In coding theory, block codes are a large and important family of error-correcting codes that encode data in blocks. There is a vast number of examples for block codes, many of which have a wide range of practical applications. The abstract definition of block codes is conceptually useful because it allows coding theorists, mathematicians, and computer scientists to study the limitations of all block codes in a unified way. Such limitations often take the form of bounds that relate different parameters of the block code to each other, such as its rate and its ability to detect and correct errors.
Algebraic block codes are typically hard-decoded using algebraic decoders.[jargon]
The term block code may also refer to any error-correcting code that acts on a block of bits of input data to produce bits of output data . Consequently, the block coder is a memoryless device. Under this definition codes such as turbo codes, terminated convolutional codes and other iteratively decodable codes (turbo-like codes) would also be considered block codes. A non-terminated convolutional encoder would be an example of a non-block (unframed) code, which has memory and is instead classified as a tree code.
This article deals with "algebraic block codes".
The block code and its parameters
Error-correcting codes are used to reliably transmit digital data over unreliable communication channels subject to channel noise. When a sender wants to transmit a possibly very long data stream using a block code, the sender breaks the stream up into pieces of some fixed size. Each such piece is called message and the procedure given by the block code encodes each message individually into a codeword, also called a block in the context of block codes. The sender then transmits all blocks to the receiver, who can in turn use some decoding mechanism to (hopefully) recover the original messages from the possibly corrupted received blocks. The performance and success of the overall transmission depends on the parameters of the channel and the block code.
Here, is a finite and nonempty set and and are integers. The meaning and significance of these three parameters and other parameters related to the code are described below.
The alphabet Σ
The data stream to be encoded is modeled as a string over some alphabet. The size of the alphabet is often written as . If , then the block code is called a binary block code. In many applications it is useful to consider to be a prime power, and to identify with the finite field.
The message length k
Messages are elements of , that is, strings of length . Hence the number is called the message length or dimension of a block code.
The block length n
The block length of a block code is the number of symbols in a block. Hence, the elements of are strings of length and correspond to blocks that may be received by the receiver. Hence they are also called received words. If for some message , then is called the codeword of .
The rate R
The rate of a block code is defined as the ratio between its message length and its block length:
.
A large rate means that the amount of actual message per transmitted block is high. In this sense, the rate measures the transmission speed and the quantity measures the overhead that occurs due to the encoding with the block code. It is a simple information theoretical fact that the rate cannot exceed since data cannot in general be losslessly compressed. Formally, this follows from the fact that the code is an injective map.
The distance d
The distance or minimum distanced of a block code is the minimum number of positions in which any two distinct codewords differ, and the relative distance is the fraction . Formally, for received words , let denote the Hamming distance between and , that is, the number of positions in which and differ. Then the minimum distance of the code is defined as
.
Since any code has to be injective, any two codewords will disagree in at least one position, so the distance of any code is at least . Besides, the distance equals the minimum weight for linear block codes because:[citation needed]
.
A larger distance allows for more error correction and detection. For example, if we only consider errors that may change symbols of the sent codeword but never erase or add them, then the number of errors is the number of positions in which the sent codeword and the received word differ. A code with distance d allows the receiver to detect up to transmission errors since changing positions of a codeword can never accidentally yield another codeword. Furthermore, if no more than transmission errors occur, the receiver can uniquely decode the received word to a codeword. This is because every received word has at most one codeword at distance . If more than transmission errors occur, the receiver cannot uniquely decode the received word in general as there might be several possible codewords. One way for the receiver to cope with this situation is to use list decoding, in which the decoder outputs a list of all codewords in a certain radius.
Popular notation
The notation describes a block code over an alphabet of size , with a block length , message length , and distance . If the block code is a linear block code, then the square brackets in the notation are used to represent that fact. For binary codes with , the index is sometimes dropped. For maximum distance separable codes, the distance is always , but sometimes the precise distance is not known, non-trivial to prove or state, or not needed. In such cases, the -component may be missing.
Sometimes, especially for non-block codes, the notation is used for codes that contain codewords of length . For block codes with messages of length over an alphabet of size , this number would be .
Examples
As mentioned above, there are a vast number of error-correcting codes that are actually block codes. The first error-correcting code was the Hamming(7,4) code, developed by Richard W. Hamming in 1950. This code transforms a message consisting of 4 bits into a codeword of 7 bits by adding 3 parity bits. Hence this code is a block code. It turns out that it is also a linear code and that it has distance 3. In the shorthand notation above, this means that the Hamming(7,4) code is a code.
