necessary to determine their three-dimensional structure. This is the topic of the scientific field of structural biology, which employs techniques such as X-ray crystallography, NMR spectroscopy, cryo-electron microscopy (cryo-EM) and dual polarisation interferometry, to determine the structure of proteins.
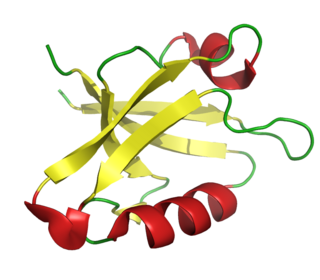
The PDZ domain is a common structural domain of 80-90 amino-acids found in the signaling proteins of bacteria, yeast, plants, viruses and animals. Proteins containing PDZ domains play a key role in anchoring receptor proteins in the membrane to cytoskeletal components. Proteins with these domains help hold together and organize signaling complexes at cellular membranes. These domains play a key role in the formation and function of signal transduction complexes. PDZ domains also play a highly significant role in the anchoring of cell surface receptors to the actin cytoskeleton via mediators like NHERF and ezrin.

The beta hairpin is a simple protein structural motif involving two beta strands that look like a hairpin. The motif consists of two strands that are adjacent in primary structure, oriented in an antiparallel direction, and linked by a short loop of two to five amino acids. Beta hairpins can occur in isolation or as part of a series of hydrogen bonded strands that collectively comprise a beta sheet.

Dystroglycan is a protein that in humans is encoded by the DAG1 gene.

Eukaryotic translation termination factor1 (eRF1), also referred to as TB3-1 or SUP45L1, is a protein that is encoded by the ERF1 gene. In Eukaryotes, eRF1 is an essential protein involved in stop codon recognition in translation, termination of translation, and nonsense mediated mRNA decay via the SURF complex.

Glypican-3 is a protein that, in humans, is encoded by the GPC3 gene. The GPC3 gene is located on human X chromosome (Xq26) where the most common gene encodes a 70-kDa core protein with 580 amino acids. Three variants have been detected that encode alternatively spliced forms termed Isoforms 1 (NP_001158089), Isoform 3 (NP_001158090) and Isoform 4 (NP_001158091).

YAP1, also known as YAP or YAP65, is a protein that acts as a transcription coregulator that promotes transcription of genes involved in cellular proliferation and suppressing apoptotic genes. YAP1 is a component in the hippo signaling pathway which regulates organ size, regeneration, and tumorigenesis. YAP1 was first identified by virtue of its ability to associate with the SH3 domain of Yes and Src protein tyrosine kinases. YAP1 is a potent oncogene, which is amplified in various human cancers.
Polyglutamine-binding protein 1 (PQBP1) is a protein that in humans is encoded by the PQBP1 gene.

WW domain-containing adapter protein with coiled-coil is a protein that in humans is encoded by the WAC gene.

WW domain-binding protein 2 is a protein that in humans is encoded by the WBP2 gene.

WW domain-binding protein 1 is a protein that in humans is encoded by the WBP1 gene.

WW domain-containing transcription regulator protein 1 (WWTR1), also known as Transcriptional coactivator with PDZ-binding motif (TAZ), is a protein that in humans is encoded by the WWTR1 gene. WWTR1 acts as a transcriptional coregulator and has no effect on transcription alone. When in complex with transcription factor binding partners, WWTR1 helps promote gene expression in pathways associated with development, cell growth and survival, and inhibiting apoptosis. Aberrant WWTR1 function has been implicated for its role in driving cancers. WWTR1 is often referred to as TAZ due to its initial characterization with the name TAZ. However, WWTR1 (TAZ) is not to be confused with the protein tafazzin, which originally held the official gene symbol TAZ, and is now TAFAZZIN.

In molecular biology short linear motifs (SLiMs), linear motifs or minimotifs are short stretches of protein sequence that mediate protein–protein interaction.
WH1 domain is an evolutionary conserved protein domain found on WASP proteins, which are often involved in actin polymerization.
In epigenetics, proline isomerization is the effect that cis-trans isomerization of the amino acid proline has on the regulation of gene expression. Similar to aspartic acid, the amino acid proline has the rare property of being able to occupy both cis and trans isomers of its prolyl peptide bonds with ease. Peptidyl-prolyl isomerase, or PPIase, is an enzyme very commonly associated with proline isomerization due to their ability to catalyze the isomerization of prolines. PPIases are present in three types: cyclophilins, FK507-binding proteins, and the parvulins. PPIase enzymes catalyze the transition of proline between cis and trans isomers and are essential to the numerous biological functions controlled and affected by prolyl isomerization Without PPIases, prolyl peptide bonds will slowly switch between cis and trans isomers, a process that can lock proteins in a nonnative structure that can affect render the protein temporarily ineffective. Although this switch can occur on its own, PPIases are responsible for most isomerization of prolyl peptide bonds. The specific amino acid that precedes the prolyl peptide bond also can have an effect on which conformation the bond assumes. For instance, when an aromatic amino acid is bonded to a proline the bond is more favorable to the cis conformation. Cyclophilin A uses an "electrostatic handle" to pull proline into cis and trans formations. Most of these biological functions are affected by the isomerization of proline when one isomer interacts differently than the other, commonly causing an activation/deactivation relationship. As an amino acid, proline is present in many proteins. This aids in the multitude of effects that isomerization of proline can have in different biological mechanisms and functions.
