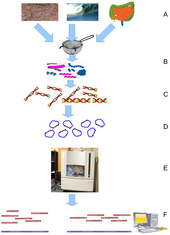
Bioinformatics is an interdisciplinary field of science that develops methods and software tools for understanding biological data, especially when the data sets are large and complex. Bioinformatics uses biology, chemistry, physics, computer science, computer programming, information engineering, mathematics and statistics to analyze and interpret biological data. The subsequent process of analyzing and interpreting data is referred to as computational biology.

Genetics is the study of genes, genetic variation, and heredity in organisms. It is an important branch in biology because heredity is vital to organisms' evolution. Gregor Mendel, a Moravian Augustinian friar working in the 19th century in Brno, was the first to study genetics scientifically. Mendel studied "trait inheritance", patterns in the way traits are handed down from parents to offspring over time. He observed that organisms inherit traits by way of discrete "units of inheritance". This term, still used today, is a somewhat ambiguous definition of what is referred to as a gene.

In the fields of molecular biology and genetics, a genome is all the genetic information of an organism. It consists of nucleotide sequences of DNA. The nuclear genome includes protein-coding genes and non-coding genes, other functional regions of the genome such as regulatory sequences, and often a substantial fraction of junk DNA with no evident function. Almost all eukaryotes have mitochondria and a small mitochondrial genome. Algae and plants also contain chloroplasts with a chloroplast genome.
In biology, a mutation is an alteration in the nucleic acid sequence of the genome of an organism, virus, or extrachromosomal DNA. Viral genomes contain either DNA or RNA. Mutations result from errors during DNA or viral replication, mitosis, or meiosis or other types of damage to DNA, which then may undergo error-prone repair, cause an error during other forms of repair, or cause an error during replication. Mutations may also result from insertion or deletion of segments of DNA due to mobile genetic elements.

The human genome is a complete set of nucleic acid sequences for humans, encoded as DNA within the 23 chromosome pairs in cell nuclei and in a small DNA molecule found within individual mitochondria. These are usually treated separately as the nuclear genome and the mitochondrial genome. Human genomes include both protein-coding DNA sequences and various types of DNA that does not encode proteins. The latter is a diverse category that includes DNA coding for non-translated RNA, such as that for ribosomal RNA, transfer RNA, ribozymes, small nuclear RNAs, and several types of regulatory RNAs. It also includes promoters and their associated gene-regulatory elements, DNA playing structural and replicatory roles, such as scaffolding regions, telomeres, centromeres, and origins of replication, plus large numbers of transposable elements, inserted viral DNA, non-functional pseudogenes and simple, highly repetitive sequences. Introns make up a large percentage of non-coding DNA. Some of this non-coding DNA is non-functional junk DNA, such as pseudogenes, but there is no firm consensus on the total amount of junk DNA.
A microsatellite is a tract of repetitive DNA in which certain DNA motifs are repeated, typically 5–50 times. Microsatellites occur at thousands of locations within an organism's genome. They have a higher mutation rate than other areas of DNA leading to high genetic diversity. Microsatellites are often referred to as short tandem repeats (STRs) by forensic geneticists and in genetic genealogy, or as simple sequence repeats (SSRs) by plant geneticists.
In bioinformatics, sequence analysis is the process of subjecting a DNA, RNA or peptide sequence to any of a wide range of analytical methods to understand its features, function, structure, or evolution. Methodologies used include sequence alignment, searches against biological databases, and others.
Molecular genetics is a branch of biology that addresses how differences in the structures or expression of DNA molecules manifests as variation among organisms. Molecular genetics often applies an "investigative approach" to determine the structure and/or function of genes in an organism's genome using genetic screens.

In genetics and bioinformatics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome. Although certain definitions require the substitution to be present in a sufficiently large fraction of the population, many publications do not apply such a frequency threshold.

Comparative genomics is a field of biological research in which the genomic features of different organisms are compared. The genomic features may include the DNA sequence, genes, gene order, regulatory sequences, and other genomic structural landmarks. In this branch of genomics, whole or large parts of genomes resulting from genome projects are compared to study basic biological similarities and differences as well as evolutionary relationships between organisms. The major principle of comparative genomics is that common features of two organisms will often be encoded within the DNA that is evolutionarily conserved between them. Therefore, comparative genomic approaches start with making some form of alignment of genome sequences and looking for orthologous sequences in the aligned genomes and checking to what extent those sequences are conserved. Based on these, genome and molecular evolution are inferred and this may in turn be put in the context of, for example, phenotypic evolution or population genetics.

