With a shape parameter and an inverse scale parameter , called a rate parameter.
In each of these forms, both parameters are positive real numbers.
The distribution has significant applications across various fields, including econometrics, Bayesian statistics, life testing. In econometrics, the (k, θ) parameterization is common for modeling waiting times, such as the time until death, where it often takes the form of an Erlang distribution for integer k values. Bayesian statistics prefer the (α, β) parameterization, utilizing the gamma distribution as a conjugate prior for several inverse scale parameters, facilitating analytical tractability in posterior distribution computations. The probability density and cumulative distribution functions of the gamma distribution vary based on the chosen parameterization, both offering insights into the behavior of gamma-distributed random variables. The gamma distribution is integral to modeling a range of phenomena due to its flexible shape, which can capture various statistical distributions, including the exponential and chi-squared distributions under specific conditions. Its mathematical properties, such as mean, variance, skewness, and higher moments, provide a toolset for statistical analysis and inference. Practical applications of the distribution span several disciplines, underscoring its importance in theoretical and applied statistics.
The gamma distribution is the maximum entropy probability distribution (both with respect to a uniform base measure and a base measure) for a random variable X for which E[X] = kθ = α/β is fixed and greater than zero, and E[ln X] = ψ(k) + ln θ = ψ(α) − ln β is fixed (ψ is the digamma function).[1]
Definitions
The parameterization with k and θ appears to be more common in econometrics and other applied fields, where the gamma distribution is frequently used to model waiting times. For instance, in life testing, the waiting time until death is a random variable that is frequently modeled with a gamma distribution. See Hogg and Craig[2] for an explicit motivation.
The gamma distribution can be parameterized in terms of a shape parameterα = k and an inverse scale parameter β = 1/θ, called a rate parameter. A random variable X that is gamma-distributed with shape α and rate β is denoted
The corresponding probability density function in the shape-rate parameterization is
where is the gamma function. For all positive integers, .
If α is a positive integer (i.e., the distribution is an Erlang distribution), the cumulative distribution function has the following series expansion:[4]
Characterization using shape k and scale θ
A random variable X that is gamma-distributed with shape k and scale θ is denoted by
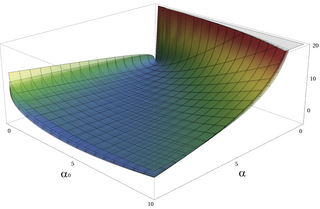
Illustration of the gamma PDF for parameter values over k and x with θ set to 1, 2, 3, 4, 5, and6. One can see each θ layer by itself here as well as byk andx. .
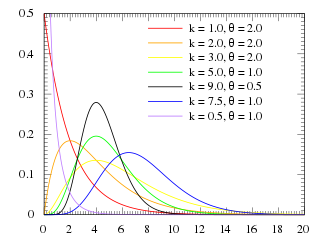
Bounds and asymptotic approximations to the median of the gamma distribution. The cyan-colored region indicates the large gap between published lower and upper bounds.
Unlike the mode and the mean, which have readily calculable formulas based on the parameters, the median does not have a closed-form equation. The median for this distribution is the value ν such that
A rigorous treatment of the problem of determining an asymptotic expansion and bounds for the median of the gamma distribution was handled first by Chen and Rubin, who proved that (for )
where is the mean and is the median of the distribution.[5] For other values of the scale parameter, the mean scales to , and the median bounds and approximations would be similarly scaled by θ.
K. P. Choi found the first five terms in a Laurent series asymptotic approximation of the median by comparing the median to Ramanujan's function.[6] Berg and Pedersen found more terms:[7]
Two gamma distribution median asymptotes which were proved in 2023 to be bounds (upper solid red and lower dashed red), of the from , and an interpolation between them that makes an approximation (dotted red) that is exact at k = 1 and has maximum relative error of about 0.6%. The cyan shaded region is the remaining gap between upper and lower bounds (or conjectured bounds), including these new bounds and the bounds in the previous figure.Log–log plot of upper (solid) and lower (dashed) bounds to the median of a gamma distribution and the gaps between them. The green, yellow, and cyan regions represent the gap before the Lyon 2021 paper. The green and yellow narrow that gap with the lower bounds that Lyon proved. Lyon's conjectured bounds further narrow the yellow. Mostly within the yellow, closed-form rational-function-interpolated bounds are plotted along with the numerically calculated median (dotted) value. Tighter interpolated bounds exist but are not plotted, as they would not be resolved at this scale.
