In anatomy, a crystallin is a water-soluble structural protein found in the lens and the cornea of the eye accounting for the transparency of the structure. It has also been identified in other places such as the heart, and in aggressive breast cancer tumors. Since it has been shown that lens injury may promote nerve regeneration, crystallin has been an area of neural research. So far, it has been demonstrated that crystallin β b2 (crybb2) may be a neurite-promoting factor.

Cellulase is any of several enzymes produced chiefly by fungi, bacteria, and protozoans that catalyze cellulolysis, the decomposition of cellulose and of some related polysaccharides. The name is also used for any naturally occurring mixture or complex of various such enzymes, that act serially or synergistically to decompose cellulosic material.
DNA primase is an enzyme involved in the replication of DNA and is a type of RNA polymerase. Primase catalyzes the synthesis of a short RNA segment called a primer complementary to a ssDNA template. After this elongation, the RNA piece is removed by a 5' to 3' exonuclease and refilled with DNA.
A DNA-binding domain (DBD) is an independently folded protein domain that contains at least one structural motif that recognizes double- or single-stranded DNA. A DBD can recognize a specific DNA sequence or have a general affinity to DNA. Some DNA-binding domains may also include nucleic acids in their folded structure.
Protein–protein interaction prediction is a field combining bioinformatics and structural biology in an attempt to identify and catalog physical interactions between pairs or groups of proteins. Understanding protein–protein interactions is important for the investigation of intracellular signaling pathways, modelling of protein complex structures and for gaining insights into various biochemical processes.

The TIM barrel, also known as an alpha/beta barrel, is a conserved protein fold consisting of eight alpha helices (α-helices) and eight parallel beta strands (β-strands) that alternate along the peptide backbone. The structure is named after triose-phosphate isomerase, a conserved metabolic enzyme. TIM barrels are ubiquitous, with approximately 10% of all enzymes adopting this fold. Further, five of seven enzyme commission (EC) enzyme classes include TIM barrel proteins. The TIM barrel fold is evolutionarily ancient, with many of its members possessing little similarity today, instead falling within the twilight zone of sequence similarity.
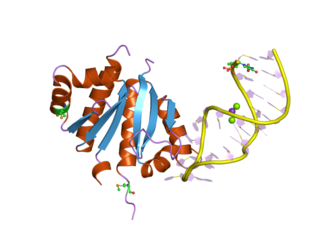
The K Homology (KH) domain is a protein domain that was first identified in the human heterogeneous nuclear ribonucleoprotein (hnRNP) K. An evolutionarily conserved sequence of around 70 amino acids, the KH domain is present in a wide variety of nucleic acid-binding proteins. The KH domain binds RNA, and can function in RNA recognition. It is found in multiple copies in several proteins, where they can function cooperatively or independently. For example, in the AU-rich element RNA-binding protein KSRP, which has 4 KH domains, KH domains 3 and 4 behave as independent binding modules to interact with different regions of the AU-rich RNA targets. The solution structure of the first KH domain of FMR1 and of the C-terminal KH domain of hnRNP K determined by nuclear magnetic resonance (NMR) revealed a beta-alpha-alpha-beta-beta-alpha structure. Autoantibodies to NOVA1, a KH domain protein, cause paraneoplastic opsoclonus ataxia. The KH domain is found at the N-terminus of the ribosomal protein S3. This domain is unusual in that it has a different fold compared to the normal KH domain.

In enzymology, a microsomal epoxide hydrolase (mEH) is an enzyme that catalyzes the hydrolysis reaction between an epoxide and water to form a diol.
Exopolyphosphatase (PPX) is a phosphatase enzyme which catalyzes the hydrolysis of inorganic polyphosphate, a linear molecule composed of up to 1000 or more monomers linked by phospho-anhydride bonds. PPX is a processive exophosphatase, which means that it begins at the ends of the polyphosphate chain and cleaves the phospho-anhydride bonds to release orthophosphate as it moves along the polyphosphate molecule. PPX has several characteristics which distinguish it from other known polyphosphatases, namely that it does not act on ATP, has a strong preference for long chain polyphosphate, and has a very low affinity for polyphosphate molecules with less than 15 phosphate monomers.
In enzymology, an IMP cyclohydrolase (EC 3.5.4.10) is an enzyme that catalyzes the chemical reaction

Enhancer of mRNA-decapping protein 3 is a protein that in humans is encoded by the EDC3 gene.

Chromosome 11 open reading frame 54 (C11orf54) is a protein that in humans is encoded by the C11orf54 gene. The "Homo sapiens" gene, C11orf54 is also known as PTD012 and PTOD12. C11orf54 exhibits hydrolase activity on p-nitrophenyl acetate and acts on ester bonds, though the overall function is still not fully understood by the scientific community. The protein is highly conserved with the most distant homolog found is in bacteria.

The mRNA decapping complex is a protein complex in eukaryotic cells responsible for removal of the 5' cap. The active enzyme of the decapping complex is the bilobed Nudix family enzyme Dcp2, which hydrolyzes 5' cap and releases 7mGDP and a 5'-monophosphorylated mRNA. This decapped mRNA is inhibited for translation and will be degraded by exonucleases. The core decapping complex is conserved in eukaryotes. Dcp2 is activated by Decapping Protein 1 (Dcp1) and in higher eukaryotes joined by the scaffold protein VCS. Together with many other accessory proteins, the decapping complex assembles in P-bodies in the cytoplasm.

S-Adenosylmethionine synthetase, also known as methionine adenosyltransferase (MAT), is an enzyme that creates S-adenosylmethionine by reacting methionine and ATP.

In molecular biology, the CRM domain is an approximately 100-amino acid RNA-binding domain. The name CRM has been suggested to reflect the functions established for four characterised members of the family: Zea mays (Maize) CRS1, CAF1 and CAF2 proteins and the Escherichia coli protein YhbY. Proteins containing the CRM domain are found in eubacteria, archaea, and plants. The CRM domain is represented as a stand-alone protein in archaea and bacteria, and in single- and multi-domain proteins in plants. It has been suggested that prokaryotic CRM proteins existed as ribosome-associated proteins prior to the divergence of archaea and bacteria, and that they were co-opted in the plant lineage as RNA binding modules by incorporation into diverse protein contexts. Plant CRM domains are predicted to reside not only in the chloroplast, but also in the mitochondrion and the nucleo/cytoplasmic compartment. The diversity of the CRM domain family in plants suggests a diverse set of RNA targets.

In molecular biology, Glycoside hydrolase family 14 is a family of glycoside hydrolases.
In molecular biology, glycoside hydrolase family 89 is a family of glycoside hydrolases.

In molecular biology, glycoside hydrolase family 36 is a family of glycoside hydrolases.
A protein superfamily is the largest grouping (clade) of proteins for which common ancestry can be inferred. Usually this common ancestry is inferred from structural alignment and mechanistic similarity, even if no sequence similarity is evident. Sequence homology can then be deduced even if not apparent. Superfamilies typically contain several protein families which show sequence similarity within each family. The term protein clan is commonly used for protease and glycosyl hydrolases superfamilies based on the MEROPS and CAZy classification systems.

5',3'-nucleotidase, mitochondrial, also known as 5'(3')-deoxyribonucleotidase, mitochondrial (mdN) or deoxy-5'-nucleotidase 2 (dNT-2), is an enzyme that in humans is encoded by the NT5M gene. This gene encodes a 5' nucleotidase that localizes to the mitochondrial matrix. This enzyme dephosphorylates the 5'- and 2'(3')-phosphates of uracil and thymine deoxyribonucleotides. The gene is located within the Smith–Magenis syndrome region on chromosome 17.
