The likelihood function is the joint probability of observed data viewed as a function of the parameters of a statistical model.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In probability theory and statistics, the gamma distribution is a two-parameter family of continuous probability distributions. The exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the gamma distribution. There are two equivalent parameterizations in common use:
- With a shape parameter k and a scale parameter θ
- With a shape parameter and an inverse scale parameter , called a rate parameter.
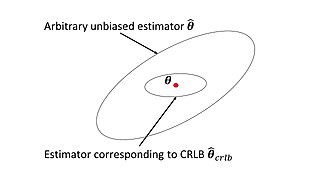
In estimation theory and statistics, the Cramér–Rao bound (CRB) relates to estimation of a deterministic parameter. The result is named in honor of Harald Cramér and C. R. Rao, but has also been derived independently by Maurice Fréchet, Georges Darmois, and by Alexander Aitken and Harold Silverstone. It states that the precision of any unbiased estimator is at most the Fisher information; or (equivalently) the reciprocal of the Fisher information is a lower bound on its variance.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
Estimation theory is a branch of statistics that deals with estimating the values of parameters based on measured empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation theory, two approaches are generally considered:
In Bayesian statistics, a maximum a posteriori probability (MAP) estimate is an estimate of an unknown quantity, that equals the mode of the posterior distribution. The MAP can be used to obtain a point estimate of an unobserved quantity on the basis of empirical data. It is closely related to the method of maximum likelihood (ML) estimation, but employs an augmented optimization objective which incorporates a prior distribution over the quantity one wants to estimate. MAP estimation can therefore be seen as a regularization of maximum likelihood estimation.
In econometrics and statistics, the generalized method of moments (GMM) is a generic method for estimating parameters in statistical models. Usually it is applied in the context of semiparametric models, where the parameter of interest is finite-dimensional, whereas the full shape of the data's distribution function may not be known, and therefore maximum likelihood estimation is not applicable.
In statistics, the method of moments is a method of estimation of population parameters. The same principle is used to derive higher moments like skewness and kurtosis.
In statistics, the Bayesian information criterion (BIC) or Schwarz information criterion is a criterion for model selection among a finite set of models; models with lower BIC are generally preferred. It is based, in part, on the likelihood function and it is closely related to the Akaike information criterion (AIC).
The James–Stein estimator is a biased estimator of the mean, , of (possibly) correlated Gaussian distributed random variables with unknown means .
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
Location estimation in wireless sensor networks is the problem of estimating the location of an object from a set of noisy measurements. These measurements are acquired in a distributed manner by a set of sensors.
Minimum-distance estimation (MDE) is a conceptual method for fitting a statistical model to data, usually the empirical distribution. Often-used estimators such as ordinary least squares can be thought of as special cases of minimum-distance estimation.

In probability theory and directional statistics, a wrapped Cauchy distribution is a wrapped probability distribution that results from the "wrapping" of the Cauchy distribution around the unit circle. The Cauchy distribution is sometimes known as a Lorentzian distribution, and the wrapped Cauchy distribution may sometimes be referred to as a wrapped Lorentzian distribution.
In probability theory and statistics, empirical likelihood (EL) is a nonparametric method for estimating the parameters of statistical models. It requires fewer assumptions about the error distribution while retaining some of the merits in likelihood-based inference. The estimation method requires that the data are independent and identically distributed (iid). It performs well even when the distribution is asymmetric or censored. EL methods can also handle constraints and prior information on parameters. Art Owen pioneered work in this area with his 1988 paper.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
In statistics, the variance function is a smooth function that depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.