Partial sums of these series are good approximations for high enough k; they are not plotted in the figure, which is focused on the low-k region that is less well approximated.
Berg and Pedersen also proved many properties of the median, showing that it is a convex function of k,[8] and that the asymptotic behavior near is (where γ is the Euler–Mascheroni constant), and that for all the median is bounded by .[7]
A closer linear upper bound, for only, was provided in 2021 by Gaunt and Merkle,[9] relying on the Berg and Pedersen result that the slope of is everywhere less than 1:
for (with equality at )
which can be extended to a bound for all by taking the max with the chord shown in the figure, since the median was proved convex.[8]
An approximation to the median that is asymptotically accurate at high k and reasonable down to or a bit lower follows from the Wilson–Hilferty transformation:
which goes negative for .
In 2021, Lyon proposed several approximations of the form . He conjectured values of A and B for which this approximation is an asymptotically tight upper or lower bound for all .[10] In particular, he proposed these closed-form bounds, which he proved in 2023:[11]
is a lower bound, asymptotically tight as
is an upper bound, asymptotically tight as
Lyon also showed (informally in 2021, rigorously in 2023) two other lower bounds that are not closed-form expressions, including this one involving the gamma function, based on solving the integral expression substituting 1 for :
(approaching equality as )
and the tangent line at where the derivative was found to be :
Additionally, he showed that interpolations between bounds could provide excellent approximations or tighter bounds to the median, including an approximation that is exact at (where ) and has a maximum relative error less than 0.6%. Interpolated approximations and bounds are all of the form
where is an interpolating function running monotonically from 0 at low k to 1 at high k, approximating an ideal, or exact, interpolator :
For the simplest interpolating function considered, a first-order rational function
the tightest lower bound has
and the tightest upper bound has
The interpolated bounds are plotted (mostly inside the yellow region) in the log–log plot shown. Even tighter bounds are available using different interpolating functions, but not usually with closed-form parameters like these.[10]
Summation
If Xi has a Gamma(ki, θ) distribution for i = 1, 2, ..., N (i.e., all distributions have the same scale parameter θ), then
Indeed, we know that if X is an exponential r.v. with rate λ, then cX is an exponential r.v. with rate λ/c; the same thing is valid with Gamma variates (and this can be checked using the moment-generating function, see, e.g.,these notes, 10.4-(ii)): multiplication by a positive constant c divides the rate (or, equivalently, multiplies the scale).
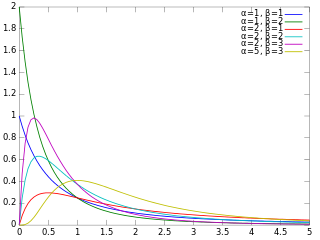
Illustration of the Kullback–Leibler (KL) divergence for two gamma PDFs. Here β = β0 + 1 which are set to 1, 2, 3, 4, 5, and6. The typical asymmetry for the KL divergence is clearly visible.
The Kullback–Leibler divergence (KL-divergence), of Gamma(αp, βp) ("true" distribution) from Gamma(αq, βq) ("approximating" distribution) is given by[14]
Written using the k, θ parameterization, the KL-divergence of Gamma(kp, θp) from Gamma(kq, θq) is given by
Let be independent and identically distributed random variables following an exponential distribution with rate parameter λ, then ~ Gamma(n, λ) where n is the shape parameter and λ is the rate, and .
If X ~ Gamma(1, λ) (in the shape–rate parametrization), then X has an exponential distribution with rate parameter λ. In the shape-scale parametrization, X ~ Gamma(1, λ) has an exponential distribution with rate parameter 1/λ.
