
Ethernet is a family of wired computer networking technologies commonly used in local area networks (LAN), metropolitan area networks (MAN) and wide area networks (WAN). It was commercially introduced in 1980 and first standardized in 1983 as IEEE 802.3. Ethernet has since been refined to support higher bit rates, a greater number of nodes, and longer link distances, but retains much backward compatibility. Over time, Ethernet has largely replaced competing wired LAN technologies such as Token Ring, FDDI and ARCNET.
A network switch is networking hardware that connects devices on a computer network by using packet switching to receive and forward data to the destination device.

A metropolitan area network (MAN) is a computer network that interconnects users with computer resources in a geographic region of the size of a metropolitan area. The term MAN is applied to the interconnection of local area networks (LANs) in a city into a single larger network which may then also offer efficient connection to a wide area network. The term is also used to describe the interconnection of several LANs in a metropolitan area through the use of point-to-point connections between them.

InfiniBand (IB) is a computer networking communications standard used in high-performance computing that features very high throughput and very low latency. It is used for data interconnect both among and within computers. InfiniBand is also used as either a direct or switched interconnect between servers and storage systems, as well as an interconnect between storage systems. It is designed to be scalable and uses a switched fabric network topology. Between 2014 and June 2016, it was the most commonly used interconnect in the TOP500 list of supercomputers.

HIPPI, short for High Performance Parallel Interface, is a computer bus for the attachment of high speed storage devices to supercomputers, in a point-to-point link. It was popular in the late 1980s and into the mid-to-late 1990s, but has since been replaced by ever-faster standard interfaces like Fibre Channel and 10 Gigabit Ethernet.

VMEbus is a computer bus standard physically based on Eurocard sizes.

A network interface controller is a computer hardware component that connects a computer to a computer network.

Quadrics was a supercomputer company formed in 1996 as a joint venture between Alenia Spazio and the technical team from Meiko Scientific. They produced hardware and software for clustering commodity computer systems into massively parallel systems. Their highpoint was in June 2003 when six out of the ten fastest supercomputers in the world were based on Quadrics' interconnect. They officially closed on June 29, 2009.
In computing, remote direct memory access (RDMA) is a direct memory access from the memory of one computer into that of another without involving either one's operating system. This permits high-throughput, low-latency networking, which is especially useful in massively parallel computer clusters.
In computer networking, jumbo frames are Ethernet frames with more than 1500 bytes of payload, the limit set by the IEEE 802.3 standard. The payload limit for jumbo frames is variable: while 9000 bytes is the most commonly used limit, smaller and larger limits exist. Many Gigabit Ethernet switches and Gigabit Ethernet network interface controllers and some Fast Ethernet switches and Fast Ethernet network interface cards can support jumbo frames.

The IBM BladeCenter was IBM's blade server architecture, until it was replaced by Flex System in 2012. The x86 division was later sold to Lenovo in 2014.
In audio and broadcast engineering, audio over Ethernet (AoE) is the use of an Ethernet-based network to distribute real-time digital audio. AoE replaces bulky snake cables or audio-specific installed low-voltage wiring with standard network structured cabling in a facility. AoE provides a reliable backbone for any audio application, such as for large-scale sound reinforcement in stadiums, airports and convention centers, multiple studios or stages.

VPX, also known as VITA 46, is a set of standards for connecting components of a computer, commonly used by defense contractors. Some are ANSI standards such as ANSI/VITA 46.0–2019. VPX provides VMEbus-based systems with support for switched fabrics over a new high speed connector. Defined by the VMEbus International Trade Association (VITA) working group starting in 2003, it was first demonstrated in 2004, and became an ANSI standard in 2007.

Magerit is one of the most powerful supercomputers in Spain. It also reached the second best Spanish position in the TOP500 list of supercomputers. It is installed in CeSViMa, a research center of the Technical University of Madrid.
QPACE is a massively parallel and scalable supercomputer designed for applications in lattice quantum chromodynamics.
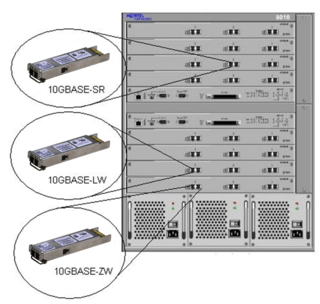
10 Gigabit Ethernet is a group of computer networking technologies for transmitting Ethernet frames at a rate of 10 gigabits per second. It was first defined by the IEEE 802.3ae-2002 standard. Unlike previous Ethernet standards, 10GbE defines only full-duplex point-to-point links which are generally connected by network switches; shared-medium CSMA/CD operation has not been carried over from the previous generations of Ethernet standards so half-duplex operation and repeater hubs do not exist in 10GbE. The first standard for faster 100 Gigabit Ethernet links was approved in 2010.

The Linux-IOTarget (LIO) is an open-source Small Computer System Interface (SCSI) target implementation included with the Linux kernel.

Mellanox Technologies Ltd. was an Israeli-American multinational supplier of computer networking products based on InfiniBand and Ethernet technology. Mellanox offered adapters, switches, software, cables and silicon for markets including high-performance computing, data centers, cloud computing, computer data storage and financial services.

QPACE 2 is a massively parallel and scalable supercomputer. It was designed for applications in lattice quantum chromodynamics but is also suitable for a wider range of applications..