
Solenoid protein domains are a highly modular type of protein domain. They consist of a chain of nearly identical folds, often simply called tandem repeats. They are extremely common among all types of proteins, though exact figures are unknown. [1]
Solenoid protein domains are a highly modular type of protein domain. They consist of a chain of nearly identical folds, often simply called tandem repeats. They are extremely common among all types of proteins, though exact figures are unknown. [1]
In proteins, a "repeat" is any sequence block that returns more than one time in the sequence, either in an identical or a highly similar form. Repetitiveness does not in itself indicate anything about the structure of the protein. As a "rule of thumb", short repetitive sequences (e.g. those below the length of 10 amino acids) may be intrinsically disordered, and not part of any folded protein domains. Repeats that are at least 30 to 40 amino acids long, are far more likely to be folded as part of a domain. Such long repeats are frequently indicative of the presence of a solenoid domain in the protein.
Examples of disordered repetitive sequences include the 7-mer peptide repeats found in the RPB1 subunit of RNA polymerase II, [2] or the tandem beta-catenin or axin binding linear motifs in APC (adenomatous polyposis coli). [3] Examples of short repeats exhibiting ordered structures include the three-residue collagen repeat or the five-residue pentapeptide repeat that forms a beta helix structure.
Due to the identical form of their building blocks, solenoid domains can only assume a limited number of shapes. Two main topologies are possible: linear (or open, generally with some degree of helical curvature) and circular (or closed). [4]

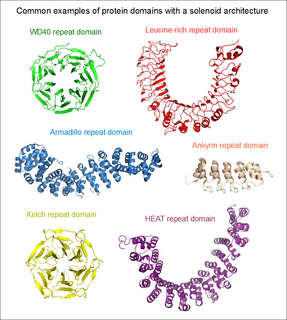
If the two terminal repeats in a solenoid do not physically interact, it leads to an open or linear structure. Members of this group are frequently rod- or crescent-shaped. The number of individual repeats can range from 2 to over 50. A clear advantage of this topology is that both the N- and C-terminal ends are free to add new repeats and folds, or even remove existing ones during evolution without any gross impact on the structural stability of the entire domain. [5] This type of domain is extremely common among extracellular segments of receptors or cell adhesion molecules. A non-exhaustive list of examples include: EGF repeats, cadherin repeats, leucine-rich repeats, HEAT repeats, ankyrin repeats, armadillo repeats, tetratricopeptide repeats, etc. Whenever a linear solenoid domain structure participates in protein-protein interactions, frequently at least 3 or more repetitive subunits form the ligand-binding sites. Thus - while individual repeats might have a (limited) ability to fold on their own – they usually cannot perform the functions of the entire domain alone.

In the case when the N- and C-terminal repeats lie in close physical contact in a solenoid domain, the result is a topologically compact, closed structure. Such domains typically display a high rotational symmetry (unlike open solenoids that only have translational symmetries), and assume a wheel-like shape. Because of the limitations of this structure, the number of individual repeats is not arbitrary. In the case of WD40 repeats (perhaps the largest family of closed solenoids) the number of repeats can range from 4 to 10 (more usually between 5 and 7). [6] Kelch repeats, beta-barrels and beta-trefoil repeats are further examples for this architecture. Closed solenoids frequently function as protein-protein interaction modules: it is possible that all repeats must be present to form the ligand-binding site if it is located at the centre or axis of the domain "wheel".

As common in biology, there are several borderline cases between solenoid architectures and regular protein domains. Proteins that contain tandem repeats of ordinary domains are very common in eukaryotes. Even if these domains are perfectly capable of folding on their own, some of them might bind together and assume a rigidly fixed orientation in the full protein. These supradomain modules can perform functions that its individual constituents are incapable of . [7] A famous example is the case of tandem BRCT domains, found in the tumor suppressor protein BRCA1. [8] While individual BRCT domains are found in certain proteins (e.g. some DNA ligases) binding DNA, these tandem BRCT domains evolved a novel function: phosphorylated linear motif binding. [9] [10] In the case of BRCA1 (and MDC1), the peptide-binding groove lies in a cleft formed by the junction of the two domains. This elegantly explains why individual constituents of this supradomain block are incapable of ligand binding, while their proper assembly endows them with a novel function. Therefore, tandem BRCT domains can be regarded as a form of a single, linear solenoid domain as well.
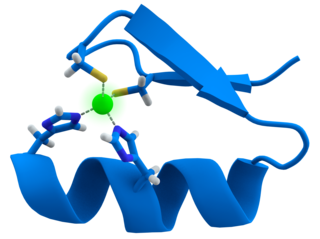
A zinc finger is a small protein structural motif that is characterized by the coordination of one or more zinc ions (Zn2+) in order to stabilize the fold. Originally coined to describe the finger-like appearance of a hypothesized structure from Xenopus laevis transcription factor IIIA, the zinc finger name has now come to encompass a wide variety of differing protein structures. Xenopus laevis TFIIIA was originally demonstrated to contain zinc and require the metal for function in 1983, the first such reported zinc requirement for a gene regulatory protein. It often appears as a metal-binding domain in multi-domain proteins.
In a chain-like biological molecule, such as a protein or nucleic acid, a structural motif is a supersecondary structure, which also appears in a variety of other molecules. Motifs do not allow us to predict the biological functions: they are found in proteins and enzymes with dissimilar functions.

