
Precision Architecture RISC (PA-RISC) or Hewlett Packard Precision Architecture, is a general purpose computer instruction set architecture (ISA) developed by Hewlett-Packard from the 1980s until the 2000s.

The StrongARM is a family of computer microprocessors developed by Digital Equipment Corporation and manufactured in the late 1990s which implemented the ARM v4 instruction set architecture. It was later acquired by Intel in 1997 from DEC's own Digital Semiconductor division as part of a settlement of a lawsuit between the two companies over patent infringement. Intel then continued to manufacture it before replacing it with the StrongARM-derived ARM-based follow-up architecture called XScale in the early 2000s.
The IBM RS64 is a family of microprocessors introduced in the mid 1990s, and used in IBM's RS/6000 and AS/400 servers.

The UltraSPARC is a microprocessor developed by Sun Microsystems and fabricated by Texas Instruments, introduced in mid-1995. It is the first microprocessor from Sun to implement the 64-bit SPARC V9 instruction set architecture (ISA). Marc Tremblay was a co-microarchitect.

HP 9000 is a line of workstation and server computer systems produced by the Hewlett-Packard (HP) Company. The native operating system for almost all HP 9000 systems is HP-UX, which is based on UNIX System V.
The Runway bus is a front-side bus developed by Hewlett-Packard for use by its PA-RISC microprocessor family. The Runway bus is a 64-bit wide, split transaction, time multiplexed address and data bus running at 120 MHz. This scheme was chosen by HP as they determined that a bus using separate address and data wires would have only delivered 20% more bandwidth for a 50% increase in pin count, which would have made microprocessors using the bus more expensive. The Runway bus was introduced with the release of the PA-7200 and was subsequently used by the PA-8000, PA-8200, PA-8500, PA-8600 and PA-8700 microprocessors. Early implementations of the bus used in the PA-7200, PA-8000 and PA-8200 had a theoretical bandwidth of 960 MB/s. Beginning with the PA-8500, the Runway bus was revised to transmit on both rising and falling edges of a 125 MHz clock signal, which increased its theoretical bandwidth to 2 GB/s. The Runway bus was succeeded with the introduction of the PA-8800, which used the Itanium 2 bus.
SPARC64 is a microprocessor developed by HAL Computer Systems and fabricated by Fujitsu. It implements the SPARC V9 instruction set architecture (ISA), the first microprocessor to do so. SPARC64 was HAL's first microprocessor and was the first in the SPARC64 brand. It operates at 101 and 118 MHz. The SPARC64 was used exclusively by Fujitsu in their systems; the first systems, the Fujitsu HALstation Model 330 and Model 350 workstations, were formally announced in September 1995 and were introduced in October 1995, two years late. It was succeeded by the SPARC64 II in 1996.

The AMD Am29000, commonly shortened to 29k, is a family of 32-bit RISC microprocessors and microcontrollers developed and fabricated by Advanced Micro Devices (AMD). Based on the seminal Berkeley RISC, the 29k added a number of significant improvements. They were, for a time, the most popular RISC chips on the market, widely used in laser printers from a variety of manufacturers.

The R10000, code-named "T5", is a RISC microprocessor implementation of the MIPS IV instruction set architecture (ISA) developed by MIPS Technologies, Inc. (MTI), then a division of Silicon Graphics, Inc. (SGI). The chief designers are Chris Rowen and Kenneth C. Yeager. The R10000 microarchitecture is known as ANDES, an abbreviation for Architecture with Non-sequential Dynamic Execution Scheduling. The R10000 largely replaces the R8000 in the high-end and the R4400 elsewhere. MTI was a fabless semiconductor company; the R10000 was fabricated by NEC and Toshiba. Previous fabricators of MIPS microprocessors such as Integrated Device Technology (IDT) and three others did not fabricate the R10000 as it was more expensive to do so than the R4000 and R4400.

