Functional data analysis (FDA) is a branch of statistics that analyses data providing information about curves, surfaces or anything else varying over a continuum. In its most general form, under an FDA framework, each sample element of functional data is considered to be a random function. The physical continuum over which these functions are defined is often time, but may also be spatial location, wavelength, probability, etc. Intrinsically, functional data are infinite dimensional. The high intrinsic dimensionality of these data brings challenges for theory as well as computation, where these challenges vary with how the functional data were sampled. However, the high or infinite dimensional structure of the data is a rich source of information and there are many interesting challenges for research and data analysis.
Functional data analysis has roots going back to work by Grenander and Karhunen in the 1940s and 1950s.[1][2][3][4] They considered the decomposition of square-integrable continuous time stochastic process into eigencomponents, now known as the Karhunen-Loève decomposition. A rigorous analysis of functional principal components analysis was done in the 1970s by Kleffe, Dauxois and Pousse including results about the asymptotic distribution of the eigenvalues.[5][6] More recently in the 1990s and 2000s the field has focused more on applications and understanding the effects of dense and sparse observations schemes. The term "Functional Data Analysis" was coined by James O. Ramsay.[7]
Mathematical formalism
Random functions can be viewed as random elements taking values in a Hilbert space, or as a stochastic process. The former is mathematically convenient, whereas the latter is somewhat more suitable from an applied perspective. These two approaches coincide if the random functions are continuous and a condition called mean-squared continuity is satisfied.[8]
Hilbertian random variables
In the Hilbert space viewpoint, one considers an -valued random element , where is a separable Hilbert space such as the space of square-integrable functions. Under the integrability condition that , one can define the mean of as the unique element satisfying
The Hilbertian point of view is mathematically convenient, but abstract; the above considerations do not necessarily even view as a function at all, since common choices of like and Sobolev spaces consist of equivalence classes, not functions. The stochastic process perspective views as a collection of random variables
indexed by the unit interval (or more generally interval ). The mean and covariance functions are defined in a pointwise manner as
(if for all ).
Under the mean square continuity, and are continuous functions and then the covariance function defines a covariance operator given by
Moreover, since is continuous for all , all the are continuous. Mercer's theorem then states that
Finally, under the extra assumption that has continuous sample paths, namely that with probability one, the random function is continuous, the Karhunen-Loève expansion above holds for and the Hilbert space machinery can be subsequently applied. Continuity of sample paths can be shown using Kolmogorov continuity theorem.
Functional data designs
Functional data are considered as realizations of a stochastic process that is an process on a bounded and closed interval with mean function and covariance function . The realizations of the process for the i-th subject is , and the sample is assumed to consist of independent subjects. The sampling schedule may vary across subjects, denoted as for the i-th subject. The corresponding i-th observation is denoted as , where . In addition, the measurement of is assumed to have random noise with and , which are independent across and .
1. Fully observed functions without noise at arbitrarily dense grid
3. Sparsely sampled functions with noisy measurements (longitudinal data)
Measurements , where are random times and their number per subject is random and finite.
Real life example: CD4 count data for AIDS patients.[9]
Functional principal component analysis
Functional principal component analysis (FPCA) is the most prevalent tool in FDA, partly because FPCA facilitates dimension reduction of the inherently infinite-dimensional functional data to finite-dimensional random vector of scores. More specifically, dimension reduction is achieved by expanding the underlying observed random trajectories in a functional basis consisting of the eigenfunctions of the covariance operator on . Consider the covariance operator as in (1), which is a compact operator on Hilbert space.
By Mercer's theorem, the kernel function of , i.e., the covariance function , has spectral decomposition , where the series convergence is absolute and uniform, and are real-valued nonnegative eigenvalues in descending order with the corresponding orthonormal eigenfunctions . By the Karhunen–Loève theorem, the FPCA expansion of an underlying random trajectory is , where are the functional principal components (FPCs), sometimes referred to as scores.