In structural biology, a beta-propeller is a type of all-β protein architecture characterized by 4 to 8 highly symmetrical blade-shaped beta sheets arranged toroidally around a central axis. Together the beta-sheets form a funnel-like active site.

The ankyrin repeat is a 33-residue motif in proteins consisting of two alpha helices separated by loops, first discovered in signaling proteins in yeast Cdc10 and Drosophila Notch. Domains consisting of ankyrin tandem repeats mediate protein–protein interactions and are among the most common structural motifs in known proteins. They appear in bacterial, archaeal, and eukaryotic proteins, but are far more common in eukaryotes. Ankyrin repeat proteins, though absent in most viruses, are common among poxviruses. Most proteins that contain the motif have four to six repeats, although its namesake ankyrin contains 24, and the largest known number of repeats is 34, predicted in a protein expressed by Giardia lamblia.
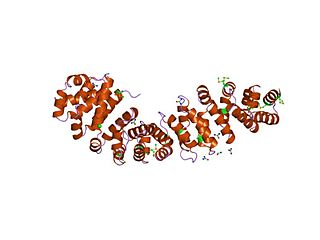
An armadillo repeat is the name of a characteristic, repetitive amino acid sequence of about 40 residues in length that is found in many proteins. Proteins that contain armadillo repeats typically contain several tandemly repeated copies. Each armadillo repeat is composed of a pair of alpha helices that form a hairpin structure. Multiple copies of the repeat form what is known as an alpha solenoid structure.

An alpha solenoid is a protein fold composed of repeating alpha helix subunits, commonly helix-turn-helix motifs, arranged in antiparallel fashion to form a superhelix. Alpha solenoids are known for their flexibility and plasticity. Like beta propellers, alpha solenoids are a form of solenoid protein domain commonly found in the proteins comprising the nuclear pore complex. They are also common in membrane coat proteins known as coatomers, such as clathrin, and in regulatory proteins that form extensive protein-protein interactions with their binding partners. Examples of alpha solenoid structures binding RNA and lipids have also been described.

A leucine-rich repeat (LRR) is a protein structural motif that forms an α/β horseshoe fold. It is composed of repeating 20–30 amino acid stretches that are unusually rich in the hydrophobic amino acid leucine. These tandem repeats commonly fold together to form a solenoid protein domain, termed leucine-rich repeat domain. Typically, each repeat unit has beta strand-turn-alpha helix structure, and the assembled domain, composed of many such repeats, has a horseshoe shape with an interior parallel beta sheet and an exterior array of helices. One face of the beta sheet and one side of the helix array are exposed to solvent and are therefore dominated by hydrophilic residues. The region between the helices and sheets is the protein's hydrophobic core and is tightly sterically packed with leucine residues.

A protein domain is a conserved part of a given protein sequence and tertiary structure that can evolve, function, and exist independently of the rest of the protein chain. Each domain forms a compact three-dimensional structure and often can be independently stable and folded. Many proteins consist of several structural domains. One domain may appear in a variety of different proteins. Molecular evolution uses domains as building blocks and these may be recombined in different arrangements to create proteins with different functions. In general, domains vary in length from between about 50 amino acids up to 250 amino acids in length. The shortest domains, such as zinc fingers, are stabilized by metal ions or disulfide bridges. Domains often form functional units, such as the calcium-binding EF hand domain of calmodulin. Because they are independently stable, domains can be "swapped" by genetic engineering between one protein and another to make chimeric proteins.

