Examples of different levels of nuclear architecture.
Nuclear organization refers to the spatial organization of chromatin within a cellnucleus during interphase. There are many different levels and scales of nuclear organization.
At the smallest scale, DNA is packaged into units called nucleosomes, which compact DNA about 7-fold. In addition, nucleosomes protect DNA from damage and carry epigenetic information. Positions of nucleosomes determine accessibility of DNA to transcription factors.
At the intermediate scale, DNA looping can physically bring together DNA elements that would otherwise be separated by large distances. These interactions allow regulatory signals to cross over large genomic distances—for example, from enhancers to promoters.
At a larger scale, chromosomes are organized into two compartments labelled A ("active") and B ("inactive"), which are further subdivided into sub-compartments.[1] At the largest scale, entire chromosomes segregate into distinct regions called chromosome territories.
Each human cell contains around two metres of DNA, which must be tightly folded to fit inside the cell nucleus. However, in order for the cell to function, proteins must be able to access the sequence information contained within the DNA, in spite of its tightly-packed nature. Hence, the cell has a number of mechanisms in place to control how DNA is organized.[4]
Moreover, nuclear organization can play a role in establishing cell identity. Cells within an organism have near identical nucleic acid sequences, but often exhibit different phenotypes. One way in which this individuality occurs is through changes in genome architecture, which can alter the expression of different sets of genes.[5] These alterations can have a downstream effect on cellular functions such as cell cycle facilitation, DNA replication, nuclear transport, and alteration of nuclear structure. Controlled changes in nuclear organization are essential for proper cellular function.
History and methodology
The organization of chromosomes into distinct regions within the nucleus was first proposed in 1885 by Carl Rabl. Later in 1909, with the help of the microscopy technology at the time, Theodor Boveri coined the termed chromosome territories after observing that chromosomes occupy individually distinct nuclear regions.[6] Since then, mapping genome architecture has become a major topic of interest.
Over the last ten years, rapid methodological developments have greatly advanced understanding in this field.[4] Large-scale DNA organization can be assessed with DNA imaging using fluorescent tags, such as DNA Fluorescence in situ hybridization (FISH), and specialized microscopes.[7] Additionally, high-throughput sequencing technologies such as Chromosome Conformation Capture-based methods can measure how often DNA regions are in close proximity.[8] At the same time, progress in genome-editing techniques (such as CRISPR/Cas9, ZFNs, and TALENs) have made it easier to test the organizational function of specific DNA regions and proteins.[9] There is also growing interest in the rheological properties of the interchromosomal space, studied by the means of Fluorescence Correlation Spectroscopy and its variants.[10][11]
Architectural proteins
Architectural proteins regulate chromatin structure by establishing physical interactions between DNA elements.[12] These proteins tend to be highly conserved across a majority of eukaryotic species.[13][14]
In mammals, key architectural proteins include:
Histones: DNA is wrapped around histones to form nucleosomes, which are basic units of chromatin structure. Each nucleosome consists of 8 histone protein subunits, around which roughly 147 DNA base pairs are wrapped in 1.67 left-handed turns. Nucleosomes provide about 7-fold initial linear compaction of DNA.[15] The concentration and specific composition of histones used can determine local chromatin structure. For example, euchromatin is a form of chromatin with low nucleosome concentration - here, the DNA is exposed, promoting interactions with gene expression, replication, and organizational machinery. In contrast, heterochromatin has high nucleosome concentration and is associated with repression of gene expression and replication, as the necessary proteins cannot interact with the DNA.
Chromatin remodeling enzymes: These enzymes are responsible for promoting euchromatin or heterochromatin formation by a number of processes, particularly modifying histone tails or physically moving the nucleosomes. This in turn, helps regulate gene expression, replication, and how the chromatin interacts with architectural factors.[16] The list of chromatin remodeling enzymes is extensive and many have specific roles within the nucleus. For example, in 2016 Wiechens et al. identified two human enzymes, SNF2H and SNF2L, that are active in regulating CTCF binding and therefore affect genome organization and transcription of many genes.[17]
CCCTC-binding factor (CTCF), or 11-zinc finger protein, is considered the most prominent player in linking genome organization with gene expression.[14] CTCF interacts with specific DNA sequences and a variety of other architectural proteins, chiefly cohesin[18] - these behaviours allow it to mediate DNA looping, thus acting as transcriptional repressor, activator, and insulator. Furthermore, CTCF is often found at self-interacting domain boundaries, and can anchor the chromatin to the nuclear lamina.[19] CTCF is also involved in V(D)J recombination.[20]
Cohesin: The cohesin complex was initially discovered as a key player in mitosis, binding sister chromatids together to ensure proper segregation. However, cohesin has since been linked to many more functions within the cell.[21] It has been found to help facilitate DNA repair and recombination, meiotic chromosome pairing and orientation, chromosome condensation, DNA replication, gene expression, and genome architecture.[22] Cohesin is a heterodimer composed of the proteins SMC1 and SMC3 in combination with the SCC1 and SCC3 proteins. The entire complex is loaded onto DNA by the NIPBL-MAU2 complex in a ring-like fashion.[23]
Levels of nuclear organization
Nucleosome fiber
The hierarchical structure through which DNA is packaged into chromosomes.
The organization of DNA within the nucleus begins with the 10nm fiber, a "beads-on-a-string" structure[24] made of nucleosomes connected by 20-60bp linkers. A fiber of nucleosomes is interrupted by regions of accessible DNA, which are 100-1000bp long regions devoid of nucleosomes. Transcription factors bind within accessible DNA to displace nucleosomes and form cis-regulatory elements. Sites of accessible DNA are typically probed by ATAC-seq or DNase-Seq experimental methods.
