In statistics, an estimator is a rule for calculating an estimate of a given quantity based on observed data: thus the rule, the quantity of interest and its result are distinguished. For example, the sample mean is a commonly used estimator of the population mean.

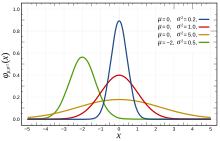
In probability theory and statistics, a probability distribution is the mathematical function that gives the probabilities of occurrence of different possible outcomes for an experiment. It is a mathematical description of a random phenomenon in terms of its sample space and the probabilities of events.

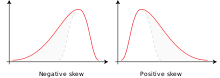
In probability theory and statistics, skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean. The skewness value can be positive, zero, negative, or undefined.
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss. The fact that MSE is almost always strictly positive is because of randomness or because the estimator does not account for information that could produce a more accurate estimate. In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk, as an estimate of the true MSE.

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.

In probability theory and statistics, the gamma distribution is a versatile two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter k and a scale parameter θ
- With a shape parameter and an inverse scale parameter , called a rate parameter.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
In statistics, a generalized linear model (GLM) is a flexible generalization of ordinary linear regression. The GLM generalizes linear regression by allowing the linear model to be related to the response variable via a link function and by allowing the magnitude of the variance of each measurement to be a function of its predicted value.

In statistics, a consistent estimator or asymptotically consistent estimator is an estimator—a rule for computing estimates of a parameter θ0—having the property that as the number of data points used increases indefinitely, the resulting sequence of estimates converges in probability to θ0. This means that the distributions of the estimates become more and more concentrated near the true value of the parameter being estimated, so that the probability of the estimator being arbitrarily close to θ0 converges to one.
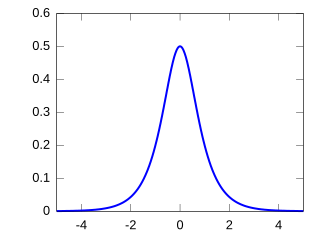
In probability theory and statistics, the hyperbolic secant distribution is a continuous probability distribution whose probability density function and characteristic function are proportional to the hyperbolic secant function. The hyperbolic secant function is equivalent to the reciprocal hyperbolic cosine, and thus this distribution is also called the inverse-cosh distribution.
In statistics, Poisson regression is a generalized linear model form of regression analysis used to model count data and contingency tables. Poisson regression assumes the response variable Y has a Poisson distribution, and assumes the logarithm of its expected value can be modeled by a linear combination of unknown parameters. A Poisson regression model is sometimes known as a log-linear model, especially when used to model contingency tables.
In statistics, binomial regression is a regression analysis technique in which the response has a binomial distribution: it is the number of successes in a series of independent Bernoulli trials, where each trial has probability of success . In binomial regression, the probability of a success is related to explanatory variables: the corresponding concept in ordinary regression is to relate the mean value of the unobserved response to explanatory variables.
In the statistical area of survival analysis, an accelerated failure time model is a parametric model that provides an alternative to the commonly used proportional hazards models. Whereas a proportional hazards model assumes that the effect of a covariate is to multiply the hazard by some constant, an AFT model assumes that the effect of a covariate is to accelerate or decelerate the life course of a disease by some constant. There is strong basic science evidence from C. Elegans experiments by Stroustrup et al. indicating that AFT models are the correct model for biological survival processes.
In statistics, efficiency is a measure of quality of an estimator, of an experimental design, or of a hypothesis testing procedure. Essentially, a more efficient estimator needs fewer input data or observations than a less efficient one to achieve the Cramér–Rao bound. An efficient estimator is characterized by having the smallest possible variance, indicating that there is a small deviance between the estimated value and the "true" value in the L2 norm sense.
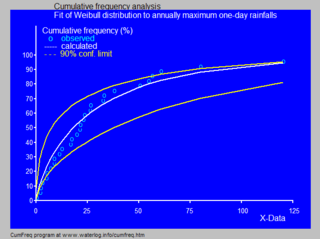
In statistics and data analysis the application software CumFreq is a tool for cumulative frequency analysis of a single variable and for probability distribution fitting.

In probability theory and statistics, the beta rectangular distribution is a probability distribution that is a finite mixture distribution of the beta distribution and the continuous uniform distribution. The support is of the distribution is indicated by the parameters a and b, which are the minimum and maximum values respectively. The distribution provides an alternative to the beta distribution such that it allows more density to be placed at the extremes of the bounded interval of support. Thus it is a bounded distribution that allows for outliers to have a greater chance of occurring than does the beta distribution.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
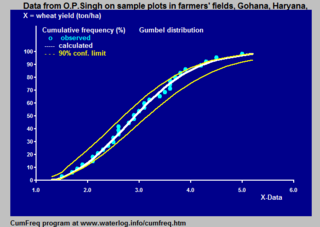
Cumulative frequency analysis is the analysis of the frequency of occurrence of values of a phenomenon less than a reference value. The phenomenon may be time- or space-dependent. Cumulative frequency is also called frequency of non-exceedance.
In statistics, the class of vector generalized linear models (VGLMs) was proposed to enlarge the scope of models catered for by generalized linear models (GLMs). In particular, VGLMs allow for response variables outside the classical exponential family and for more than one parameter. Each parameter can be transformed by a link function. The VGLM framework is also large enough to naturally accommodate multiple responses; these are several independent responses each coming from a particular statistical distribution with possibly different parameter values.