In computational complexity theory, a branch of computer science, bounded-error probabilistic polynomial time (BPP) is the class of decision problems solvable by a probabilistic Turing machine in polynomial time with an error probability bounded by 1/3 for all instances. BPP is one of the largest practical classes of problems, meaning most problems of interest in BPP have efficient probabilistic algorithms that can be run quickly on real modern machines. BPP also contains P, the class of problems solvable in polynomial time with a deterministic machine, since a deterministic machine is a special case of a probabilistic machine.
The P versus NP problem is a major unsolved problem in theoretical computer science. Informally, it asks whether every problem whose solution can be quickly verified can also be quickly solved.
In theoretical computer science and mathematics, computational complexity theory focuses on classifying computational problems according to their resource usage, and explores the relationships between these classifications. A computational problem is a task solved by a computer. A computation problem is solvable by mechanical application of mathematical steps, such as an algorithm.

In computational complexity theory, NP is a complexity class used to classify decision problems. NP is the set of decision problems for which the problem instances, where the answer is "yes", have proofs verifiable in polynomial time by a deterministic Turing machine, or alternatively the set of problems that can be solved in polynomial time by a nondeterministic Turing machine.
In computational complexity theory, the complexity class #P (pronounced "sharp P" or, sometimes "number P" or "hash P") is the set of the counting problems associated with the decision problems in the set NP. More formally, #P is the class of function problems of the form "compute f(x)", where f is the number of accepting paths of a nondeterministic Turing machine running in polynomial time. Unlike most well-known complexity classes, it is not a class of decision problems but a class of function problems. The most difficult, representative problems of this class are #P-complete.
In complexity theory, computational problems that are co-NP-complete are those that are the hardest problems in co-NP, in the sense that any problem in co-NP can be reformulated as a special case of any co-NP-complete problem with only polynomial overhead. If P is different from co-NP, then all of the co-NP-complete problems are not solvable in polynomial time. If there exists a way to solve a co-NP-complete problem quickly, then that algorithm can be used to solve all co-NP problems quickly.
In computational complexity theory, a computational problem H is called NP-hard if, for every problem L which can be solved in non-deterministic polynomial-time, there is a polynomial-time reduction from L to H. That is, assuming a solution for H takes 1 unit time, H's solution can be used to solve L in polynomial time. As a consequence, finding a polynomial time algorithm to solve a single NP-hard problem would give polynomial time algorithms for all the problems in the complexity class NP. As it is suspected, but unproven, that P≠NP, it is unlikely that any polynomial-time algorithms for NP-hard problems exist.
In computational complexity theory, randomized polynomial time (RP) is the complexity class of problems for which a probabilistic Turing machine exists with these properties:
In complexity theory, UP is the complexity class of decision problems solvable in polynomial time on an unambiguous Turing machine with at most one accepting path for each input. UP contains P and is contained in NP.

In computational complexity theory, a complexity class is a set of computational problems "of related resource-based complexity". The two most commonly analyzed resources are time and memory.
In computer science, parameterized complexity is a branch of computational complexity theory that focuses on classifying computational problems according to their inherent difficulty with respect to multiple parameters of the input or output. The complexity of a problem is then measured as a function of those parameters. This allows the classification of NP-hard problems on a finer scale than in the classical setting, where the complexity of a problem is only measured as a function of the number of bits in the input. This appears to have been first demonstrated in Gurevich, Stockmeyer & Vishkin (1984). The first systematic work on parameterized complexity was done by Downey & Fellows (1999).
In computational complexity theory, P, also known as PTIME or DTIME(nO(1)), is a fundamental complexity class. It contains all decision problems that can be solved by a deterministic Turing machine using a polynomial amount of computation time, or polynomial time.
In computational complexity theory, the polynomial hierarchy is a hierarchy of complexity classes that generalize the classes NP and co-NP. Each class in the hierarchy is contained within PSPACE. The hierarchy can be defined using oracle machines or alternating Turing machines. It is a resource-bounded counterpart to the arithmetical hierarchy and analytical hierarchy from mathematical logic. The union of the classes in the hierarchy is denoted PH.
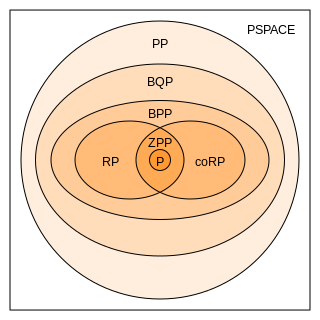
In complexity theory, PP, or PPT is the class of decision problems solvable by a probabilistic Turing machine in polynomial time, with an error probability of less than 1/2 for all instances. The abbreviation PP refers to probabilistic polynomial time. The complexity class was defined by Gill in 1977.
In computational complexity theory, the Cook–Levin theorem, also known as Cook's theorem, states that the Boolean satisfiability problem is NP-complete. That is, it is in NP, and any problem in NP can be reduced in polynomial time by a deterministic Turing machine to the Boolean satisfiability problem.
In computational complexity theory, a function problem is a computational problem where a single output is expected for every input, but the output is more complex than that of a decision problem. For function problems, the output is not simply 'yes' or 'no'.
In computational complexity theory, the class APX is the set of NP optimization problems that allow polynomial-time approximation algorithms with approximation ratio bounded by a constant. In simple terms, problems in this class have efficient algorithms that can find an answer within some fixed multiplicative factor of the optimal answer.
In computational complexity theory, the language TQBF is a formal language consisting of the true quantified Boolean formulas. A (fully) quantified Boolean formula is a formula in quantified propositional logic where every variable is quantified, using either existential or universal quantifiers, at the beginning of the sentence. Such a formula is equivalent to either true or false. If such a formula evaluates to true, then that formula is in the language TQBF. It is also known as QSAT.

In computational complexity theory, a problem is NP-complete when:
- It is a decision problem, meaning that for any input to the problem, the output is either "yes" or "no".
- When the answer is "yes", this can be demonstrated through the existence of a short solution.
- The correctness of each solution can be verified quickly and a brute-force search algorithm can find a solution by trying all possible solutions.
- The problem can be used to simulate every other problem for which we can verify quickly that a solution is correct. In this sense, NP-complete problems are the hardest of the problems to which solutions can be verified quickly. If we could find solutions of some NP-complete problem quickly, we could quickly find the solutions of every other problem to which a given solution can be easily verified.
In computational complexity theory, NP/poly is a complexity class, a non-uniform analogue of the class NP of problems solvable in polynomial time by a non-deterministic Turing machine. It is the non-deterministic complexity class corresponding to the deterministic class P/poly.






