Related Research Articles

An exon is any part of a gene that will form a part of the final mature RNA produced by that gene after introns have been removed by RNA splicing. The term exon refers to both the DNA sequence within a gene and to the corresponding sequence in RNA transcripts. In RNA splicing, introns are removed and exons are covalently joined to one another as part of generating the mature RNA. Just as the entire set of genes for a species constitutes the genome, the entire set of exons constitutes the exome.
An intron is any nucleotide sequence within a gene that is not expressed or operative in the final RNA product. The word intron is derived from the term intragenic region, i.e. a region inside a gene. The term intron refers to both the DNA sequence within a gene and the corresponding RNA sequence in RNA transcripts. The non-intron sequences that become joined by this RNA processing to form the mature RNA are called exons.

RNA splicing is a process in molecular biology where a newly-made precursor messenger RNA (pre-mRNA) transcript is transformed into a mature messenger RNA (mRNA). It works by removing all the introns and splicing back together exons. For nuclear-encoded genes, splicing occurs in the nucleus either during or immediately after transcription. For those eukaryotic genes that contain introns, splicing is usually needed to create an mRNA molecule that can be translated into protein. For many eukaryotic introns, splicing occurs in a series of reactions which are catalyzed by the spliceosome, a complex of small nuclear ribonucleoproteins (snRNPs). There exist self-splicing introns, that is, ribozymes that can catalyze their own excision from their parent RNA molecule. The process of transcription, splicing and translation is called gene expression, the central dogma of molecular biology.
The coding region of a gene, also known as the coding sequence(CDS), is the portion of a gene's DNA or RNA that codes for protein. Studying the length, composition, regulation, splicing, structures, and functions of coding regions compared to non-coding regions over different species and time periods can provide a significant amount of important information regarding gene organization and evolution of prokaryotes and eukaryotes. This can further assist in mapping the human genome and developing gene therapy.

Alternative splicing, or alternative RNA splicing, or differential splicing, is an alternative splicing process during gene expression that allows a single gene to code for multiple proteins. In this process, particular exons of a gene may be included within or excluded from the final, processed messenger RNA (mRNA) produced from that gene. This means the exons are joined in different combinations, leading to different (alternative) mRNA strands. Consequently, the proteins translated from alternatively spliced mRNAs usually contain differences in their amino acid sequence and, often, in their biological functions.
In computational biology, gene prediction or gene finding refers to the process of identifying the regions of genomic DNA that encode genes. This includes protein-coding genes as well as RNA genes, but may also include prediction of other functional elements such as regulatory regions. Gene finding is one of the first and most important steps in understanding the genome of a species once it has been sequenced.

A primary transcript is the single-stranded ribonucleic acid (RNA) product synthesized by transcription of DNA, and processed to yield various mature RNA products such as mRNAs, tRNAs, and rRNAs. The primary transcripts designated to be mRNAs are modified in preparation for translation. For example, a precursor mRNA (pre-mRNA) is a type of primary transcript that becomes a messenger RNA (mRNA) after processing.
The 5′ untranslated region is the region of a messenger RNA (mRNA) that is directly upstream from the initiation codon. This region is important for the regulation of translation of a transcript by differing mechanisms in viruses, prokaryotes and eukaryotes. While called untranslated, the 5′ UTR or a portion of it is sometimes translated into a protein product. This product can then regulate the translation of the main coding sequence of the mRNA. In many organisms, however, the 5′ UTR is completely untranslated, instead forming a complex secondary structure to regulate translation.

An intergenic region is a stretch of DNA sequences located between genes. Intergenic regions may contain functional elements and junk DNA. Intergenic regions should not be confused with intragenic regions, which are non-coding regions that are found within genes, especially within the genes of eukaryotic organisms.

