
Linear programming (LP), also called linear optimization, is a method to achieve the best outcome in a mathematical model whose requirements and objective are represented by linear relationships. Linear programming is a special case of mathematical programming.
In machine learning, support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories by Vladimir Vapnik with colleagues SVMs are one of the most studied models, being based on statistical learning frameworks of VC theory proposed by Vapnik and Chervonenkis (1974).
In mathematical optimization, Dantzig's simplex algorithm is a popular algorithm for linear programming.

Optimal control theory is a branch of control theory that deals with finding a control for a dynamical system over a period of time such that an objective function is optimized. It has numerous applications in science, engineering and operations research. For example, the dynamical system might be a spacecraft with controls corresponding to rocket thrusters, and the objective might be to reach the Moon with minimum fuel expenditure. Or the dynamical system could be a nation's economy, with the objective to minimize unemployment; the controls in this case could be fiscal and monetary policy. A dynamical system may also be introduced to embed operations research problems within the framework of optimal control theory.
An integer programming problem is a mathematical optimization or feasibility program in which some or all of the variables are restricted to be integers. In many settings the term refers to integer linear programming (ILP), in which the objective function and the constraints are linear.
In the field of mathematical optimization, stochastic programming is a framework for modeling optimization problems that involve uncertainty. A stochastic program is an optimization problem in which some or all problem parameters are uncertain, but follow known probability distributions. This framework contrasts with deterministic optimization, in which all problem parameters are assumed to be known exactly. The goal of stochastic programming is to find a decision which both optimizes some criteria chosen by the decision maker, and appropriately accounts for the uncertainty of the problem parameters. Because many real-world decisions involve uncertainty, stochastic programming has found applications in a broad range of areas ranging from finance to transportation to energy optimization.
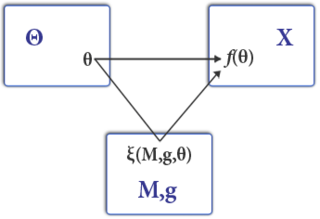
Mechanism design is a branch of economics, social choice theory, and game theory that deals with designing games to implement a given social choice function. Because it starts at the end of the game and then works backwards to find a game that implements it, it is sometimes called reverse game theory.
In mathematics and computer algebra, automatic differentiation, also called algorithmic differentiation, computational differentiation, is a set of techniques to evaluate the partial derivative of a function specified by a computer program.
Interior-point methods are algorithms for solving linear and non-linear convex optimization problems. IPMs combine two advantages of previously-known algorithms:
Convex optimization is a subfield of mathematical optimization that studies the problem of minimizing convex functions over convex sets. Many classes of convex optimization problems admit polynomial-time algorithms, whereas mathematical optimization is in general NP-hard.
In mathematical optimization theory, duality or the duality principle is the principle that optimization problems may be viewed from either of two perspectives, the primal problem or the dual problem. If the primal is a minimization problem then the dual is a maximization problem. Any feasible solution to the primal (minimization) problem is at least as large as any feasible solution to the dual (maximization) problem. Therefore, the solution to the primal is an upper bound to the solution of the dual, and the solution of the dual is a lower bound to the solution of the primal. This fact is called weak duality.
In mathematical optimization, constrained optimization is the process of optimizing an objective function with respect to some variables in the presence of constraints on those variables. The objective function is either a cost function or energy function, which is to be minimized, or a reward function or utility function, which is to be maximized. Constraints can be either hard constraints, which set conditions for the variables that are required to be satisfied, or soft constraints, which have some variable values that are penalized in the objective function if, and based on the extent that, the conditions on the variables are not satisfied.
In mathematical optimization, the ellipsoid method is an iterative method for minimizing convex functions over convex sets. The ellipsoid method generates a sequence of ellipsoids whose volume uniformly decreases at every step, thus enclosing a minimizer of a convex function.
Semidefinite programming (SDP) is a subfield of mathematical programming concerned with the optimization of a linear objective function over the intersection of the cone of positive semidefinite matrices with an affine space, i.e., a spectrahedron.

In mathematics, the relaxation of a (mixed) integer linear program is the problem that arises by removing the integrality constraint of each variable.
Linear Programming Boosting (LPBoost) is a supervised classifier from the boosting family of classifiers. LPBoost maximizes a margin between training samples of different classes and hence also belongs to the class of margin-maximizing supervised classification algorithms. Consider a classification function
The dual of a given linear program (LP) is another LP that is derived from the original LP in the following schematic way:
The Bregman method is an iterative algorithm to solve certain convex optimization problems involving regularization. The original version is due to Lev M. Bregman, who published it in 1967.
Benders decomposition is a technique in mathematical programming that allows the solution of very large linear programming problems that have a special block structure. This block structure often occurs in applications such as stochastic programming as the uncertainty is usually represented with scenarios. The technique is named after Jacques F. Benders.
In the theory of linear programming, a basic feasible solution (BFS) is a solution with a minimal set of non-zero variables. Geometrically, each BFS corresponds to a vertex of the polyhedron of feasible solutions. If there exists an optimal solution, then there exists an optimal BFS. Hence, to find an optimal solution, it is sufficient to consider the BFS-s. This fact is used by the simplex algorithm, which essentially travels from one BFS to another until an optimal solution is found.






