The Karhunen–Loève expansion facilitates dimension reduction in the sense that the partial sum converges uniformly, i.e., and thus the partial sum with a large enough yields a good approximation to the infinite sum. Thereby, the information in is reduced from infinite dimensional to a -dimensional vector with the approximated process:
Functional linear models can be viewed as an extension of the traditional multivariate linear models that associates vector responses with vector covariates. The traditional linear model with scalar response and vector covariate can be expressed as
3
where denotes the inner product in Euclidean space, and denote the regression coefficients, and is a zero mean finite variance random error (noise). Functional linear models can be divided into two types based on the responses.
Functional regression models with scalar response
Replacing the vector covariate and the coefficient vector in model (3) by a centered functional covariate and coefficient function for and replacing the inner product in Euclidean space by that in Hilbert space, one arrives at the functional linear model
4
The simple functional linear model (4) can be extended to multiple functional covariates, , also including additional vector covariates , where , by
5
where is regression coefficient for , the domain of is , is the centered functional covariate given by , and is regression coefficient function for , for . Models (4) and (5) have been studied extensively.[10][11][12]
Functional regression models with functional response
Consider a functional response on and multiple functional covariates , , . Two major models have been considered in this setup.[13][7] One of these two models, generally referred to as functional linear model (FLM), can be written as:
6
where is the functional intercept, for , is a centered functional covariate on , is the corresponding functional slopes with same domain, respectively, and is usually a random process with mean zero and finite variance.[13] In this case, at any given time , the value of , i.e., , depends on the entire trajectories of . Model (6) has been studied extensively.[14][15][16][17][18]
Function-on-scalar regression
In particular, taking as a constant function yields a special case of model (6)which is a functional linear model with functional responses and scalar covariates.
Concurrent regression models
This model is given by
7
where are functional covariates on , are the coefficient functions defined on the same interval and is usually assumed to be a random process with mean zero and finite variance.[13] This model assumes that the value of depends on the current value of only and not the history or future value. Hence, it is a "concurrent regression model", which is also referred as "varying-coefficient" model. Further, various estimation methods have been proposed.[19][20][21][22][23][24]
Functional nonlinear regression models
Direct nonlinear extensions of the classical functional linear regression models (FLMs) still involve a linear predictor, but combine it with a nonlinear link function, analogous to the idea of generalized linear model from the conventional linear model. Developments towards fully nonparametric regression models for functional data encounter problems such as curse of dimensionality. In order to bypass the "curse" and the metric selection problem, we are motivated to consider nonlinear functional regression models, which are subject to some structural constraints but do not overly infringe flexibility. One desires models that retain polynomial rates of convergence, while being more flexible than, say, functional linear models. Such models are particularly useful when diagnostics for the functional linear model indicate lack of fit, which is often encountered in real life situations. In particular, functional polynomial models, functional single and multiple index models and functional additive models are three special cases of functional nonlinear regression models.
Functional polynomial regression models
Functional polynomial regression models may be viewed as a natural extension of the Functional Linear Models (FLMs) with scalar responses, analogous to extending linear regression model to polynomial regression model. For a scalar response and a functional covariate with domain and the corresponding centered predictor processes , the simplest and the most prominent member in the family of functional polynomial regression models is the quadratic functional regression[25] given as follows,where is the centered functional covariate, is a scalar coefficient, and are coefficient functions with domains and , respectively. In addition to the parameter function β that the above functional quadratic regression model shares with the FLM, it also features a parameter surface γ. By analogy to FLMs with scalar responses, estimation of functional polynomial models can be obtained through expanding both the centered covariate and the coefficient functions and in an orthonormal basis.[25][26]
Functional single and multiple index models
A functional multiple index model is given as below, with symbols having their usual meanings as formerly described,Here g represents an (unknown) general smooth function defined on a p-dimensional domain. The case yields a functional single index model while multiple index models correspond to the case . However, for , this model is problematic due to curse of dimensionality. With and relatively small sample sizes, the estimator given by this model often has large variance.[27][28]
Functional additive models (FAMs)
For a given orthonormal basis on , we can expand on the domain .