The EGF-like domain is an evolutionary conserved protein domain, which derives its name from the epidermal growth factor where it was first described. It comprises about 30 to 40 amino-acid residues and has been found in a large number of mostly animal proteins. Most occurrences of the EGF-like domain are found in the extracellular domain of membrane-bound proteins or in proteins known to be secreted. An exception to this is the prostaglandin-endoperoxide synthase. The EGF-like domain includes 6 cysteine residues which in the epidermal growth factor have been shown to form 3 disulfide bonds. The structures of 4-disulfide EGF-domains have been solved from the laminin and integrin proteins. The main structure of EGF-like domains is a two-stranded β-sheet followed by a loop to a short C-terminal, two-stranded β-sheet. These two β-sheets are usually denoted as the major (N-terminal) and minor (C-terminal) sheets. EGF-like domains frequently occur in numerous tandem copies in proteins: these repeats typically fold together to form a single, linear solenoid domain block as a functional unit.

Neurexin-1-alpha is a protein that in humans is encoded by the NRXN1 gene.

The tetratricopeptide repeat (TPR) is a structural motif. It consists of a degenerate 34 amino acid tandem repeat identified in a wide variety of proteins. It is found in tandem arrays of 3–16 motifs, which form scaffolds to mediate protein–protein interactions and often the assembly of multiprotein complexes. These alpha-helix pair repeats usually fold together to produce a single, linear solenoid domain called a TPR domain. Proteins with such domains include the anaphase-promoting complex (APC) subunits cdc16, cdc23 and cdc27, the NADPH oxidase subunit p67-phox, hsp90-binding immunophilins, transcription factors, the protein kinase R (PKR), the major receptor for peroxisomal matrix protein import PEX5, protein arginine methyltransferase 9 (PRMT9), and mitochondrial import proteins.

The WW domain, is a modular protein domain that mediates specific interactions with protein ligands. This domain is found in a number of unrelated signaling and structural proteins and may be repeated up to four times in some proteins. Apart from binding preferentially to proteins that are proline-rich, with particular proline-motifs, [AP]-P-P-[AP]-Y, some WW domains bind to phosphoserine- phosphothreonine-containing motifs.
The Kelch motif is a region of protein sequence found widely in proteins from bacteria and eukaryotes. This sequence motif is composed of about 50 amino acid residues which form a structure of a four stranded beta-sheet "blade". This sequence motif is found in between five and eight tandem copies per protein which fold together to form a larger circular solenoid structure called a beta-propeller domain.

A circular permutation is a relationship between proteins whereby the proteins have a changed order of amino acids in their peptide sequence. The result is a protein structure with different connectivity, but overall similar three-dimensional (3D) shape. In 1979, the first pair of circularly permuted proteins – concanavalin A and lectin – were discovered; over 2000 such proteins are now known.

The EVH1 domain is an evolutionary conserved protein domain.

In molecular biology, a carbohydrate-binding module (CBM) is a protein domain found in carbohydrate-active enzymes. The majority of these domains have carbohydrate-binding activity. Some of these domains are found on cellulosomal scaffoldin proteins. CBMs were previously known as cellulose-binding domains. CBMs are classified into numerous families, based on amino acid sequence similarity. There are currently 64 families of CBM in the CAZy database.

In molecular biology, the GYF domain is an approximately 60-amino acid protein domain which contains a conserved GP[YF]xxxx[MV]xxWxxx[GN]YF motif. It was identified in the human intracellular protein termed CD2 binding protein 2 (CD2BP2), which binds to a site containing two tandem PPPGHR segments within the cytoplasmic region of CD2. Binding experiments and mutational analyses have demonstrated the critical importance of the GYF tripeptide in ligand binding. A GYF domain is also found in several other eukaryotic proteins of unknown function. It has been proposed that the GYF domain found in these proteins could also be involved in proline-rich sequence recognition. Resolution of the structure of the CD2BP2 GYF domain by NMR spectroscopy revealed a compact domain with a beta-beta-alpha-beta-beta topology, where the single alpha-helix is tilted away from the twisted, anti-parallel beta-sheet. The conserved residues of the GYF domain create a contiguous patch of predominantly hydrophobic nature which forms an integral part of the ligand-binding site. There is limited homology within the C-terminal 20-30 amino acids of various GYF domains, supporting the idea that this part of the domain is structurally but not functionally important.
An array of protein tandem repeats is defined as several adjacent copies having the same or similar sequence motifs. These periodic sequences are generated by internal duplications in both coding and non-coding genomic sequences. Repetitive units of protein tandem repeats are considerably diverse, ranging from the repetition of a single amino acid to domains of 100 or more residues.

A toroid repeat is a protein fold composed of repeating subunits, arranged in circular fashion to form a closed structure.