Related Research Articles
In statistics, a central tendency is a central or typical value for a probability distribution.

In descriptive statistics, the interquartile range (IQR) is a measure of statistical dispersion, which is the spread of the data. The IQR may also be called the midspread, middle 50%, fourth spread, or H‑spread. It is defined as the difference between the 75th and 25th percentiles of the data. To calculate the IQR, the data set is divided into quartiles, or four rank-ordered even parts via linear interpolation. These quartiles are denoted by Q1 (also called the lower quartile), Q2 (the median), and Q3 (also called the upper quartile). The lower quartile corresponds with the 25th percentile and the upper quartile corresponds with the 75th percentile, so IQR = Q3 − Q1.

In statistics and probability theory, the median is the value separating the higher half from the lower half of a data sample, a population, or a probability distribution. For a data set, it may be thought of as "the middle" value. The basic feature of the median in describing data compared to the mean is that it is not skewed by a small proportion of extremely large or small values, and therefore provides a better representation of the center. Median income, for example, may be a better way to describe center of the income distribution because increases in the largest incomes alone have no effect on median. For this reason, the median is of central importance in robust statistics.
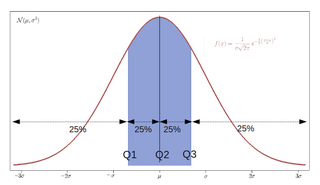
In statistics and probability, quantiles are cut points dividing the range of a probability distribution into continuous intervals with equal probabilities, or dividing the observations in a sample in the same way. There is one fewer quantile than the number of groups created. Common quantiles have special names, such as quartiles, deciles, and percentiles. The groups created are termed halves, thirds, quarters, etc., though sometimes the terms for the quantile are used for the groups created, rather than for the cut points.

In descriptive statistics, summary statistics are used to summarize a set of observations, in order to communicate the largest amount of information as simply as possible. Statisticians commonly try to describe the observations in

In statistics, the standard deviation is a measure of the amount of variation or dispersion of a set of values. A low standard deviation indicates that the values tend to be close to the mean of the set, while a high standard deviation indicates that the values are spread out over a wider range.
In statistics, an outlier is a data point that differs significantly from other observations. An outlier may be due to a variability in the measurement, an indication of novel data, or it may be the result of experimental error; the latter are sometimes excluded from the data set. An outlier can be an indication of exciting possibility, but can also cause serious problems in statistical analyses.
The average absolute deviation (AAD) of a data set is the average of the absolute deviations from a central point. It is a summary statistic of statistical dispersion or variability. In the general form, the central point can be a mean, median, mode, or the result of any other measure of central tendency or any reference value related to the given data set. AAD includes the mean absolute deviation and the median absolute deviation.
In probability theory and statistics, the coefficient of variation (CV), also known as Normalized Root-Mean-Square Deviation (NRMSD), Percent RMS, and relative standard deviation (RSD), is a standardized measure of dispersion of a probability distribution or frequency distribution. It is defined as the ratio of the standard deviation to the mean , and often expressed as a percentage ("%RSD"). The CV or RSD is widely used in analytical chemistry to express the precision and repeatability of an assay. It is also commonly used in fields such as engineering or physics when doing quality assurance studies and ANOVA gauge R&R, by economists and investors in economic models, and in psychology/neuroscience.
This glossary of statistics and probability is a list of definitions of terms and concepts used in the mathematical sciences of statistics and probability, their sub-disciplines, and related fields. For additional related terms, see Glossary of mathematics and Glossary of experimental design.
In statistics, the mid-range or mid-extreme is a measure of central tendency of a sample defined as the arithmetic mean of the maximum and minimum values of the data set:
Robust statistics are statistics with good performance for data drawn from a wide range of probability distributions, especially for distributions that are not normal. Robust statistical methods have been developed for many common problems, such as estimating location, scale, and regression parameters. One motivation is to produce statistical methods that are not unduly affected by outliers. Another motivation is to provide methods with good performance when there are small departures from a parametric distribution. For example, robust methods work well for mixtures of two normal distributions with different standard deviations; under this model, non-robust methods like a t-test work poorly.
In mathematics and statistics, deviation is a measure of difference between the observed value of a variable and some other value, often that variable's mean. The sign of the deviation reports the direction of that difference. The magnitude of the value indicates the size of the difference.
In statistics the trimean (TM), or Tukey's trimean, is a measure of a probability distribution's location defined as a weighted average of the distribution's median and its two quartiles:
(MAD) is an acronym for both median absolute deviation and mean absolute deviation; there is no universal agreement on which is correct. It is used here to connote the former.
In statistics, an L-estimator is an estimator which is a linear combination of order statistics of the measurements. This can be as little as a single point, as in the median, or as many as all points, as in the mean.
In statistics, a trimmed estimator is an estimator derived from another estimator by excluding some of the extreme values, a process called truncation. This is generally done to obtain a more robust statistic, and the extreme values are considered outliers. Trimmed estimators also often have higher efficiency for mixture distributions and heavy-tailed distributions than the corresponding untrimmed estimator, at the cost of lower efficiency for other distributions, such as the normal distribution.
In statistics, the sample maximum and sample minimum, also called the largest observation and smallest observation, are the values of the greatest and least elements of a sample. They are basic summary statistics, used in descriptive statistics such as the five-number summary and Bowley's seven-figure summary and the associated box plot.
In statistics, robust measures of scale are methods that quantify the statistical dispersion in a sample of numerical data while resisting outliers. The most common such robust statistics are the interquartile range (IQR) and the median absolute deviation (MAD). These are contrasted with conventional or non-robust measures of scale, such as sample standard deviation, which are greatly influenced by outliers.

In statistics, dispersion is the extent to which a distribution is stretched or squeezed. Common examples of measures of statistical dispersion are the variance, standard deviation, and interquartile range. For instance, when the variance of data in a set is large, the data is widely scattered. On the other hand, when the variance is small, the data in the set is clustered.
References
This article needs additional citations for verification .(April 2013) |
- ↑ Evans 1955, Appendix G: Inefficient statistics, pp. 902–904.
- Evans, Robley Dunglison (1955). The Atomic Nucleus. International series in pure and applied physics. McGraw-Hill. p. 972. ISBN 0-89874414-8.