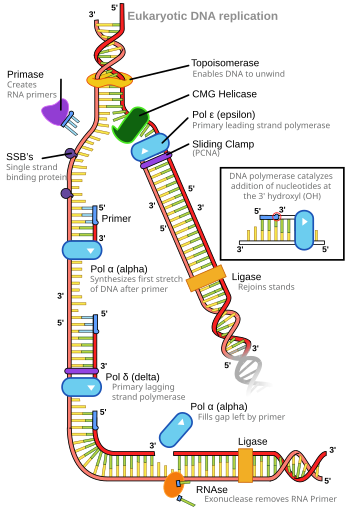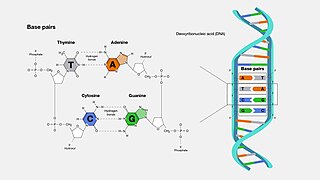
A base pair (bp) is a fundamental unit of double-stranded nucleic acids consisting of two nucleobases bound to each other by hydrogen bonds. They form the building blocks of the DNA double helix and contribute to the folded structure of both DNA and RNA. Dictated by specific hydrogen bonding patterns, "Watson–Crick" base pairs allow the DNA helix to maintain a regular helical structure that is subtly dependent on its nucleotide sequence. The complementary nature of this based-paired structure provides a redundant copy of the genetic information encoded within each strand of DNA. The regular structure and data redundancy provided by the DNA double helix make DNA well suited to the storage of genetic information, while base-pairing between DNA and incoming nucleotides provides the mechanism through which DNA polymerase replicates DNA and RNA polymerase transcribes DNA into RNA. Many DNA-binding proteins can recognize specific base-pairing patterns that identify particular regulatory regions of genes.

Deoxyribonucleic acid is a polymer composed of two polynucleotide chains that coil around each other to form a double helix. The polymer carries genetic instructions for the development, functioning, growth and reproduction of all known organisms and many viruses. DNA and ribonucleic acid (RNA) are nucleic acids. Alongside proteins, lipids and complex carbohydrates (polysaccharides), nucleic acids are one of the four major types of macromolecules that are essential for all known forms of life.

Genetics is the study of genes, genetic variation, and heredity in organisms. It is an important branch in biology because heredity is vital to organisms' evolution. Gregor Mendel, a Moravian Augustinian friar working in the 19th century in Brno, was the first to study genetics scientifically. Mendel studied "trait inheritance", patterns in the way traits are handed down from parents to offspring over time. He observed that organisms inherit traits by way of discrete "units of inheritance". This term, still used today, is a somewhat ambiguous definition of what is referred to as a gene.
In biology, a mutation is an alteration in the nucleic acid sequence of the genome of an organism, virus, or extrachromosomal DNA. Viral genomes contain either DNA or RNA. Mutations result from errors during DNA or viral replication, mitosis, or meiosis or other types of damage to DNA, which then may undergo error-prone repair, cause an error during other forms of repair, or cause an error during replication. Mutations may also result from insertion or deletion of segments of DNA due to mobile genetic elements.

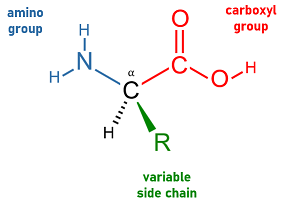
Nucleic acids are large biomolecules that are crucial in all cells and viruses. They are composed of nucleotides, which are the monomer components: a 5-carbon sugar, a phosphate group and a nitrogenous base. The two main classes of nucleic acids are deoxyribonucleic acid (DNA) and ribonucleic acid (RNA). If the sugar is ribose, the polymer is RNA; if the sugar is deoxyribose, a variant of ribose, the polymer is DNA.