A 30nm fiber has long been proposed as the next layer of chromatin organization. While 30nm fiber is often visible in vitro under high salt concentration,[25] its existence in vivo has been questioned in many recent studies.[26][27][28] Instead, these studies point towards a disordered fiber with a width of 20 to 50nm.
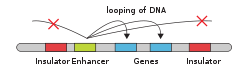
A cartoon representing an enhancer interacting with genes through DNA looping.
The process of loop extrusion by SMC complexes dynamically creates chromatin loops ranging in size from 50-100kb in yeast [29] to up to several Mb in mammals.[30] There is strong support for loop extrusion in yeast, mammals, and nematodes.[31]
The presence of loop extrusion in fruit flies is debated and the formation of DNA loops may be mediated by a different process of boundary element pairing.[32]
Self-interacting (or self-associating) domains are found in many organisms. In eukaryotes, they have been usually referred to as TADs irrespective of the mechanism of their formation. TADs have a higher ratio of chromosomal contacts within the domain than outside it.[33] They are formed through the help of architectural proteins. In many organisms, TADs correlate with regulation of gene expression, and enhancers and promoters within a TAD interact at higher frequency.[30]
Lamina-associating domains and nucleolar-associating domains
Lamina-associating domains (LADs) and nucleolar-associating domains (NADs) are regions of the chromosome that interact with the nuclear lamina and nucleolus, respectively.
Making up approximately 40% of the genome, LADs consist mostly of gene poor regions and span between 40kb to 30Mb in size.[19] There are two known types of LADs: constitutive LADs (cLADs) and facultative LADs (fLADs). cLADs are A-T rich heterochromatin regions that remain on lamina and are seen across many types of cells and species. There is evidence that these regions are important to the structural formation of interphase chromosome. On the other hand, fLADs have varying lamina interactions and contain genes that are either activated or repressed between individual cells indicating cell-type specificity.[34] The boundaries of LADs, like self-interacting domains, are enriched in transcriptional elements and architectural protein binding sites.[19]
NADs, which constitutes 4% of the genome, share nearly all of the same physical characteristics as LADs. In fact, DNA analysis of these two types of domains have shown that many sequences overlap, indicating that certain regions may switch between lamina-binding and nucleolus-binding.[35] NADs are associated with nucleolus function. The nucleolus is the largest sub-organelle within the nucleus and is the principal site for rRNA transcription. It also acts in signal recognition particle biosynthesis, protein sequestration, and viral replication.[36] The nucleolus forms around rDNA genes from different chromosomes. However, only a subset of rDNA genes is transcribed at a time and do so by looping into the interior of the nucleolus. The rest of the genes lay on the periphery of the sub-nuclear organelle in silenced heterochromatin state.[35]
A/B compartments
A/B compartments were first discovered in early Hi-C studies.[37][38] Researchers noticed that the whole genome could be split into two spatial compartments, labelled "A" and "B", where regions in compartment A tend to interact preferentially with A compartment-associated regions than B compartment-associated ones. Similarly, regions in compartment B tend to associate with other B compartment-associated regions.
A/B compartment interactions span larger genomic regions than TADs and LADs and represent a network connecting regions of open and expression-active chromatin ("A" compartments) or closed and expression-inactive chromatin ("B" compartments).[37] Generally compartments represent large domains of chromatin, but the genomic compartmentalization is visible also at a very fine level, with examples of single genes alternating between A and B compartment.[39] A compartments tend to be gene-rich, have high GC-content, contain histone markers for active transcription, and usually displace the interior of the nucleus. As well, they are typically made up of self-interacting domains and contain early replication origins. B compartments, on the other hand, tend to be gene-poor, compact, contain histone markers for gene silencing, and lie on the nuclear periphery. They consist mostly of LADs and contain late replication origins.[37] In addition, higher resolution Hi-C coupled with machine learning methods has revealed that A/B compartments can be refined into subcompartments.[40][41]
The fact that compartments self-interact is consistent with the idea that the nucleus localizes proteins and other factors such as long non-coding RNA (lncRNA) in regions suited for their individual roles.[citation needed] An example of this is the presence of multiple transcription factories throughout the nuclear interior.[42] These factories are associated with elevated levels of transcription due to the high concentration of transcription factors (such as transcription protein machinery, active genes, regulatory elements, and nascent RNA). Around 95% of active genes are transcribed within transcription factories. Each factory can transcribe multiple genes – these genes need not have similar product functions, nor do they need to lie on the same chromosome. Finally, the co-localization of genes within transcription factories is known to depend on cell type.[43]
The last level of organization concerns the distinct positioning of individual chromosomes within the nucleus. The region occupied by a chromosome is called a chromosome territory (CT).[44] Among eukaryotes, CTs have several common properties. First, although chromosomal locations are not the same across cells within a population, there is some preference among individual chromosomes for particular regions. For example, large, gene-poor chromosomes are commonly located on the periphery near the nuclear lamina while smaller, gene-rich chromosomes group closer to the center of the nucleus.[45] Second, individual chromosome preference is variable among different cell types. For example, the X-chromosome has shown to localize to the periphery more often in liver cells than in kidney cells.[46] Another conserved property of chromosome territories is that homologous chromosomes tend to be far apart from one another during cell interphase. The final characteristic is that the position of individual chromosomes during each cell cycle stays relatively the same until the start of mitosis.[47] The mechanisms and reasons behind chromosome territory characteristics is still unknown and further experimentation is needed.
↑Cook PR (January 2010). "A model for all genomes: the role of transcription factories". Journal of Molecular Biology. 395 (1): 1–10. doi:10.1016/j.jmb.2009.10.031. PMID19852969.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.