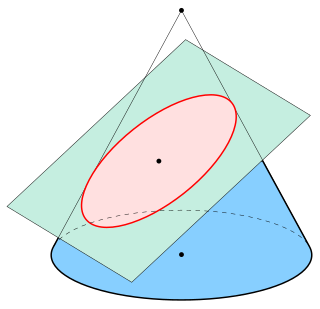
In mathematics, an ellipse is a plane curve surrounding two focal points, such that for all points on the curve, the sum of the two distances to the focal points is a constant. It generalizes a circle, which is the special type of ellipse in which the two focal points are the same. The elongation of an ellipse is measured by its eccentricity , a number ranging from to .
In mathematics, an equation is a mathematical formula that expresses the equality of two expressions, by connecting them with the equals sign =. The word equation and its cognates in other languages may have subtly different meanings; for example, in French an équation is defined as containing one or more variables, while in English, any well-formed formula consisting of two expressions related with an equals sign is an equation.

A sphere is a geometrical object that is a three-dimensional analogue to a two-dimensional circle. Formally, a sphere is the set of points that are all at the same distance r from a given point in three-dimensional space. That given point is the center of the sphere, and r is the sphere's radius. The earliest known mentions of spheres appear in the work of the ancient Greek mathematicians.

2D computer graphics is the computer-based generation of digital images—mostly from two-dimensional models and by techniques specific to them. It may refer to the branch of computer science that comprises such techniques or to the models themselves.
In electrodynamics, elliptical polarization is the polarization of electromagnetic radiation such that the tip of the electric field vector describes an ellipse in any fixed plane intersecting, and normal to, the direction of propagation. An elliptically polarized wave may be resolved into two linearly polarized waves in phase quadrature, with their polarization planes at right angles to each other. Since the electric field can rotate clockwise or counterclockwise as it propagates, elliptically polarized waves exhibit chirality.

In mathematics, a great circle or orthodrome is the circular intersection of a sphere and a plane passing through the sphere's center point.
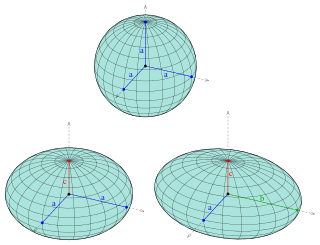
An ellipsoid is a surface that can be obtained from a sphere by deforming it by means of directional scalings, or more generally, of an affine transformation.

In mathematics, a parametric equation defines a group of quantities as functions of one or more independent variables called parameters. Parametric equations are commonly used to express the coordinates of the points that make up a geometric object such as a curve or surface, called a parametric curve and parametric surface, respectively. In such cases, the equations are collectively called a parametric representation, or parametric system, or parameterization of the object.

A cone is a three-dimensional geometric shape that tapers smoothly from a flat base to a point called the apex or vertex.

In geometry, a cissoid is a plane curve generated from two given curves C1, C2 and a point O. Let L be a variable line passing through O and intersecting C1 at P1 and C2 at P2. Let P be the point on L so that Then the locus of such points P is defined to be the cissoid of the curves C1, C2 relative to O.

The Mollweide projection is an equal-area, pseudocylindrical map projection generally used for maps of the world or celestial sphere. It is also known as the Babinet projection, homalographic projection, homolographic projection, and elliptical projection. The projection trades accuracy of angle and shape for accuracy of proportions in area, and as such is used where that property is needed, such as maps depicting global distributions.

