
In probability theory, a normaldistribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In probability theory, a log-normal distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of a probability distribution by maximizing a likelihood function, so that under the assumed statistical model the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In mathematics, the error function, often denoted by erf, is a complex function of a complex variable defined as:
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the form

In probability theory and statistics, the Rayleigh distribution is a continuous probability distribution for nonnegative-valued random variables. It is essentially a chi distribution with two degrees of freedom.

In statistics, particularly in hypothesis testing, the Hotelling's T-squared distribution (T2), proposed by Harold Hotelling, is a multivariate probability distribution that is tightly related to the F-distribution and is most notable for arising as the distribution of a set of sample statistics that are natural generalizations of the statistics underlying the Student's t-distribution.

Directional statistics is the subdiscipline of statistics that deals with directions, axes or rotations in Rn. More generally, directional statistics deals with observations on compact Riemannian manifolds.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.

In probability theory, the Rice distribution or Rician distribution is the probability distribution of the magnitude of a circularly-symmetric bivariate normal random variable, possibly with non-zero mean (noncentral). It was named after Stephen O. Rice.
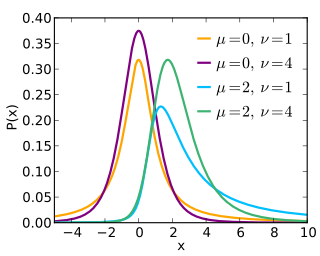
The noncentral t-distribution generalizes Student's t-distribution using a noncentrality parameter. Whereas the central probability distribution describes how a test statistic t is distributed when the difference tested is null, the noncentral distribution describes how t is distributed when the null is false. This leads to its use in statistics, especially calculating statistical power. The noncentral t-distribution is also known as the singly noncentral t-distribution, and in addition to its primary use in statistical inference, is also used in robust modeling for data.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
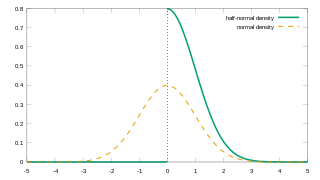
In probability theory and statistics, the half-normal distribution is a special case of the folded normal distribution.
Experimental uncertainty analysis is a technique that analyses a derived quantity, based on the uncertainties in the experimentally measured quantities that are used in some form of mathematical relationship ("model") to calculate that derived quantity. The model used to convert the measurements into the derived quantity is usually based on fundamental principles of a science or engineering discipline.
In probability theory and directional statistics, a wrapped probability distribution is a continuous probability distribution that describes data points that lie on a unit n-sphere. In one dimension, a wrapped distribution will consist of points on the unit circle. If φ is a random variate in the interval (-∞,∞) with probability density function p(φ), then z = e i φ will be a circular variable distributed according to the wrapped distribution pzw(z) and θ=arg(z) will be an angular variable in the interval (-π,π ] distributed according to the wrapped distribution pw.

In probability theory and directional statistics, a wrapped Cauchy distribution is a wrapped probability distribution that results from the "wrapping" of the Cauchy distribution around the unit circle. The Cauchy distribution is sometimes known as a Lorentzian distribution, and the wrapped Cauchy distribution may sometimes be referred to as a wrapped Lorentzian distribution.
In probability theory and directional statistics, a wrapped Lévy distribution is a wrapped probability distribution that results from the "wrapping" of the Lévy distribution around the unit circle.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product











