Protein biosynthesis is a core biological process, occurring inside cells, balancing the loss of cellular proteins through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.
Molecular evolution is the process of change in the sequence composition of cellular molecules such as DNA, RNA, and proteins across generations. The field of molecular evolution uses principles of evolutionary biology and population genetics to explain patterns in these changes. Major topics in molecular evolution concern the rates and impacts of single nucleotide changes, neutral evolution vs. natural selection, origins of new genes, the genetic nature of complex traits, the genetic basis of speciation, the evolution of development, and ways that evolutionary forces influence genomic and phenotypic changes.
The coding region of a gene, also known as the coding sequence(CDS), is the portion of a gene's DNA or RNA that codes for a protein. Studying the length, composition, regulation, splicing, structures, and functions of coding regions compared to non-coding regions over different species and time periods can provide a significant amount of important information regarding gene organization and evolution of prokaryotes and eukaryotes. This can further assist in mapping the human genome and developing gene therapy.
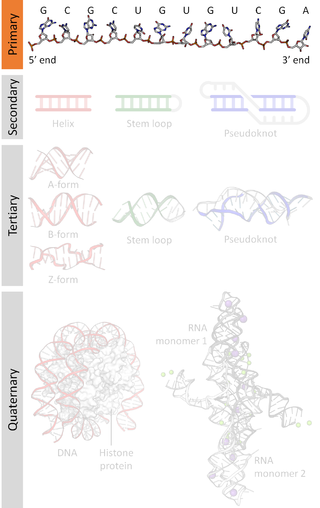
A nucleic acid sequence is a succession of bases within the nucleotides forming alleles within a DNA or RNA (GACU) molecule. This succession is denoted by a series of a set of five different letters that indicate the order of the nucleotides. By convention, sequences are usually presented from the 5' end to the 3' end. For DNA, with its double helix, there are two possible directions for the notated sequence; of these two, the sense strand is used. Because nucleic acids are normally linear (unbranched) polymers, specifying the sequence is equivalent to defining the covalent structure of the entire molecule. For this reason, the nucleic acid sequence is also termed the primary structure.
Molecular genetics is a branch of biology that addresses how differences in the structures or expression of DNA molecules manifests as variation among organisms. Molecular genetics often applies an "investigative approach" to determine the structure and/or function of genes in an organism's genome using genetic screens.

In molecular biology, a reading frame is a way of dividing the sequence of nucleotides in a nucleic acid molecule into a set of consecutive, non-overlapping triplets. Where these triplets equate to amino acids or stop signals during translation, they are called codons.

Chargaff's rules state that in the DNA of any species and any organism, the amount of guanine should be equal to the amount of cytosine and the amount of adenine should be equal to the amount of thymine. Further, a 1:1 stoichiometric ratio of purine and pyrimidine bases should exist. This pattern is found in both strands of the DNA. They were discovered by Austrian-born chemist Erwin Chargaff in the late 1940s.

A point mutation is a genetic mutation where a single nucleotide base is changed, inserted or deleted from a DNA or RNA sequence of an organism's genome. Point mutations have a variety of effects on the downstream protein product—consequences that are moderately predictable based upon the specifics of the mutation. These consequences can range from no effect to deleterious effects, with regard to protein production, composition, and function.

In molecular biology, a library is a collection of DNA fragments that is stored and propagated in a population of micro-organisms through the process of molecular cloning. There are different types of DNA libraries, including cDNA libraries, genomic libraries and randomized mutant libraries. DNA library technology is a mainstay of current molecular biology, genetic engineering, and protein engineering, and the applications of these libraries depend on the source of the original DNA fragments. There are differences in the cloning vectors and techniques used in library preparation, but in general each DNA fragment is uniquely inserted into a cloning vector and the pool of recombinant DNA molecules is then transferred into a population of bacteria or yeast such that each organism contains on average one construct. As the population of organisms is grown in culture, the DNA molecules contained within them are copied and propagated.
Genetics, a discipline of biology, is the science of heredity and variation in living organisms.
In biology, the word gene have several different meanings. The Mendelian gene is a basic unit of heredity and the molecular gene is a sequence of nucleotides in DNA that is transcribed to produce a functional RNA. There are two types of molecular genes: protein-coding genes and non-coding genes.
In molecular biology and genetics, the sense of a nucleic acid molecule, particularly of a strand of DNA or RNA, refers to the nature of the roles of the strand and its complement in specifying a sequence of amino acids. Depending on the context, sense may have slightly different meanings. For example, the negative-sense strand of DNA is equivalent to the template strand, whereas the positive-sense strand is the non-template strand whose nucleotide sequence is equivalent to the sequence of the mRNA transcript.
The following outline is provided as an overview of and topical guide to genetics:
Numerous key discoveries in biology have emerged from studies of RNA, including seminal work in the fields of biochemistry, genetics, microbiology, molecular biology, molecular evolution and structural biology. As of 2010, 30 scientists have been awarded Nobel Prizes for experimental work that includes studies of RNA. Specific discoveries of high biological significance are discussed in this article.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.