If X ~ Gamma(ν/2, 2) (in the shape–scale parametrization), then X is identical to χ2(ν), the chi-squared distribution with ν degrees of freedom. Conversely, if Q ~ χ2(ν) and c is a positive constant, then cQ ~ Gamma(ν/2, 2c).
If θ = 1/k, one obtains the Schulz-Zimm distribution, which is most prominently used to model polymer chain lengths.
If k is an integer, the gamma distribution is an Erlang distribution and is the probability distribution of the waiting time until the k-th "arrival" in a one-dimensional Poisson process with intensity 1/θ. If
If X ~ Gamma(k, θ), then follows an exponential-gamma (abbreviated exp-gamma) distribution.[15] It is sometimes referred to as the log-gamma distribution.[16] Formulas for its mean and variance are in the section #Logarithmic expectation and variance.
More generally, if X ~ Gamma(k,θ), then for follows a generalized gamma distribution with parameters p = 1/q, d = k/q, and .
If X ~ Gamma(k, θ) with shape k and scale θ, then 1/X ~ Inv-Gamma(k, θ−1) (see Inverse-gamma distribution for derivation).
Parametrization 1: If are independent, then , or equivalently,
Parametrization 2: If are independent, then , or equivalently,
If X ~ Gamma(α, θ) and Y ~ Gamma(β, θ) are independently distributed, then X/(X + Y) has a beta distribution with parameters α and β, and X/(X + Y) is independent of X + Y, which is Gamma(α + β, θ)-distributed.
If Xi ~ Gamma(αi, 1) are independently distributed, then the vector (X1/S, ..., Xn/S), where S = X1 + ... + Xn, follows a Dirichlet distribution with parameters α1, ..., αn.
For large k the gamma distribution converges to normal distribution with mean μ = kθ and variance σ2 = kθ2.
The matrix gamma distribution and the Wishart distribution are multivariate generalizations of the gamma distribution (samples are positive-definite matrices rather than positive real numbers).
If the shape parameter of the gamma distribution is known, but the inverse-scale parameter is unknown, then a gamma distribution for the inverse scale forms a conjugate prior. The compound distribution, which results from integrating out the inverse scale, has a closed-form solution known as the compound gamma distribution.[18]
If, instead, the shape parameter is known but the mean is unknown, with the prior of the mean being given by another gamma distribution, then it results in K-distribution.
Weibull and stable count
The gamma distribution can be expressed as the product distribution of a Weibull distribution and a variant form of the stable count distribution. Its shape parameter can be regarded as the inverse of Lévy's stability parameter in the stable count distribution:
where is a standard stable count distribution of shape , and is a standard Weibull distribution of shape .
Statistical inference
Parameter estimation
Maximum likelihood estimation
The likelihood function for Niid observations (x1, ..., xN) is
from which we calculate the log-likelihood function
Finding the maximum with respect to θ by taking the derivative and setting it equal to zero yields the maximum likelihood estimator of the θ parameter, which equals the sample mean divided by the shape parameter k:
Substituting this into the log-likelihood function gives
We need at least two samples: , because for , the function increases without bounds as . For , it can be verified that is strictly concave, by using inequality properties of the polygamma function. Finding the maximum with respect to k by taking the derivative and setting it equal to zero yields
where ψ is the digamma function and is the sample mean of ln x. There is no closed-form solution for k. The function is numerically very well behaved, so if a numerical solution is desired, it can be found using, for example, Newton's method. An initial value of k can be found either using the method of moments, or using the approximation
If we let
then k is approximately
which is within 1.5% of the correct value.[19] An explicit form for the Newton–Raphson update of this initial guess is:[20]
At the maximum-likelihood estimate , the expected values for x and agree with the empirical averages:
Caveat for small shape parameter
For data, , that is represented in a floating point format that underflows to 0 for values smaller than , the logarithms that are needed for the maximum-likelihood estimate will cause failure if there are any underflows. If we assume the data was generated by a gamma distribution with cdf , then the probability that there is at least one underflow is:
This probability will approach 1 for small k and large N. For example, at , and , . A workaround is to instead have the data in logarithmic format.
