In probability theory and statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the distance between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate; the distance parameter could be any meaningful mono-dimensional measure of the process, such as time between production errors, or length along a roll of fabric in the weaving manufacturing process. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In probability theory and statistics, the chi-squared distribution with degrees of freedom is the distribution of a sum of the squares of independent standard normal random variables. The chi-squared distribution is a special case of the gamma distribution and is one of the most widely used probability distributions in inferential statistics, notably in hypothesis testing and in construction of confidence intervals. This distribution is sometimes called the central chi-squared distribution, a special case of the more general noncentral chi-squared distribution.

In probability theory and statistics, the Weibull distribution is a continuous probability distribution. It models a broad range of random variables, largely in the nature of a time to failure or time between events. Examples are maximum one-day rainfalls and the time a user spends on a web page.
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. The result can be either a continuous or a discrete distribution.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.
In statistics and information theory, a maximum entropy probability distribution has entropy that is at least as great as that of all other members of a specified class of probability distributions. According to the principle of maximum entropy, if nothing is known about a distribution except that it belongs to a certain class, then the distribution with the largest entropy should be chosen as the least-informative default. The motivation is twofold: first, maximizing entropy minimizes the amount of prior information built into the distribution; second, many physical systems tend to move towards maximal entropy configurations over time.

In probability theory and statistics, the noncentral chi-squared distribution is a noncentral generalization of the chi-squared distribution. It often arises in the power analysis of statistical tests in which the null distribution is a chi-squared distribution; important examples of such tests are the likelihood-ratio tests.
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
In probability theory and statistics, the normal-gamma distribution is a bivariate four-parameter family of continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and precision.
In probability and statistics, the Tweedie distributions are a family of probability distributions which include the purely continuous normal, gamma and inverse Gaussian distributions, the purely discrete scaled Poisson distribution, and the class of compound Poisson–gamma distributions which have positive mass at zero, but are otherwise continuous. Tweedie distributions are a special case of exponential dispersion models and are often used as distributions for generalized linear models.
In probability and statistics, the class of exponential dispersion models (EDM), also called exponential dispersion family (EDF), is a set of probability distributions that represents a generalisation of the natural exponential family. Exponential dispersion models play an important role in statistical theory, in particular in generalized linear models because they have a special structure which enables deductions to be made about appropriate statistical inference.

In probability theory and statistics, the normal-inverse-gamma distribution is a four-parameter family of multivariate continuous probability distributions. It is the conjugate prior of a normal distribution with unknown mean and variance.
Financial models with long-tailed distributions and volatility clustering have been introduced to overcome problems with the realism of classical financial models. These classical models of financial time series typically assume homoskedasticity and normality cannot explain stylized phenomena such as skewness, heavy tails, and volatility clustering of the empirical asset returns in finance. In 1963, Benoit Mandelbrot first used the stable distribution to model the empirical distributions which have the skewness and heavy-tail property. Since -stable distributions have infinite -th moments for all , the tempered stable processes have been proposed for overcoming this limitation of the stable distribution.

In probability theory and statistics, the Poisson distribution is a discrete probability distribution that expresses the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate and independently of the time since the last event. It can also be used for the number of events in other types of intervals than time, and in dimension greater than 1.
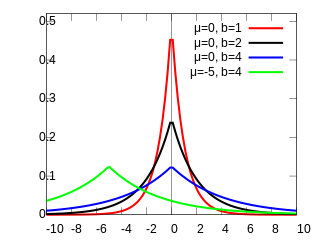
A geometric stable distribution or geo-stable distribution is a type of leptokurtic probability distribution. Geometric stable distributions were introduced in Klebanov, L. B., Maniya, G. M., and Melamed, I. A. (1985). A problem of Zolotarev and analogs of infinitely divisible and stable distributions in a scheme for summing a random number of random variables. These distributions are analogues for stable distributions for the case when the number of summands is random, independent of the distribution of summand, and having geometric distribution. The geometric stable distribution may be symmetric or asymmetric. A symmetric geometric stable distribution is also referred to as a Linnik distribution. The Laplace distribution and asymmetric Laplace distribution are special cases of the geometric stable distribution. The Mittag-Leffler distribution is also a special case of a geometric stable distribution.

The q-exponential distribution is a probability distribution arising from the maximization of the Tsallis entropy under appropriate constraints, including constraining the domain to be positive. It is one example of a Tsallis distribution. The q-exponential is a generalization of the exponential distribution in the same way that Tsallis entropy is a generalization of standard Boltzmann–Gibbs entropy or Shannon entropy. The exponential distribution is recovered as
In probability theory and statistics, the noncentral beta distribution is a continuous probability distribution that is a noncentral generalization of the (central) beta distribution.
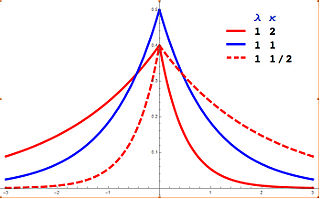
In probability theory and statistics, the asymmetric Laplace distribution (ALD) is a continuous probability distribution which is a generalization of the Laplace distribution. Just as the Laplace distribution consists of two exponential distributions of equal scale back-to-back about x = m, the asymmetric Laplace consists of two exponential distributions of unequal scale back to back about x = m, adjusted to assure continuity and normalization. The difference of two variates exponentially distributed with different means and rate parameters will be distributed according to the ALD. When the two rate parameters are equal, the difference will be distributed according to the Laplace distribution.