The R4000 is a microprocessor developed by MIPS Computer Systems that implements the MIPS III instruction set architecture (ISA). Officially announced on 1 October 1991, it was one of the first 64-bit microprocessors and the first MIPS III implementation. In the early 1990s, when RISC microprocessors were expected to replace CISC microprocessors such as the Intel i486, the R4000 was selected to be the microprocessor of the Advanced Computing Environment (ACE), an industry standard that intended to define a common RISC platform. ACE ultimately failed for a number of reasons, but the R4000 found success in the workstation and server markets.
The R8000 is a microprocessor chipset developed by MIPS Technologies, Inc. (MTI), Toshiba, and Weitek. It was the first implementation of the MIPS IV instruction set architecture. The R8000 is also known as the TFP, for Tremendous Floating-Point, its name during development.

The POWER2, originally named RIOS2, is a processor designed by IBM that implemented the POWER instruction set architecture. The POWER2 was the successor of the POWER1, debuting in September 1993 within IBM's RS/6000 systems. When introduced, the POWER2 was the fastest microprocessor, surpassing the Alpha 21064. When the Alpha 21064A was introduced in 1993, the POWER2 lost the lead and became second. IBM claimed that the performance for a 62.5 MHz POWER2 was 73.3 SPECint92 and 134.6 SPECfp92.

The VAX 8000 is a discontinued family of superminicomputers developed and manufactured by Digital Equipment Corporation (DEC) using processors implementing the VAX instruction set architecture (ISA).

The Alpha 21064 is a microprocessor developed and fabricated by Digital Equipment Corporation that implemented the Alpha instruction set architecture (ISA). It was introduced as the DECchip 21064 before it was renamed in 1994. The 21064 is also known by its code name, EV4. It was announced in February 1992 with volume availability in September 1992. The 21064 was the first commercial implementation of the Alpha ISA, and the first microprocessor from Digital to be available commercially. It was succeeded by a derivative, the Alpha 21064A in October 1993. This last version was replaced by the Alpha 21164 in 1995.

The Alpha 21164, also known by its code name, EV5, is a microprocessor developed and fabricated by Digital Equipment Corporation that implemented the Alpha instruction set architecture (ISA). It was introduced in January 1995, succeeding the Alpha 21064A as Digital's flagship microprocessor. It was succeeded by the Alpha 21264 in 1998.
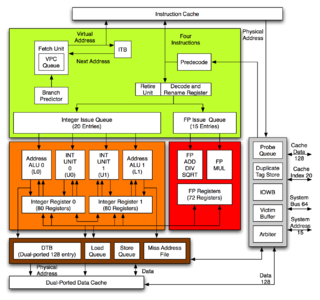
The Alpha 21264 is a RISC microprocessor developed by Digital Equipment Corporation launched on 19 October 1998. The 21264 implemented the Alpha instruction set architecture (ISA).
The SPARC64 V (Zeus) is a SPARC V9 microprocessor designed by Fujitsu. The SPARC64 V was the basis for a series of successive processors designed for servers, and later, supercomputers.
The R4200 is a microprocessor designed by MIPS Technologies, Inc. (MTI) that implemented the MIPS III instruction set architecture (ISA). It was also known as the VRX during development. The microprocessor was licensed to NEC, and the company fabricated and marketed it as the VR4200. The first VR4200, an 80 MHz part, was introduced in 1993. A faster 100 MHz part became available in 1994.
The PA-7200 – also known as PCX-T', code-named Thunderbird' –, is a microprocessor that implements the PA-RISC 1.1 instruction set architecture (ISA) developed by Hewlett-Packard (HP). It was introduced in early 1995, debuting in systems from HP. The PA-7200 was not sold openly and the only third-party users were Convex Computer and Stratus Computer, both members of the Precision RISC Organization (PRO). It was developed for small multiprocessing systems with two or four microprocessors. The microprocessor was first described at the Compcon and IEEE International Solid-State Circuits Conference (ISSCC) conferences.

The PA-7100LC is a microprocessor that implements the PA-RISC 1.1 instruction set architecture (ISA) developed by Hewlett-Packard (HP). It is also known as the PCX-L, and by its code-name, Hummingbird. It was designed as a low-cost microprocessor for low-end systems. The first systems to feature the PA-7100LC were introduced in January 1994. These systems used 60 and 80 MHz clock rates. A 100 MHz part debuted in June 1994. The PA-7100LC was the first PA-RISC microprocessor to implement the MAX-1 multimedia instructions, an early single instruction, multiple data (SIMD) multimedia instruction set extension that provided instructions for improving the performance of MPEG video decoding.