In order to test an implementation of a maximum-likelihood estimator that takes logarithmic data as input, it is useful to be able to generate non-underflowing logarithms of random gamma variates, when . Following the implementation in scipy.stats.loggamma, this can be done as follows:[21] sample and independently. Then the required logarithmic sample is , so that .
Closed-form estimators
There exist consistent closed-form estimators of k and θ that are derived from the likelihood of the generalized gamma distribution.[22]
The estimate for the shape k is
and the estimate for the scale θ is
Using the sample mean of x, the sample mean of ln x, and the sample mean of the product x·ln x simplifies the expressions to:
If the rate parameterization is used, the estimate of .
These estimators are not strictly maximum likelihood estimators, but are instead referred to as mixed type log-moment estimators. They have however similar efficiency as the maximum likelihood estimators.
Although these estimators are consistent, they have a small bias. A bias-corrected variant of the estimator for the scale θ is
A bias correction for the shape parameter k is given as[23]
Bayesian minimum mean squared error
With known k and unknown θ, the posterior density function for theta (using the standard scale-invariant prior for θ) is
Denoting
Integration with respect to θ can be carried out using a change of variables, revealing that 1/θ is gamma-distributed with parameters α = Nk, β = y.
The moments can be computed by taking the ratio (m by m = 0)
which shows that the mean ± standard deviation estimate of the posterior distribution for θ is
where Z is the normalizing constant with no closed-form solution. The posterior distribution can be found by updating the parameters as follows:
where n is the number of observations, and xi is the i-th observation.
Occurrence and applications
Consider a sequence of events, with the waiting time for each event being an exponential distribution with rate β. Then the waiting time for the n-th event to occur is the gamma distribution with integer shape . This construction of the gamma distribution allows it to model a wide variety of phenomena where several sub-events, each taking time with exponential distribution, must happen in sequence for a major event to occur.[25] Examples include the waiting time of cell-division events,[26] number of compensatory mutations for a given mutation,[27] waiting time until a repair is necessary for a hydraulic system,[28] and so on.
In biophysics, the dwell time between steps of a molecular motor like ATP synthase is nearly exponential at constant ATP concentration, revealing that each step of the motor takes a single ATP hydrolysis. If there were n ATP hydrolysis events, then it would be a gamma distribution with degree n.[29]
In oncology, the age distribution of cancerincidence often follows the gamma distribution, wherein the shape and scale parameters predict, respectively, the number of driver events and the time interval between them.[32][33]
In phylogenetics, the gamma distribution is the most commonly used approach to model among-sites rate variation[39] when maximum likelihood, Bayesian, or distance matrix methods are used to estimate phylogenetic trees. Phylogenetic analyzes that use the gamma distribution to model rate variation estimate a single parameter from the data because they limit consideration to distributions where α = β. This parameterization means that the mean of this distribution is 1 and the variance is 1/α. Maximum likelihood and Bayesian methods typically use a discrete approximation to the continuous gamma distribution.[40][41]
Random variate generation
Given the scaling property above, it is enough to generate gamma variables with θ = 1, as we can later convert to any value of β with a simple division.
Suppose we wish to generate random variables from Gamma(n + δ, 1), where n is a non-negative integer and 0 < δ < 1. Using the fact that a Gamma(1, 1) distribution is the same as an Exp(1) distribution, and noting the method of generating exponential variables, we conclude that if U is uniformly distributed on (0, 1], then −ln U is distributed Gamma(1, 1) (i.e. inverse transform sampling). Now, using the "α-addition" property of gamma distribution, we expand this result:
where Uk are all uniformly distributed on (0, 1] and independent. All that is left now is to generate a variable distributed as Gamma(δ, 1) for 0 < δ < 1 and apply the "α-addition" property once more. This is the most difficult part.