In biology, the word gene can have several different meanings. The Mendelian gene is a basic unit of heredity and the molecular gene is a sequence of nucleotides in DNA that is transcribed to produce a functional RNA. There are two types of molecular genes: protein-coding genes and noncoding genes.
Eukaryotic chromosome fine structure refers to the structure of sequences for eukaryotic chromosomes. Some fine sequences are included in more than one class, so the classification listed is not intended to be completely separate.
Exon shuffling is a molecular mechanism for the formation of new genes. It is a process through which two or more exons from different genes can be brought together ectopically, or the same exon can be duplicated, to create a new exon-intron structure. There are different mechanisms through which exon shuffling occurs: transposon mediated exon shuffling, crossover during sexual recombination of parental genomes and illegitimate recombination.
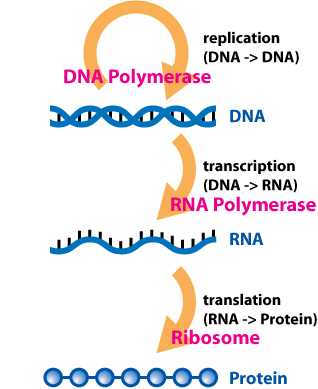
In molecular genetics, an untranslated region refers to either of two sections, one on each side of a coding sequence on a strand of mRNA. If it is found on the 5' side, it is called the 5' UTR, or if it is found on the 3' side, it is called the 3' UTR. mRNA is RNA that carries information from DNA to the ribosome, the site of protein synthesis (translation) within a cell. The mRNA is initially transcribed from the corresponding DNA sequence and then translated into protein. However, several regions of the mRNA are usually not translated into protein, including the 5' and 3' UTRs.
Numerous key discoveries in biology have emerged from studies of RNA, including seminal work in the fields of biochemistry, genetics, microbiology, molecular biology, molecular evolution and structural biology. As of 2010, 30 scientists have been awarded Nobel Prizes for experimental work that includes studies of RNA. Specific discoveries of high biological significance are discussed in this article.
Periannan Senapathy is a molecular biologist, geneticist, author and entrepreneur. He is the founder, president and chief scientific officer at Genome International Corporation, a biotechnology, bioinformatics, and information technology firm based in Madison, Wisconsin, which develops computational genomics applications of next-generation DNA sequencing (NGS) and clinical decision support systems for analyzing patient genome data that aids in diagnosis and treatment of diseases.

Circular RNA is a type of single-stranded RNA which, unlike linear RNA, forms a covalently closed continuous loop. In circular RNA, the 3' and 5' ends normally present in an RNA molecule have been joined together. This feature confers numerous properties to circular RNA, many of which have only recently been identified.
Exitrons are produced through alternative splicing and have characteristics of both introns and exons, but are described as retained introns. Even though they are considered introns, which are typically cut out of pre mRNA sequences, there are significant problems that arise when exitrons are spliced out of these strands, with the most obvious result being altered protein structures and functions. They were first discovered in plants, but have recently been found in metazoan species as well.
The split gene theory is a theory of the origin of introns, long non-coding sequences in eukaryotic genes between the exons. The theory holds that the randomness of primordial DNA sequences would only permit small (< 600bp) open reading frames (ORFs), and that important intron structures and regulatory sequences are derived from stop codons. In this introns-first framework, the spliceosomal machinery and the nucleus evolved due to the necessity to join these ORFs into larger proteins, and that intronless bacterial genes are less ancestral than the split eukaryotic genes. The theory originated with Periannan Senapathy.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is intended as introductory material for novices; for more specific and technical detail, see the article corresponding to each term. For related terms, see Glossary of evolutionary biology.
This glossary of genetics is a list of definitions of terms and concepts commonly used in the study of genetics and related disciplines in biology, including molecular biology, cell biology, and evolutionary biology. It is split across two articles:
References
- 1 2 3 Kumar, Anuj (September 2009). "An Overview of Nested Genes in Eukaryotic Genomes". Eukaryotic Cell. 8 (9): 1321–29. doi:10.1128/EC.00143-09. PMC 2747821 . PMID 19542305..
- ↑ Yu P.; Ma D.; Xu M. (October 2005). "Nested genes in the human genome". Genomics. 86 (4): 414–22. doi:10.1016/j.ygeno.2005.06.008. PMID 16084061.