Functional genomics is a field of molecular biology that attempts to describe gene functions and interactions. Functional genomics make use of the vast data generated by genomic and transcriptomic projects. Functional genomics focuses on the dynamic aspects such as gene transcription, translation, regulation of gene expression and protein–protein interactions, as opposed to the static aspects of the genomic information such as DNA sequence or structures. A key characteristic of functional genomics studies is their genome-wide approach to these questions, generally involving high-throughput methods rather than a more traditional "candidate-gene" approach.
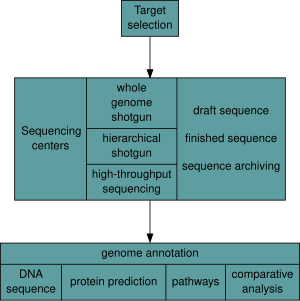
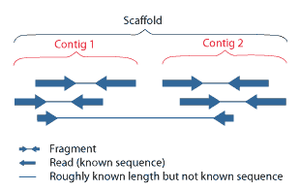
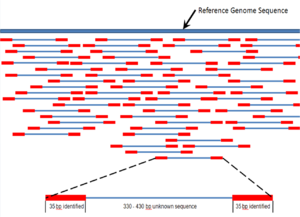
DNA sequencing is the process of determining the nucleic acid sequence – the order of nucleotides in DNA. It includes any method or technology that is used to determine the order of the four bases: adenine, guanine, cytosine, and thymine. The advent of rapid DNA sequencing methods has greatly accelerated biological and medical research and discovery.
In biology, the word gene has two meanings. The Mendelian gene is a basic unit of heredity. The molecular gene is a sequence of nucleotides in DNA, that is transcribed to produce a functional RNA. There are two types of molecular genes: protein-coding genes and non-coding genes.
Epigenomics is the study of the complete set of epigenetic modifications on the genetic material of a cell, known as the epigenome. The field is analogous to genomics and proteomics, which are the study of the genome and proteome of a cell. Epigenetic modifications are reversible modifications on a cell's DNA or histones that affect gene expression without altering the DNA sequence. Epigenomic maintenance is a continuous process and plays an important role in stability of eukaryotic genomes by taking part in crucial biological mechanisms like DNA repair. Plant flavones are said to be inhibiting epigenomic marks that cause cancers. Two of the most characterized epigenetic modifications are DNA methylation and histone modification. Epigenetic modifications play an important role in gene expression and regulation, and are involved in numerous cellular processes such as in differentiation/development and tumorigenesis. The study of epigenetics on a global level has been made possible only recently through the adaptation of genomic high-throughput assays.
Whole genome sequencing (WGS), also known as full genome sequencing, complete genome sequencing, or entire genome sequencing, is the process of determining the entirety, or nearly the entirety, of the DNA sequence of an organism's genome at a single time. This entails sequencing all of an organism's chromosomal DNA as well as DNA contained in the mitochondria and, for plants, in the chloroplast.

Exome sequencing, also known as whole exome sequencing (WES), is a genomic technique for sequencing all of the protein-coding regions of genes in a genome. It consists of two steps: the first step is to select only the subset of DNA that encodes proteins. These regions are known as exons—humans have about 180,000 exons, constituting about 1% of the human genome, or approximately 30 million base pairs. The second step is to sequence the exonic DNA using any high-throughput DNA sequencing technology.
The history of genetics can be represented on a timeline of events from the earliest work in the 1850s, to the DNA era starting in the 1940s, and the genomics era beginning in the 1970s.
An overlapping gene is a gene whose expressible nucleotide sequence partially overlaps with the expressible nucleotide sequence of another gene. In this way, a nucleotide sequence may make a contribution to the function of one or more gene products. Overlapping genes are present in and a fundamental feature of both cellular and viral genomes. The current definition of an overlapping gene varies significantly between eukaryotes, prokaryotes, and viruses. In prokaryotes and viruses overlap must be between coding sequences but not mRNA transcripts, and is defined when these coding sequences share a nucleotide on either the same or opposite strands. In eukaryotes, gene overlap is almost always defined as mRNA transcript overlap. Specifically, a gene overlap in eukaryotes is defined when at least one nucleotide is shared between the boundaries of the primary mRNA transcripts of two or more genes, such that a DNA base mutation at any point of the overlapping region would affect the transcripts of all genes involved. This definition includes 5′ and 3′ untranslated regions (UTRs) along with introns.
Single nucleotide polymorphism annotation is the process of predicting the effect or function of an individual SNP using SNP annotation tools. In SNP annotation the biological information is extracted, collected and displayed in a clear form amenable to query. SNP functional annotation is typically performed based on the available information on nucleic acid and protein sequences.
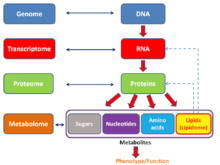
Transcriptomics technologies are the techniques used to study an organism's transcriptome, the sum of all of its RNA transcripts. The information content of an organism is recorded in the DNA of its genome and expressed through transcription. Here, mRNA serves as a transient intermediary molecule in the information network, whilst non-coding RNAs perform additional diverse functions. A transcriptome captures a snapshot in time of the total transcripts present in a cell. Transcriptomics technologies provide a broad account of which cellular processes are active and which are dormant. A major challenge in molecular biology is to understand how a single genome gives rise to a variety of cells. Another is how gene expression is regulated.