A codeword could be considered as a point in the -dimension space and the code is the subset of . A code has distance means that , there is no other codeword in the Hamming ball centered at with radius , which is defined as the collection of -dimension words whose Hamming distance to is no more than . Similarly, with (minimum) distance has the following properties:
can detect errors: Because a codeword is the only codeword in the Hamming ball centered at itself with radius , no error pattern of or fewer errors could change one codeword to another. When the receiver detects that the received vector is not a codeword of , the errors are detected (but no guarantee to correct).
can correct errors. Because a codeword is the only codeword in the Hamming ball centered at itself with radius , the two Hamming balls centered at two different codewords respectively with both radius do not overlap with each other. Therefore, if we consider the error correction as finding the codeword closest to the received word , as long as the number of errors is no more than , there is only one codeword in the hamming ball centered at with radius , therefore all errors could be corrected.
can correct erasures. By erasure it means that the position of the erased symbol is known. Correcting could be achieved by -passing decoding: In passing the erased position is filled with the symbol and error correcting is carried out. There must be one passing that the number of errors is no more than and therefore the erasures could be corrected.
Lower and upper bounds of block codes
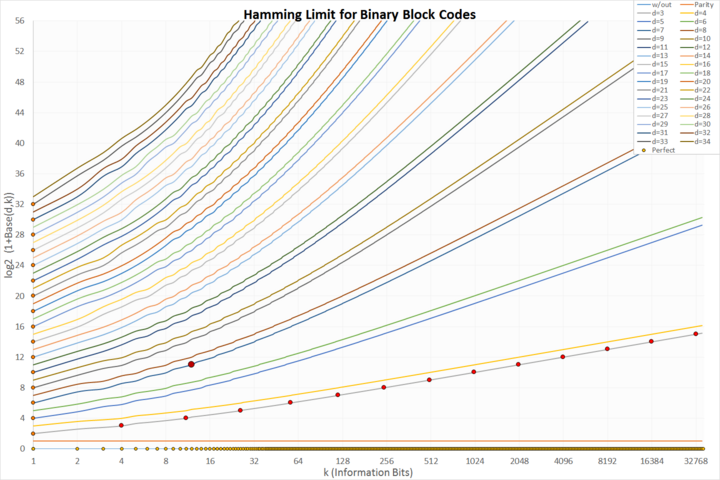
Hamming limit There are theoretical limits (such as the Hamming limit), but another question is which codes can actually constructed. It is like packing spheres in a box in many dimensions. This diagram shows the constructible codes, which are linear and binary. The x axis shows the number of protected symbols k, the y axis the number of needed check symbols n–k. Plotted are the limits for different Hamming distances from 1 (unprotected) to 34. Marked with dots are perfect codes:
light orange on x axis: trivial unprotected codes
orange on y axis: trivial repeat codes
dark orange on data set d=3: classic perfect Hamming codes
dark red and larger: the only perfect binary Golay code
Family of codes
is called family of codes, where is an code with monotonic increasing .
Rate of family of codes C is defined as
Relative distance of family of codes C is defined as
To explore the relationship between and , a set of lower and upper bounds of block codes are known.
The Singleton bound is that the sum of the rate and the relative distance of a block code cannot be much larger than 1:
.
In other words, every block code satisfies the inequality . Reed–Solomon codes are non-trivial examples of codes that satisfy the singleton bound with equality.
Block codes are tied to the sphere packing problem which has received some attention over the years. In two dimensions, it is easy to visualize. Take a bunch of pennies flat on the table and push them together. The result is a hexagon pattern like a bee's nest. But block codes rely on more dimensions which cannot easily be visualized. The powerful Golay code used in deep space communications uses 24 dimensions. If used as a binary code (which it usually is), the dimensions refer to the length of the codeword as defined above.
The theory of coding uses the N-dimensional sphere model. For example, how many pennies can be packed into a circle on a tabletop or in 3 dimensions, how many marbles can be packed into a globe. Other considerations enter the choice of a code. For example, hexagon packing into the constraint of a rectangular box will leave empty space at the corners. As the dimensions get larger, the percentage of empty space grows smaller. But at certain dimensions, the packing uses all the space and these codes are the so-called perfect codes. There are very few of these codes.
Another property is the number of neighbors a single codeword may have.[1] Again, consider pennies as an example. First we pack the pennies in a rectangular grid. Each penny will have 4 near neighbors (and 4 at the corners which are farther away). In a hexagon, each penny will have 6 near neighbors. Respectively, in three and four dimensions, the maximum packing is given by the 12-face and 24-cell with 12 and 24 neighbors, respectively. When we increase the dimensions, the number of near neighbors increases very rapidly. In general, the value is given by the kissing numbers.
The result is that the number of ways for noise to make the receiver choose a neighbor (hence an error) grows as well. This is a fundamental limitation of block codes, and indeed all codes. It may be harder to cause an error to a single neighbor, but the number of neighbors can be large enough so the total error probability actually suffers.[1]
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.