Related Research Articles

In computing, a database is an organized collection of data stored and accessed electronically. Small databases can be stored on a file system, while large databases are hosted on computer clusters or cloud storage. The design of databases spans formal techniques and practical considerations including data modeling, efficient data representation and storage, query languages, security and privacy of sensitive data, and distributed computing issues including supporting concurrent access and fault tolerance.
Denormalization is a strategy used on a previously-normalized database to increase performance. In computing, denormalization is the process of trying to improve the read performance of a database, at the expense of losing some write performance, by adding redundant copies of data or by grouping data. It is often motivated by performance or scalability in relational database software needing to carry out very large numbers of read operations. Denormalization differs from the unnormalized form in that denormalization benefits can only be fully realized on a data model that is otherwise normalized.
A relational database is a digital database based on the relational model of data, as proposed by E. F. Codd in 1970. A system used to maintain relational databases is a relational database management system (RDBMS). Many relational database systems have an option of using the SQL for querying and maintaining the database.

An object–relational database (ORD), or object–relational database management system (ORDBMS), is a database management system (DBMS) similar to a relational database, but with an object-oriented database model: objects, classes and inheritance are directly supported in database schemas and in the query language. In addition, just as with pure relational systems, it supports extension of the data model with custom data types and methods.
First normal form (1NF) is a property of a relation in a relational database. A relation is in first normal form if and only if no attribute domain has relations as elements. Or more informally, that no table column can have tables as values. Database normalization is the process of representing a database in terms of relations in standard normal forms, where first normal is a minimal requirement. SQL does not support creating or using table-valued columns, which means most relational databases will be in first normal form by necessity. Database systems which do not require first normal form are often called no sql systems.

The database schema is its structure described in a formal language supported by the database management system (DBMS). The term "schema" refers to the organization of data as a blueprint of how the database is constructed. The formal definition of a database schema is a set of formulas (sentences) called integrity constraints imposed on a database. These integrity constraints ensure compatibility between parts of the schema. All constraints are expressible in the same language. A database can be considered a structure in realization of the database language. The states of a created conceptual schema are transformed into an explicit mapping, the database schema. This describes how real-world entities are modeled in the database.
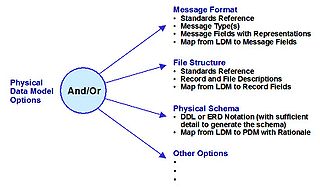
A physical data model is a representation of a data design as implemented, or intended to be implemented, in a database management system. In the lifecycle of a project it typically derives from a logical data model, though it may be reverse-engineered from a given database implementation. A complete physical data model will include all the database artifacts required to create relationships between tables or to achieve performance goals, such as indexes, constraint definitions, linking tables, partitioned tables or clusters. Analysts can usually use a physical data model to calculate storage estimates; it may include specific storage allocation details for a given database system.
Database design is the organization of data according to a database model. The designer determines what data must be stored and how the data elements interrelate. With this information, they can begin to fit the data to the database model. Database management system manages the data accordingly.
An XML database is a data persistence software system that allows data to be specified, and sometimes stored, in XML format. This data can be queried, transformed, exported and returned to a calling system. XML databases are a flavor of document-oriented databases which are in turn a category of NoSQL database.
The object–relational impedance mismatch is a set of conceptual and technical difficulties that are often encountered when a relational database management system (RDBMS) is being served by an application program written in an object-oriented programming language or style, particularly because objects or class definitions must be mapped to database tables defined by a relational schema.
Entity–attribute–value model (EAV) is a data model to encode, in a space-efficient manner, entities where the number of attributes that can be used to describe them is potentially vast, but the number that will actually apply to a given entity is relatively modest. Such entities correspond to the mathematical notion of a sparse matrix.
A column-oriented DBMS or columnar DBMS is a database management system (DBMS) that stores data tables by column rather than by row. Benefits include more efficient access to data when only querying a subset of columns, and more options for data compression. However, they are typically less efficient to insert new data.
A database model is a type of data model that determines the logical structure of a database. It fundamentally determines in which manner data can be stored, organized and manipulated. The most popular example of a database model is the relational model, which uses a table-based format.
Database tables and indexes may be stored on disk in one of a number of forms, including ordered/unordered flat files, ISAM, heap files, hash buckets, or B+ trees. Each form has its own particular advantages and disadvantages. The most commonly used forms are B-trees and ISAM. Such forms or structures are one aspect of the overall schema used by a database engine to store information.
Entity Framework (EF) is an open source object–relational mapping (ORM) framework for ADO.NET. It was originally shipped as an integral part of .NET Framework. Starting with Entity Framework version 6, it has been delivered separately from the .NET Framework.
A document-oriented database, or document store, is a computer program and data storage system designed for storing, retrieving and managing document-oriented information, also known as semi-structured data.
In computing, a graph database (GDB) is a database that uses graph structures for semantic queries with nodes, edges, and properties to represent and store data. A key concept of the system is the graph. The graph relates the data items in the store to a collection of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the store to be linked together directly and, in many cases, retrieved with one operation. Graph databases hold the relationships between data as a priority. Querying relationships is fast because they are perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them useful for heavily inter-connected data.
SAND Nucleus CDBMS is a column-oriented DBMS software system optimized for business intelligence applications, delivering the data warehousing component, developed by SAND Technology Inc.
The following is provided as an overview of and topical guide to databases:
SingleStore is a distributed, relational, SQL database management system (RDBMS) that features ANSI SQL support and is known for speed in data ingest, transaction processing, and query processing. SingleStore was formerly known as MemSQL.
References
- ↑ Raab, David M."Analytical Database Options". Information Management Magazine 1 July 2008.
- ↑ Raden, Neil."Databases ALIVE". Intelligent Enterprise 18 April 2008.
- ↑ Powell, James E."Illuminate's Correlation Database Accelerates, Expands BI Queries". Enterprise Systems Journal 9 April 2008.
- ↑ Swoyer, Steven."In Depth: Closing the Ad Hoc Query Performance Gap for Good". Enterprise Systems Journal 9 July 2008.
| Types | |
|---|---|
| Concepts | |
| Objects | |
| Components | |
| Functions | |
| Related topics | |