The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .

In probability theory and statistics, the negative binomial distribution is a discrete probability distribution that models the number of failures in a sequence of independent and identically distributed Bernoulli trials before a specified (non-random) number of successes occurs. For example, we can define rolling a 6 on a die as a success, and rolling any other number as a failure, and ask how many failure rolls will occur before we see the third success. In such a case, the probability distribution of the number of failures that appear will be a negative binomial distribution.

In probability theory and statistics, the exponential distribution or negative exponential distribution is the probability distribution of the time between events in a Poisson point process, i.e., a process in which events occur continuously and independently at a constant average rate. It is a particular case of the gamma distribution. It is the continuous analogue of the geometric distribution, and it has the key property of being memoryless. In addition to being used for the analysis of Poisson point processes it is found in various other contexts.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
Covariance in probability theory and statistics is a measure of the joint variability of two random variables.

In mathematics, the error function, often denoted by erf, is a complex function of a complex variable defined as:

In probability theory and statistics, the Bernoulli distribution, named after Swiss mathematician Jacob Bernoulli, is the discrete probability distribution of a random variable which takes the value 1 with probability and the value 0 with probability . Less formally, it can be thought of as a model for the set of possible outcomes of any single experiment that asks a yes–no question. Such questions lead to outcomes that are boolean-valued: a single bit whose value is success/yes/true/one with probability p and failure/no/false/zero with probability q. It can be used to represent a coin toss where 1 and 0 would represent "heads" and "tails", respectively, and p would be the probability of the coin landing on heads. In particular, unfair coins would have

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] or in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
In probability theory, the probability generating function of a discrete random variable is a power series representation (the generating function) of the probability mass function of the random variable. Probability generating functions are often employed for their succinct description of the sequence of probabilities Pr(X = i) in the probability mass function for a random variable X, and to make available the well-developed theory of power series with non-negative coefficients.
In probability theory, the law of total variance or variance decomposition formula or conditional variance formulas or law of iterated variances also known as Eve's law, states that if and are random variables on the same probability space, and the variance of is finite, then
In probability theory and statistics, the cumulantsκn of a probability distribution are a set of quantities that provide an alternative to the moments of the distribution. Any two probability distributions whose moments are identical will have identical cumulants as well, and vice versa.
In statistics, the Wishart distribution is a generalization to multiple dimensions of the gamma distribution. It is named in honor of John Wishart, who first formulated the distribution in 1928. Other names include Wishart ensemble, or Wishart–Laguerre ensemble, or LOE, LUE, LSE.
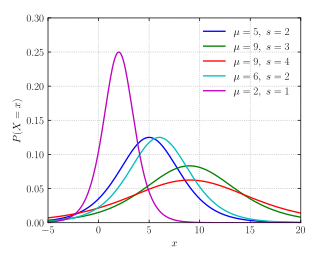
In probability theory and statistics, the logistic distribution is a continuous probability distribution. Its cumulative distribution function is the logistic function, which appears in logistic regression and feedforward neural networks. It resembles the normal distribution in shape but has heavier tails. The logistic distribution is a special case of the Tukey lambda distribution.
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. The result can be either a continuous or a discrete distribution.

In probability theory and statistics, the Laplace distribution is a continuous probability distribution named after Pierre-Simon Laplace. It is also sometimes called the double exponential distribution, because it can be thought of as two exponential distributions spliced together along the abscissa, although the term is also sometimes used to refer to the Gumbel distribution. The difference between two independent identically distributed exponential random variables is governed by a Laplace distribution, as is a Brownian motion evaluated at an exponentially distributed random time. Increments of Laplace motion or a variance gamma process evaluated over the time scale also have a Laplace distribution.

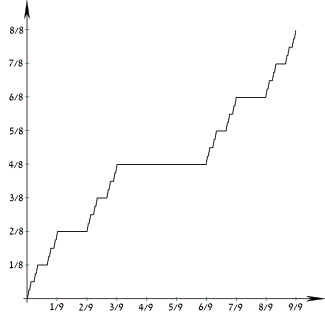
In statistics, an empirical distribution function is the distribution function associated with the empirical measure of a sample. This cumulative distribution function is a step function that jumps up by 1/n at each of the n data points. Its value at any specified value of the measured variable is the fraction of observations of the measured variable that are less than or equal to the specified value.
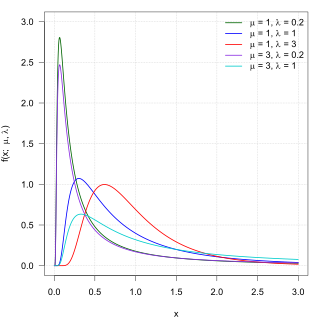
In probability theory, the inverse Gaussian distribution is a two-parameter family of continuous probability distributions with support on (0,∞).
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product is a product distribution.