A functional linear model with scalar responses (see (3)) can thus be written as follows,One form of FAMs is obtained by replacing the linear function of in the above expression ( i.e., ) by a general smooth function , analogous to the extension of multiple linear regression models to additive models and is expressed as,where satisfies for .[13][7] This constraint on the general smooth functions ensures identifiability in the sense that the estimates of these additive component functions do not interfere with that of the intercept term . Another form of FAM is the continuously additive model,[29] expressed as,for a bivariate smooth additive surface which is required to satisfy for all , in order to ensure identifiability.
Link function connecting the conditional mean and the linear predictor through . [systematic component]
Clustering and classification of functional data
For vector-valued multivariate data, k-means partitioning methods and hierarchical clustering are two main approaches. These classical clustering concepts for vector-valued multivariate data have been extended to functional data. For clustering of functional data, k-means clustering methods are more popular than hierarchical clustering methods. For k-means clustering on functional data, mean functions are usually regarded as the cluster centers. Covariance structures have also been taken into consideration.[31] Besides k-means type clustering, functional clustering[32] based on mixture models is also widely used in clustering vector-valued multivariate data and has been extended to functional data clustering.[33][34][35][36][37] Furthermore, Bayesian hierarchical clustering also plays an important role in the development of model-based functional clustering.[38][39][40][41]
Functional classification assigns a group membership to a new data object either based on functional regression or functional discriminant analysis. Functional data classification methods based on functional regression models use class levels as responses and the observed functional data and other covariates as predictors. For regression based functional classification models, functional generalized linear models or more specifically, functional binary regression, such as functional logistic regression for binary responses, are commonly used classification approaches. More generally, the generalized functional linear regression model based on the FPCA approach is used.[42] Functional Linear Discriminant Analysis (FLDA) has also been considered as a classification method for functional data.[43][44][45][46][47] Functional data classification involving density ratios has also been proposed.[48] A study of the asymptotic behavior of the proposed classifiers in the large sample limit shows that under certain conditions the misclassification rate converges to zero, a phenomenon that has been referred to as "perfect classification".[49]
Time warping
Motivations
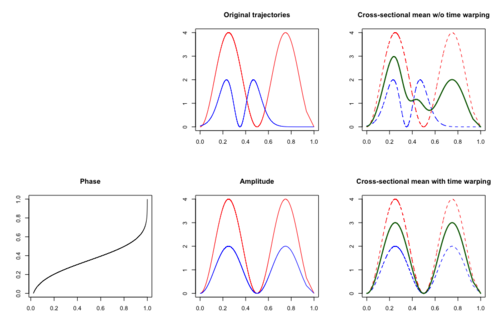
Structures in cross-sectional mean destroyed if time variation is ignored. On the contrary, structures in cross-sectional mean is well-captured after restoring time variation.
In addition to amplitude variation,[50] time variation may also be assumed to present in functional data. Time variation occurs when the subject-specific timing of certain events of interest varies among subjects. One classical example is the Berkeley Growth Study Data,[51] where the amplitude variation is the growth rate and the time variation explains the difference in children's biological age at which the pubertal and the pre-pubertal growth spurt occurred. In the presence of time variation, the cross-sectional mean function may not be an efficient estimate as peaks and troughs are located randomly and thus meaningful signals may be distorted or hidden.
Time warping, also known as curve registration,[52] curve alignment or time synchronization, aims to identify and separate amplitude variation and time variation. If both time and amplitude variation are present, then the observed functional data can be modeled as , where is a latent amplitude function and is a latent time warping function that corresponds to a cumulative distribution function. The time warping functions are assumed to be invertible and to satisfy .
The simplest case of a family of warping functions to specify phase variation is linear transformation, that is , which warps the time of an underlying template function by subjected-specific shift and scale. More general class of warping functions includes diffeomorphisms of the domain to itself, that is, loosely speaking, a class of invertible functions that maps the compact domain to itself such that both the function and its inverse are smooth. The set of linear transformation is contained in the set of diffeomorphisms.[53] One challenge in time warping is identifiability of amplitude and phase variation. Specific assumptions are required to break this non-identifiability.
