
The Cauchy distribution, named after Augustin Cauchy, is a continuous probability distribution. It is also known, especially among physicists, as the Lorentz distribution, Cauchy–Lorentz distribution, Lorentz(ian) function, or Breit–Wigner distribution. The Cauchy distribution is the distribution of the x-intercept of a ray issuing from with a uniformly distributed angle. It is also the distribution of the ratio of two independent normally distributed random variables with mean zero.

In statistics, a normal distribution or Gaussian distribution is a type of continuous probability distribution for a real-valued random variable. The general form of its probability density function is

In probability theory and statistics, the multivariate normal distribution, multivariate Gaussian distribution, or joint normal distribution is a generalization of the one-dimensional (univariate) normal distribution to higher dimensions. One definition is that a random vector is said to be k-variate normally distributed if every linear combination of its k components has a univariate normal distribution. Its importance derives mainly from the multivariate central limit theorem. The multivariate normal distribution is often used to describe, at least approximately, any set of (possibly) correlated real-valued random variables each of which clusters around a mean value.

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In probability theory and statistics, the Gumbel distribution is used to model the distribution of the maximum of a number of samples of various distributions.

In probability theory and statistics, the Lévy distribution, named after Paul Lévy, is a continuous probability distribution for a non-negative random variable. In spectroscopy, this distribution, with frequency as the dependent variable, is known as a van der Waals profile. It is a special case of the inverse-gamma distribution. It is a stable distribution.
Directional statistics is the subdiscipline of statistics that deals with directions, axes or rotations in Rn. More generally, directional statistics deals with observations on compact Riemannian manifolds including the Stiefel manifold.
In probability theory and statistics, the generalized extreme value (GEV) distribution is a family of continuous probability distributions developed within extreme value theory to combine the Gumbel, Fréchet and Weibull families also known as type I, II and III extreme value distributions. By the extreme value theorem the GEV distribution is the only possible limit distribution of properly normalized maxima of a sequence of independent and identically distributed random variables. Note that a limit distribution needs to exist, which requires regularity conditions on the tail of the distribution. Despite this, the GEV distribution is often used as an approximation to model the maxima of long (finite) sequences of random variables.

In probability theory and directional statistics, the von Mises distribution is a continuous probability distribution on the circle. It is a close approximation to the wrapped normal distribution, which is the circular analogue of the normal distribution. A freely diffusing angle on a circle is a wrapped normally distributed random variable with an unwrapped variance that grows linearly in time. On the other hand, the von Mises distribution is the stationary distribution of a drift and diffusion process on the circle in a harmonic potential, i.e. with a preferred orientation. The von Mises distribution is the maximum entropy distribution for circular data when the real and imaginary parts of the first circular moment are specified. The von Mises distribution is a special case of the von Mises–Fisher distribution on the N-dimensional sphere.
Differential entropy is a concept in information theory that began as an attempt by Claude Shannon to extend the idea of (Shannon) entropy, a measure of average surprisal of a random variable, to continuous probability distributions. Unfortunately, Shannon did not derive this formula, and rather just assumed it was the correct continuous analogue of discrete entropy, but it is not. The actual continuous version of discrete entropy is the limiting density of discrete points (LDDP). Differential entropy is commonly encountered in the literature, but it is a limiting case of the LDDP, and one that loses its fundamental association with discrete entropy.
Expected shortfall (ES) is a risk measure—a concept used in the field of financial risk measurement to evaluate the market risk or credit risk of a portfolio. The "expected shortfall at q% level" is the expected return on the portfolio in the worst of cases. ES is an alternative to value at risk that is more sensitive to the shape of the tail of the loss distribution.
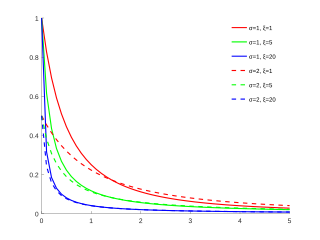
In statistics, the generalized Pareto distribution (GPD) is a family of continuous probability distributions. It is often used to model the tails of another distribution. It is specified by three parameters: location , scale , and shape . Sometimes it is specified by only scale and shape and sometimes only by its shape parameter. Some references give the shape parameter as .
A ratio distribution is a probability distribution constructed as the distribution of the ratio of random variables having two other known distributions. Given two random variables X and Y, the distribution of the random variable Z that is formed as the ratio Z = X/Y is a ratio distribution.
Tail value at risk (TVaR), also known as tail conditional expectation (TCE) or conditional tail expectation (CTE), is a risk measure associated with the more general value at risk. It quantifies the expected value of the loss given that an event outside a given probability level has occurred.

In probability theory and directional statistics, a wrapped normal distribution is a wrapped probability distribution that results from the "wrapping" of the normal distribution around the unit circle. It finds application in the theory of Brownian motion and is a solution to the heat equation for periodic boundary conditions. It is closely approximated by the von Mises distribution, which, due to its mathematical simplicity and tractability, is the most commonly used distribution in directional statistics.

In probability theory and directional statistics, a wrapped Cauchy distribution is a wrapped probability distribution that results from the "wrapping" of the Cauchy distribution around the unit circle. The Cauchy distribution is sometimes known as a Lorentzian distribution, and the wrapped Cauchy distribution may sometimes be referred to as a wrapped Lorentzian distribution.
In probability theory and statistics, an inverse distribution is the distribution of the reciprocal of a random variable. Inverse distributions arise in particular in the Bayesian context of prior distributions and posterior distributions for scale parameters. In the algebra of random variables, inverse distributions are special cases of the class of ratio distributions, in which the numerator random variable has a degenerate distribution.

ProbOnto is a knowledge base and ontology of probability distributions. ProbOnto 2.5 contains over 150 uni- and multivariate distributions and alternative parameterizations, more than 220 relationships and re-parameterization formulas, supporting also the encoding of empirical and univariate mixture distributions.
In probability theory, a log-t distribution or log-Student t distribution is a probability distribution of a random variable whose logarithm is distributed in accordance with a Student's t-distribution. If X is a random variable with a Student's t-distribution, then Y = exp(X) has a log-t distribution; likewise, if Y has a log-t distribution, then X = log(Y) has a Student's t-distribution.

















