Natural language processing (NLP) is an interdisciplinary subfield of computer science and artificial intelligence. It is primarily concerned with providing computers with the ability to process data encoded in natural language and is thus closely related to information retrieval, knowledge representation and computational linguistics, a subfield of linguistics. Typically data is collected in text corpora, using either rule-based, statistical or neural-based approaches in machine learning and deep learning.
A hidden Markov model (HMM) is a Markov model in which the observations are dependent on a latent Markov process. An HMM requires that there be an observable process whose outcomes depend on the outcomes of in a known way. Since cannot be observed directly, the goal is to learn about state of by observing . By definition of being a Markov model, an HMM has an additional requirement that the outcome of at time must be "influenced" exclusively by the outcome of at and that the outcomes of and at must be conditionally independent of at given at time . Estimation of the parameters in an HMM can be performed using maximum likelihood estimation. For linear chain HMMs, the Baum–Welch algorithm can be used to estimate parameters.
In statistics, Markov chain Monte Carlo (MCMC) is a class of algorithms used to draw samples from a probability distribution. Given a probability distribution, one can construct a Markov chain whose elements' distribution approximates it – that is, the Markov chain's equilibrium distribution matches the target distribution. The more steps that are included, the more closely the distribution of the sample matches the actual desired distribution.
Head-driven phrase structure grammar (HPSG) is a highly lexicalized, constraint-based grammar developed by Carl Pollard and Ivan Sag. It is a type of phrase structure grammar, as opposed to a dependency grammar, and it is the immediate successor to generalized phrase structure grammar. HPSG draws from other fields such as computer science and uses Ferdinand de Saussure's notion of the sign. It uses a uniform formalism and is organized in a modular way which makes it attractive for natural language processing.
Stochastic is the property of being well-described by a random probability distribution. Stochasticity and randomness are distinct, in that the former refers to a modeling approach and the latter refers to phenomena; these terms are often used synonymously. In probability theory, the formal concept of a stochastic process is also referred to as a random process.
In theoretical linguistics and computational linguistics, probabilistic context free grammars (PCFGs) extend context-free grammars, similar to how hidden Markov models extend regular grammars. Each production is assigned a probability. The probability of a derivation (parse) is the product of the probabilities of the productions used in that derivation. These probabilities can be viewed as parameters of the model, and for large problems it is convenient to learn these parameters via machine learning. A probabilistic grammar's validity is constrained by context of its training dataset.
Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. The term parsing comes from Latin pars (orationis), meaning part.
Link grammar (LG) is a theory of syntax by Davy Temperley and Daniel Sleator which builds relations between pairs of words, rather than constructing constituents in a phrase structure hierarchy. Link grammar is similar to dependency grammar, but dependency grammar includes a head-dependent relationship, whereas link grammar makes the head-dependent relationship optional. Colored Multiplanar Link Grammar (CMLG) is an extension of LG allowing crossing relations between pairs of words. The relationship between words is indicated with link types, thus making the Link grammar closely related to certain categorial grammars.
In corpus linguistics, part-of-speech tagging, also called grammatical tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context. A simplified form of this is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc.
An augmented transition network or ATN is a type of graph theoretic structure used in the operational definition of formal languages, used especially in parsing relatively complex natural languages, and having wide application in artificial intelligence. An ATN can, theoretically, analyze the structure of any sentence, however complicated. ATN are modified transition networks and an extension of RTNs.
Grammar induction is the process in machine learning of learning a formal grammar from a set of observations, thus constructing a model which accounts for the characteristics of the observed objects. More generally, grammatical inference is that branch of machine learning where the instance space consists of discrete combinatorial objects such as strings, trees and graphs.
Statistical machine translation (SMT) was a machine translation approach, that superseded the previous, rule-based approach because it required explicit description of each and every linguistic rule, which was costly, and which often did not generalize to other languages. Since 2003, the statistical approach itself has been gradually superseded by the deep learning-based neural machine translation.
Structured prediction or structured (output) learning is an umbrella term for supervised machine learning techniques that involves predicting structured objects, rather than scalar discrete or real values.
Statistical language acquisition, a branch of developmental psycholinguistics, studies the process by which humans develop the ability to perceive, produce, comprehend, and communicate with natural language in all of its aspects through the use of general learning mechanisms operating on statistical patterns in the linguistic input. Statistical learning acquisition claims that infants' language-learning is based on pattern perception rather than an innate biological grammar. Several statistical elements such as frequency of words, frequent frames, phonotactic patterns and other regularities provide information on language structure and meaning for facilitation of language acquisition.
The following outline is provided as an overview of and topical guide to natural-language processing:
Stochastic cellular automata or probabilistic cellular automata (PCA) or random cellular automata or locally interacting Markov chains are an important extension of cellular automaton. Cellular automata are a discrete-time dynamical system of interacting entities, whose state is discrete.
The following outline is provided as an overview of and topical guide to machine learning:
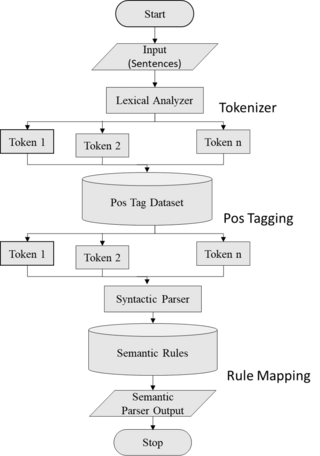
Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
Syntactic parsing is the automatic analysis of syntactic structure of natural language, especially syntactic relations and labelling spans of constituents. It is motivated by the problem of structural ambiguity in natural language: a sentence can be assigned multiple grammatical parses, so some kind of knowledge beyond computational grammar rules is needed to tell which parse is intended. Syntactic parsing is one of the important tasks in computational linguistics and natural language processing, and has been a subject of research since the mid-20th century with the advent of computers.