Methods
Earlier approaches include dynamic time warping (DTW) used for applications such as speech recognition.[54] Another traditional method for time warping is landmark registration,[55][56] which aligns special features such as peak locations to an average location. Other relevant warping methods include pairwise warping,[57] registration using distance[53] and elastic warping.[58]
Dynamic time warping
The template function is determined through an iteration process, starting from cross-sectional mean, performing registration and recalculating the cross-sectional mean for the warped curves, expecting convergence after a few iterations. DTW minimizes a cost function through dynamic programming. Problems of non-smooth differentiable warps or greedy computation in DTW can be resolved by adding a regularization term to the cost function.
Landmark registration
Landmark registration (or feature alignment) assumes well-expressed features are present in all sample curves and uses the location of such features as a gold-standard. Special features such as peak or trough locations in functions or derivatives are aligned to their average locations on the template function.[53] Then the warping function is introduced through a smooth transformation from the average location to the subject-specific locations. A problem of landmark registration is that the features may be missing or hard to identify due to the noise in the data.
Extensions
So far we considered scalar valued stochastic process, , defined on one dimensional time domain.
Multidimensional domain of
The domain of can be in , for example the data could be a sample of random surfaces.[59][60]
Multivariate stochastic process
The range set of the stochastic process may be extended from to [61][62][63] and further to nonlinear manifolds,[64] Hilbert spaces[65] and eventually to metric spaces.[59]
There are Python packages to work with functional data, and its representation, perform exploratory analysis, or preprocessing, and among other tasks such as inference, classification, regression or clustering of functional data.
Horvath, L. and Kokoszka, P. (2012) Inference for Functional Data with Applications, New York: Springer, ISBN978-1-4614-3654-6
Hsing, T. and Eubank, R. (2015) Theoretical Foundations of Functional Data Analysis, with an Introduction to Linear Operators, Wiley series in probability and statistics, John Wiley & Sons, Ltd, ISBN978-0-470-01691-6
↑ Rice, JA; Silverman, BW. (1991). "Estimating the mean and covariance structure nonparametrically when the data are curves". Journal of the Royal Statistical Society. 53 (1): 233–243. doi:10.1111/j.2517-6161.1991.tb01821.x.
↑ Karhunen, K (1946). Zur Spektraltheorie stochastischer Prozesse. Annales Academiae scientiarum Fennicae.
↑ Kleffe, J. (1973). "Principal components of random variables with values in a seperable HILBERT space". Mathematische Operationsforschung und Statistik. 4 (5): 391–406. doi:10.1080/02331887308801137.
↑ Hsing, T; Eubank, R (2015). Theoretical Foundations of Functional Data Analysis, with an Introduction to Linear Operators. Wiley Series in Probability and Statistics.
↑ Shi, M; Weiss, RE; Taylor, JMG. (1996). "An analysis of paediatric CD4 counts for acquired immune deficiency syndrome using flexible random curves". Journal of the Royal Statistical Society. Series C (Applied Statistics). 45 (2): 151–163.
↑ Ramsay, JO; Dalzell, CJ. (1991). "Some tools for functional data analysis". Journal of the Royal Statistical Society, Series B (Methodological). 53 (3): 539–561. doi:10.1111/j.2517-6161.1991.tb01844.x. S2CID118960346.
↑ Wu, CO; Yu, KF. (2002). "Nonparametric varying-coefficient models for the analysis of longitudinal data". International Statistical Review. 70 (3): 373–393. doi:10.1111/j.1751-5823.2002.tb00176.x. S2CID122007787.
↑ Huang, JZ; Wu, CO; Zhou, L. (2002). "Varying-coefficient models and basis function approximations for the analysis of repeated measurements". Biometrika. 89 (1): 111–128. doi:10.1093/biomet/89.1.111.