Random generation of gamma variates is discussed in detail by Devroye,[42]:401–428 noting that none are uniformly fast for all shape parameters. For small values of the shape parameter, the algorithms are often not valid.[42]:406 For arbitrary values of the shape parameter, one can apply the Ahrens and Dieter[43] modified acceptance-rejection method Algorithm GD (shape k ≥ 1), or transformation method[44] when 0 < k < 1. Also see Cheng and Feast Algorithm GKM 3[45] or Marsaglia's squeeze method.[46]
Generate U, V and W as iid uniform (0, 1] variates.
If then and . Otherwise, and .
If then go to step 1.
ξ is distributed as Γ(δ, 1).
A summary of this is
where is the integer part of k, ξ is generated via the algorithm above with δ = {k} (the fractional part of k) and the Uk are all independent.
While the above approach is technically correct, Devroye notes that it is linear in the value of k and generally is not a good choice. Instead, he recommends using either rejection-based or table-based methods, depending on context.[42]:401–428
For example, Marsaglia's simple transformation-rejection method relying on one normal variate X and one uniform variate U:[21]
Set and .
Set .
If and return , else go back to step 2.
With generates a gamma distributed random number in time that is approximately constant with k. The acceptance rate does depend on k, with an acceptance rate of 0.95, 0.98, and 0.99 for k=1, 2, and 4. For k < 1, one can use to boost k to be usable with this method.
Related Research Articles
In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.
In probability theory and statistics, the chi-squared distribution with degrees of freedom is the distribution of a sum of the squares of independent standard normal random variables. The chi-squared distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing and in construction of confidence intervals. This distribution is sometimes called the central chi-squared distribution, a special case of the more general noncentral chi-squared distribution.
In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.
In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. Sometimes loosely referred to as "the" exponential family, this class of distributions is distinct because they all possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
In physics, the Hamilton–Jacobi equation, named after William Rowan Hamilton and Carl Gustav Jacob Jacobi, is an alternative formulation of classical mechanics, equivalent to other formulations such as Newton's laws of motion, Lagrangian mechanics and Hamiltonian mechanics.
In probability and statistics, the Dirichlet distribution (after Peter Gustav Lejeune Dirichlet), often denoted , is a family of continuous multivariate probability distributions parameterized by a vector of positive reals. It is a multivariate generalization of the beta distribution, hence its alternative name of multivariate beta distribution (MBD). Dirichlet distributions are commonly used as prior distributions in Bayesian statistics, and in fact, the Dirichlet distribution is the conjugate prior of the categorical distribution and multinomial distribution.
In probability theory, a distribution is said to be stable if a linear combination of two independent random variables with this distribution has the same distribution, up to location and scale parameters. A random variable is said to be stable if its distribution is stable. The stable distribution family is also sometimes referred to as the Lévy alpha-stable distribution, after Paul Lévy, the first mathematician to have studied it.
In probability theory and statistics, the inverse gamma distribution is a two-parameter family of continuous probability distributions on the positive real line, which is the distribution of the reciprocal of a variable distributed according to the gamma distribution.
In probability theory and statistics, the generalized inverse Gaussian distribution (GIG) is a three-parameter family of continuous probability distributions with probability density function
In probability theory and statistics, the beta prime distribution is an absolutely continuous probability distribution. If has a beta distribution, then the odds has a beta prime distribution.
In statistics, the inverse Wishart distribution, also called the inverted Wishart distribution, is a probability distribution defined on real-valued positive-definite matrices. In Bayesian statistics it is used as the conjugate prior for the covariance matrix of a multivariate normal distribution.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
The term generalized logistic distribution is used as the name for several different families of probability distributions. For example, Johnson et al. list four forms, which are listed below.
In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
In general relativity, a point mass deflects a light ray with impact parameter by an angle approximately equal to
The generalized normal distribution or generalized Gaussian distribution (GGD) is either of two families of parametric continuous probability distributions on the real line. Both families add a shape parameter to the normal distribution. To distinguish the two families, they are referred to below as "symmetric" and "asymmetric"; however, this is not a standard nomenclature.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product is a product distribution.
The Lomax distribution, conditionally also called the Pareto Type II distribution, is a heavy-tail probability distribution used in business, economics, actuarial science, queueing theory and Internet traffic modeling. It is named after K. S. Lomax. It is essentially a Pareto distribution that has been shifted so that its support begins at zero.
