Related Research Articles
In computer science, an array is a data structure consisting of a collection of elements, of same memory size, each identified by at least one array index or key. An array is stored such that the position of each element can be computed from its index tuple by a mathematical formula. The simplest type of data structure is a linear array, also called a one-dimensional array.
Applesoft BASIC is a dialect of Microsoft BASIC, developed by Marc McDonald and Ric Weiland, supplied with Apple II computers. It supersedes Integer BASIC and is the BASIC in ROM in all Apple II series computers after the original Apple II model. It is also referred to as FP BASIC because of the Apple DOS command FP used to invoke it, instead of INT for Integer BASIC.

A hash function is any function that can be used to map data of arbitrary size to fixed-size values, though there are some hash functions that support variable-length output. The values returned by a hash function are called hash values, hash codes, hash digests, digests, or simply hashes. The values are usually used to index a fixed-size table called a hash table. Use of a hash function to index a hash table is called hashing or scatter-storage addressing.

A Universally Unique Identifier (UUID) is a 128-bit label used to uniquely identify objects in computer systems. The term Globally Unique Identifier (GUID) is also used, mostly in Microsoft systems.

Extract, transform, load (ETL) is a three-phase computing process where data is extracted from an input source, transformed, and loaded into an output data container. The data can be collected from one or more sources and it can also be output to one or more destinations. ETL processing is typically executed using software applications but it can also be done manually by system operators. ETL software typically automates the entire process and can be run manually or on recurring schedules either as single jobs or aggregated into a batch of jobs.
A foreign key is a set of attributes in a table that refers to the primary key of another table, linking these two tables. In the context of relational databases, a foreign key is subject to an inclusion dependency constraint that the tuples consisting of the foreign key attributes in one relation, R, must also exist in some other relation, S; furthermore that those attributes must also be a candidate key in S.
Commodore BASIC, also known as PET BASIC or CBM-BASIC, is the dialect of the BASIC programming language used in Commodore International's 8-bit home computer line, stretching from the PET (1977) to the Commodore 128 (1985).
In computer programming, a magic number is any of the following:

The syntax of the C programming language is the set of rules governing writing of software in C. It is designed to allow for programs that are extremely terse, have a close relationship with the resulting object code, and yet provide relatively high-level data abstraction. C was the first widely successful high-level language for portable operating-system development.
A surrogate key in a database is a unique identifier for either an entity in the modeled world or an object in the database. The surrogate key is not derived from application data, unlike a natural key.
Hashcash is a proof-of-work system used to limit email spam and denial-of-service attacks. Hashcash was proposed in 1997 by Adam Back and described more formally in Back's 2002 paper "Hashcash – A Denial of Service Counter-Measure". In Hashcash the client has to concatenate a random number with a string several times and hash this new string. It then has to do so over and over until a hash beginning with a certain number of zeros is found.
An SQL INSERT statement adds one or more records to any single table in a relational database.
Extensible Storage Engine (ESE), also known as JET Blue, is an ISAM data storage technology from Microsoft. ESE is the core of Microsoft Exchange Server, Active Directory, and Windows Search. It is also used by a number of Windows components including Windows Update client and Help and Support Center. Its purpose is to allow applications to store and retrieve data via indexed and sequential access.
AutoPlay, a feature introduced in Windows 98, examines newly discovered removable media and devices and, based on content such as pictures, music or video files, launches an appropriate application to play or display the content. It is closely related to the AutoRun operating system feature. AutoPlay was created in order to simplify the use of peripheral devices – MP3 players, memory cards, USB storage devices and others – by automatically starting the software needed to access and view the content on these devices. AutoPlay can be enhanced by AutoPlay-compatible software and hardware. It can be configured by the user to associate favourite applications with AutoPlay events and actions.
The Access Database Engine is a database engine on which several Microsoft products have been built. The first version of Jet was developed in 1992, consisting of three modules which could be used to manipulate a database.

The GUID Partition Table (GPT) is a standard for the layout of partition tables of a physical computer storage device, such as a hard disk drive or solid-state drive, using universally unique identifiers (UUIDs), which are also known as globally unique identifiers (GUIDs). Forming a part of the Unified Extensible Firmware Interface (UEFI) standard, it is nevertheless also used for some BIOSs, because of the limitations of master boot record (MBR) partition tables, which use 32 bits for logical block addressing (LBA) of traditional 512-byte disk sectors.
In relational database management systems, a unique key is a candidate key. All the candidate keys of a relation can uniquely identify the records of the relation, but only one of them is used as the primary key of the relation. The remaining candidate keys are called unique keys because they can uniquely identify a record in a relation. Unique keys can consist of multiple columns. Unique keys are also called alternate keys. Unique keys are an alternative to the primary key of the relation. In SQL, the unique keys have a UNIQUE constraint assigned to them in order to prevent duplicates. Alternate keys may be used like the primary key when doing a single-table select or when filtering in a where clause, but are not typically used to join multiple tables.
An identity column is a column in a database table that is made up of values generated by the database. This is much like an AutoNumber field in Microsoft Access or a sequence in Oracle. Because the concept is so important in database science, many RDBMS systems implement some type of generated key, although each has its own terminology. Today a popular technique for generating identity is to generate a random UUID.
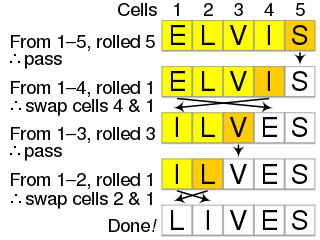
The Fisher–Yates shuffle is an algorithm for shuffling a finite sequence. The algorithm takes a list of all the elements of the sequence, and continually determines the next element in the shuffled sequence by randomly drawing an element from the list until no elements remain. The algorithm produces an unbiased permutation: every permutation is equally likely. The modern version of the algorithm takes time proportional to the number of items being shuffled and shuffles them in place.
Hi/Lo is an algorithm and a key generation strategy used for generating unique keys for use in a database as a primary key. It uses a sequence-based hi-lo pattern to generate values. Hi/Lo is used in scenarios where an application needs its entities to have an identity prior to persistence. It is a value generation strategy. An alternative to Hi/Lo would be for the application to generate keys as universally unique identifiers (UUID).
References
- ↑ Prague, Cary & Michael Irwin. Access 2002 Bible. New York: Wiley Publishing, Inc. p. 109.
- 1 2 3 4 5 6 7 8 9 10 11 Chris Grover; Matthew MacDonald & Emily A. Vander Veer (2007). Office 2007: The Missing Manual. O'Reilly. pp. 636–638. ISBN 9780596514228.
- 1 2 Microsoft (2006-01-09). "KBID 170117: How to use GUID fields in Access from Visual C++". Microsoft KnowledgeBase. Microsoft.
- 1 2 Microsoft (2009). "Microsoft Access Visual Basic reference: NewValues Property". MSDN . Microsoft. Retrieved 2009-07-05.