↑ Huang, JZ; Wu, CO; Zhou, L. (2004). "Polynomial spline estimation and inference for varying coefficient models with longitudinal data". Statistica Sinica. 14 (3): 763–788.
↑ Şentürk, D; Müller, HG. (2010). "Functional varying coefficient models for longitudinal data". Journal of the American Statistical Association. 105 (491): 1256–1264. doi:10.1198/jasa.2010.tm09228. S2CID14296231.
↑ Eggermont, PPB; Eubank, RL; LaRiccia, VN. (2010). "Convergence rates for smoothing spline estimators in varying coefficient models". Journal of Statistical Planning and Inference. 140 (2): 369–381. doi:10.1016/j.jspi.2009.06.017.
↑ Chen, D; Hall, P; Müller HG. (2011). "Single and multiple index functional regression models with nonparametric link". The Annals of Statistics. 39 (3):1720–1747.
↑ Jiang, CR; Wang JL. (2011). "Functional single index models for longitudinal data". he Annals of Statistics. 39 (1):362–388.
↑ Müller HG; Wu Y; Yao, F. (2013). "Continuously additive models for nonlinear functional regression". Biometrika. 100 (3): 607–622. doi:10.1093/biomet/ast004.{{cite journal}}: CS1 maint: multiple names: authors list (link)
↑ James, GM; Sugar, CA. (2003). "Clustering for sparsely sampled functional data". Journal of the American Statistical Association. 98 (462): 397–408. doi:10.1198/016214503000189. S2CID9487422.
↑ Dai, X; Müller, HG; Yao, F. (2017). "Optimal Bayes classifiers for functional data and density ratios". Biometrika. 104 (3): 545–560. arXiv:1605.03707.
1 2 3 Marron, JS; Ramsay, JO; Sangalli, LM; Srivastava, A (2015). "Functional data analysis of amplitude and phase variation". Statistical Science. 30 (4): 468–484. arXiv:1512.03216. doi:10.1214/15-STS524. S2CID55849758.
↑ Sakoe, H; Chiba, S. (1978). "Dynamic programming algorithm optimization for spoken word recognition". IEEE Transactions on Acoustics, Speech, and Signal Processing. 26: 43–49. doi:10.1109/TASSP.1978.1163055. S2CID17900407.
1 2 Anirudh, R; Turaga, P; Su, J; Srivastava, A (2015). "Elastic functional coding of human actions: From vector-fields to latent variables". Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition: 3147–3155.
↑ Pigoli, D; Hadjipantelis, PZ; Coleman, JS; Aston, JAD (2017). "The statistical analysis of acoustic phonetic data: exploring differences between spoken Romance languages". Journal of the Royal Statistical Society. Series C (Applied Statistics). 67 (5): 1130–1145.
↑ Happ, C; Greven, S (2018). "Multivariate Functional Principal Component Analysis for Data Observed on Different (Dimensional) Domains". Journal of the American Statistical Association. 113 (522): 649–659. arXiv:1509.02029. doi:10.1080/01621459.2016.1273115. S2CID88521295.
↑ Chiou, JM; Yang, YF; Chen, YT (2014). "Multivariate functional principal component analysis: a normalization approach". Statistica Sinica. 24: 1571–1596.
↑ Carroll, C; Müller, HG; Kneip, A (2021). "Cross-component registration for multivariate functional data, with application to growth curves". Biometrics. 77 (3): 839–851. arXiv:1811.01429. doi:10.1111/biom.13340. S2CID220687157.
↑ Dai, X; Müller, HG (2018). "Principal component analysis for functional data on Riemannian manifolds and spheres". The Annals of Statistics. 46 (6B): 3334–3361. arXiv:1705.06226. doi:10.1214/17-AOS1660. S2CID13671221.
↑ Chen, K; Delicado, P; Müller, HG (2017). "Modelling function-valued stochastic processes, with applications to fertility dynamics". Journal of the Royal Statistical Society. Series B (Statistical Methodology). 79 (1): 177–196. doi:10.1111/rssb.12160. hdl:2117/126653. S2CID13719492.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.