
The Allan variance (AVAR), also known as two-sample variance, is a measure of frequency stability in clocks, oscillators and amplifiers. It is named after David W. Allan and expressed mathematically as . The Allan deviation (ADEV), also known as sigma-tau, is the square root of the Allan variance, .
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. MSE is a risk function, corresponding to the expected value of the squared error loss. The fact that MSE is almost always strictly positive is because of randomness or because the estimator does not account for information that could produce a more accurate estimate. In machine learning, specifically empirical risk minimization, MSE may refer to the empirical risk, as an estimate of the true MSE.

In statistics, an expectation–maximization (EM) algorithm is an iterative method to find (local) maximum likelihood or maximum a posteriori (MAP) estimates of parameters in statistical models, where the model depends on unobserved latent variables. The EM iteration alternates between performing an expectation (E) step, which creates a function for the expectation of the log-likelihood evaluated using the current estimate for the parameters, and a maximization (M) step, which computes parameters maximizing the expected log-likelihood found on the E step. These parameter-estimates are then used to determine the distribution of the latent variables in the next E step. It can be used, for example, to estimate a mixture of gaussians, or to solve the multiple linear regression problem.
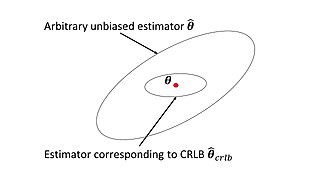
In estimation theory and statistics, the Cramér–Rao bound (CRB) relates to estimation of a deterministic parameter. The result is named in honor of Harald Cramér and C. R. Rao, but has also been derived independently by Maurice Fréchet, Georges Darmois, and by Alexander Aitken and Harold Silverstone. It states that the precision of any unbiased estimator is at most the Fisher information; or (equivalently) the reciprocal of the Fisher information is a lower bound on its variance.
In physics, the Hamilton–Jacobi equation, named after William Rowan Hamilton and Carl Gustav Jacob Jacobi, is an alternative formulation of classical mechanics, equivalent to other formulations such as Newton's laws of motion, Lagrangian mechanics and Hamiltonian mechanics.

In nuclear physics, the chiral model, introduced by Feza Gürsey in 1960, is a phenomenological model describing effective interactions of mesons in the chiral limit (where the masses of the quarks go to zero), but without necessarily mentioning quarks at all. It is a nonlinear sigma model with the principal homogeneous space of a Lie group as its target manifold. When the model was originally introduced, this Lie group was the SU(N), where N is the number of quark flavors. The Riemannian metric of the target manifold is given by a positive constant multiplied by the Killing form acting upon the Maurer–Cartan form of SU(N).
In statistics, the theory of minimum norm quadratic unbiased estimation (MINQUE) was developed by C. R. Rao. MINQUE is a theory alongside other estimation methods in estimation theory, such as the method of moments or maximum likelihood estimation. Similar to the theory of best linear unbiased estimation, MINQUE is specifically concerned with linear regression models. The method was originally conceived to estimate heteroscedastic error variance in multiple linear regression. MINQUE estimators also provide an alternative to maximum likelihood estimators or restricted maximum likelihood estimators for variance components in mixed effects models. MINQUE estimators are quadratic forms of the response variable and are used to estimate a linear function of the variances.
Estimation theory is a branch of statistics that deals with estimating the values of parameters based on measured empirical data that has a random component. The parameters describe an underlying physical setting in such a way that their value affects the distribution of the measured data. An estimator attempts to approximate the unknown parameters using the measurements. In estimation theory, two approaches are generally considered:

In probability theory and statistics, the continuous uniform distributions or rectangular distributions are a family of symmetric probability distributions. Such a distribution describes an experiment where there is an arbitrary outcome that lies between certain bounds. The bounds are defined by the parameters, and which are the minimum and maximum values. The interval can either be closed or open. Therefore, the distribution is often abbreviated where stands for uniform distribution. The difference between the bounds defines the interval length; all intervals of the same length on the distribution's support are equally probable. It is the maximum entropy probability distribution for a random variable under no constraint other than that it is contained in the distribution's support.
In Bayesian statistics, a maximum a posteriori probability (MAP) estimate is an estimate of an unknown quantity, that equals the mode of the posterior distribution. The MAP can be used to obtain a point estimate of an unobserved quantity on the basis of empirical data. It is closely related to the method of maximum likelihood (ML) estimation, but employs an augmented optimization objective which incorporates a prior distribution over the quantity one wants to estimate. MAP estimation can therefore be seen as a regularization of maximum likelihood estimation.
In statistics, the delta method is a method of deriving the asymptotic distribution of a random variable. It is applicable when the random variable being considered can be defined as a differentiable function of a random variable which is asymptotically Gaussian.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation.
In estimation theory and decision theory, a Bayes estimator or a Bayes action is an estimator or decision rule that minimizes the posterior expected value of a loss function. Equivalently, it maximizes the posterior expectation of a utility function. An alternative way of formulating an estimator within Bayesian statistics is maximum a posteriori estimation.
In statistics, the bias of an estimator is the difference between this estimator's expected value and the true value of the parameter being estimated. An estimator or decision rule with zero bias is called unbiased. In statistics, "bias" is an objective property of an estimator. Bias is a distinct concept from consistency: consistent estimators converge in probability to the true value of the parameter, but may be biased or unbiased; see bias versus consistency for more.
In mathematics, an elliptic hypergeometric series is a series Σcn such that the ratio cn/cn−1 is an elliptic function of n, analogous to generalized hypergeometric series where the ratio is a rational function of n, and basic hypergeometric series where the ratio is a periodic function of the complex number n. They were introduced by Date-Jimbo-Kuniba-Miwa-Okado (1987) and Frenkel & Turaev (1997) in their study of elliptic 6-j symbols.

In probability theory and directional statistics, a wrapped normal distribution is a wrapped probability distribution that results from the "wrapping" of the normal distribution around the unit circle. It finds application in the theory of Brownian motion and is a solution to the heat equation for periodic boundary conditions. It is closely approximated by the von Mises distribution, which, due to its mathematical simplicity and tractability, is the most commonly used distribution in directional statistics.

In statistics, maximum spacing estimation (MSE or MSP), or maximum product of spacing estimation (MPS), is a method for estimating the parameters of a univariate statistical model. The method requires maximization of the geometric mean of spacings in the data, which are the differences between the values of the cumulative distribution function at neighbouring data points.
The multi-fractional order estimator (MFOE) is a straightforward, practical, and flexible alternative to the Kalman filter (KF) for tracking targets. The MFOE is focused strictly on simple and pragmatic fundamentals along with the integrity of mathematical modeling. Like the KF, the MFOE is based on the least squares method (LSM) invented by Gauss and the orthogonality principle at the center of Kalman's derivation. Optimized, the MFOE yields better accuracy than the KF and subsequent algorithms such as the extended KF and the interacting multiple model (IMM). The MFOE is an expanded form of the LSM, which effectively includes the KF and ordinary least squares (OLS) as subsets. OLS is revolutionized in for application in econometrics. The MFOE also intersects with signal processing, estimation theory, economics, finance, statistics, and the method of moments. The MFOE offers two major advances: (1) minimizing the mean squared error (MSE) with fractions of estimated coefficients and (2) describing the effect of deterministic OLS processing of statistical inputs
In statistics, the Innovation Method provides an estimator for the parameters of stochastic differential equations given a time series of observations of the state variables. In the framework of continuous-discrete state space models, the innovation estimator is obtained by maximizing the log-likelihood of the corresponding discrete-time innovation process with respect to the parameters. The innovation estimator can be classified as a M-estimator, a quasi-maximum likelihood estimator or a prediction error estimator depending on the inferential considerations that want to be emphasized. The innovation method is a system identification technique for developing mathematical models of dynamical systems from measured data and for the optimal design of experiments.






















