The Stokes parameters are a set of values that describe the polarization state of electromagnetic radiation. They were defined by George Gabriel Stokes in 1852, as a mathematically convenient alternative to the more common description of incoherent or partially polarized radiation in terms of its total intensity (I), (fractional) degree of polarization (p), and the shape parameters of the polarization ellipse. The effect of an optical system on the polarization of light can be determined by constructing the Stokes vector for the input light and applying Mueller calculus, to obtain the Stokes vector of the light leaving the system. They can be determined from directly observable phenomena. The original Stokes paper was discovered independently by Francis Perrin in 1942 and by Subrahamanyan Chandrasekhar in 1947, who named it as the Stokes parameters.
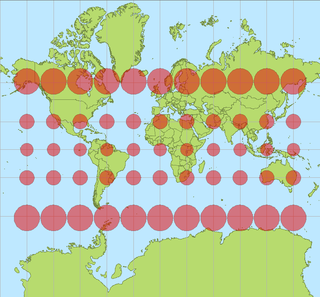
In cartography, a Tissot's indicatrix is a mathematical contrivance presented by French mathematician Nicolas Auguste Tissot in 1859 and 1871 in order to characterize local distortions due to map projection. It is the geometry that results from projecting a circle of infinitesimal radius from a curved geometric model, such as a globe, onto a map. Tissot proved that the resulting diagram is an ellipse whose axes indicate the two principal directions along which scale is maximal and minimal at that point on the map.
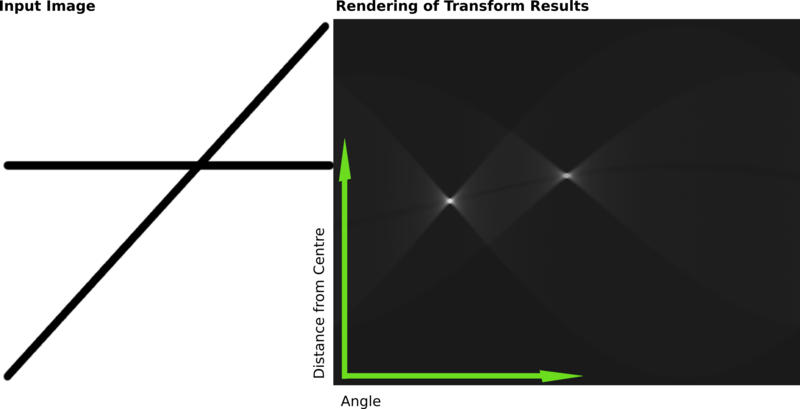
The generalized Hough transform (GHT), introduced by Dana H. Ballard in 1981, is the modification of the Hough transform using the principle of template matching. The Hough transform was initially developed to detect analytically defined shapes. In these cases, we have knowledge of the shape and aim to find out its location and orientation in the image. This modification enables the Hough transform to be used to detect an arbitrary object described with its model.

In celestial mechanics, a Kepler orbit is the motion of one body relative to another, as an ellipse, parabola, or hyperbola, which forms a two-dimensional orbital plane in three-dimensional space. A Kepler orbit can also form a straight line. It considers only the point-like gravitational attraction of two bodies, neglecting perturbations due to gravitational interactions with other objects, atmospheric drag, solar radiation pressure, a non-spherical central body, and so on. It is thus said to be a solution of a special case of the two-body problem, known as the Kepler problem. As a theory in classical mechanics, it also does not take into account the effects of general relativity. Keplerian orbits can be parametrized into six orbital elements in various ways.
Hough transforms are techniques for object detection, a critical step in many implementations of computer vision, or data mining from images. Specifically, the Randomized Hough transform is a probabilistic variant to the classical Hough transform, and is commonly used to detect curves The basic idea of Hough transform (HT) is to implement a voting procedure for all potential curves in the image, and at the termination of the algorithm, curves that do exist in the image will have relatively high voting scores. Randomized Hough transform (RHT) is different from HT in that it tries to avoid conducting the computationally expensive voting process for every nonzero pixel in the image by taking advantage of the geometric properties of analytical curves, and thus improve the time efficiency and reduce the storage requirement of the original algorithm.
Chessboards arise frequently in computer vision theory and practice because their highly structured geometry is well-suited for algorithmic detection and processing. The appearance of chessboards in computer vision can be divided into two main areas: camera calibration and feature extraction. This article provides a unified discussion of the role that chessboards play in the canonical methods from these two areas, including references to the seminal literature, examples, and pointers to software implementations.
The circle Hough Transform (CHT) is a basic feature extraction technique used in digital image processing for detecting circles in imperfect images. The circle candidates are produced by “voting” in the Hough parameter space and then selecting local maxima in an accumulator matrix.
In image analysis, the generalized structure tensor (GST) is an extension of the Cartesian structure tensor to curvilinear coordinates. It is mainly used to detect and to represent the "direction" parameters of curves, just as the Cartesian structure tensor detects and represents the direction in Cartesian coordinates. Curve families generated by pairs of locally orthogonal functions have been the best studied.
In image processing, line detection is an algorithm that takes a collection of n edge points and finds all the lines on which these edge points lie. The most popular line detectors are the Hough transform and convolution-based techniques.