In statistics and probability theory, the nonparametric skew is a statistic occasionally used with random variables that take real values. It is a measure of the skewness of a random variable's distribution—that is, the distribution's tendency to "lean" to one side or the other of the mean. Its calculation does not require any knowledge of the form of the underlying distribution—hence the name nonparametric. It has some desirable properties: it is zero for any symmetric distribution; it is unaffected by a scale shift; and it reveals either left- or right-skewness equally well. In some statistical samples it has been shown to be less powerful than the usual measures of skewness in detecting departures of the population from normality.
1 2 Papoulis, Pillai, Probability, Random Variables, and Stochastic Processes, Fourth Edition
↑ Jeesen Chen, Herman Rubin, Bounds for the difference between median and mean of gamma and Poisson distributions, Statistics & Probability Letters, Volume 4, Issue 6, October 1986, Pages 281–283, ISSN0167-7152, .
↑ Gaunt, Robert E., and Milan Merkle (2021). "On bounds for the mode and median of the generalized hyperbolic and related distributions". Journal of Mathematical Analysis and Applications. 493 (1): 124508. arXiv:2002.01884. doi:10.1016/j.jmaa.2020.124508. S2CID221103640.{{cite journal}}: CS1 maint: multiple names: authors list (link)
↑ Moschopoulos, P. G. (1985). "The distribution of the sum of independent gamma random variables". Annals of the Institute of Statistical Mathematics. 37 (3): 541–544. doi:10.1007/BF02481123. S2CID120066454.
↑ W.D. Penny, [www.fil.ion.ucl.ac.uk/~wpenny/publications/densities.ps KL-Divergences of Normal, Gamma, Dirichlet, and Wishart densities][full citation needed]
↑ Choi, S. C.; Wette, R. (1969). "Maximum Likelihood Estimation of the Parameters of the Gamma Distribution and Their Bias". Technometrics. 11 (4): 683–690. doi:10.1080/00401706.1969.10490731.
1 2 Marsaglia, G.; Tsang, W. W. (2000). "A simple method for generating gamma variables". ACM Transactions on Mathematical Software. 26 (3): 363–372. doi:10.1145/358407.358414. S2CID2634158.
↑ Fink, D. 1995 A Compendium of Conjugate Priors. In progress report: Extension and enhancement of methods for setting data quality objectives. (DOE contract 95‑831).
↑ J. G. Robson and J. B. Troy, "Nature of the maintained discharge of Q, X, and Y retinal ganglion cells of the cat", J. Opt. Soc. Am. A 4, 2301–2307 (1987)
↑ M.C.M. Wright, I.M. Winter, J.J. Forster, S. Bleeck "Response to best-frequency tone bursts in the ventral cochlear nucleus is governed by ordered inter-spike interval statistics", Hearing Research 317 (2014)
↑ N. Friedman, L. Cai and X. S. Xie (2006) "Linking stochastic dynamics to population distribution: An analytical framework of gene expression", Phys. Rev. Lett. 97, 168302.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.




























































![Two gamma distribution median asymptotes which were proved in 2023 to be bounds (upper solid red and lower dashed red), of the from
n
(
k
)
[?]
2
-
1
/
k
(
A
+
k
)
{\displaystyle \nu (k)\approx 2^{-1/k}(A+k)}
, and an interpolation between them that makes an approximation (dotted red) that is exact at k = 1 and has maximum relative error of about 0.6%. The cyan shaded region is the remaining gap between upper and lower bounds (or conjectured bounds), including these new bounds and the bounds in the previous figure. Gamma distribution median Lyon bounds.png](http://upload.wikimedia.org/wikipedia/commons/thumb/1/1e/Gamma_distribution_median_Lyon_bounds.png/320px-Gamma_distribution_median_Lyon_bounds.png)