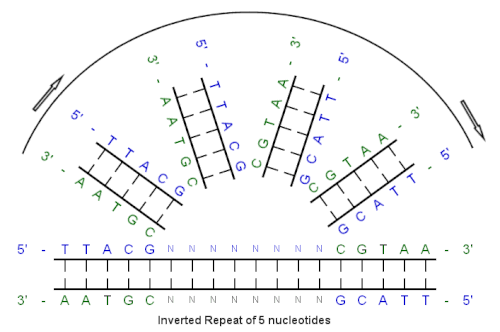
An inverted repeat (or IR) is a single stranded sequence of nucleotides followed downstream by its reverse complement.[1] The intervening sequence of nucleotides between the initial sequence and the reverse complement can be any length including zero. For example, 5'---TTACGnnnnnnCGTAA---3' is an inverted repeat sequence. When the intervening length is zero, the composite sequence is a palindromic sequence.[2]
Both inverted repeats and direct repeats constitute types of nucleotide sequences that occur repetitively. These repeated DNA sequences often range from a pair of nucleotides to a whole gene, while the proximity of the repeat sequences varies between widely dispersed and simple tandem arrays.[3] The short tandem repeat sequences may exist as just a few copies in a small region to thousands of copies dispersed all over the genome of most eukaryotes.[4] Repeat sequences with about 10–100 base pairs are known as minisatellites, while shorter repeat sequences having mostly 2–4 base pairs are known as microsatellites.[5] The most common repeats include the dinucleotide repeats, which have the bases AC on one DNA strand, and GT on the complementary strand.[3] Some elements of the genome with unique sequences function as exons, introns and regulatory DNA.[6] Though the most familiar loci of the repetitive sequences are the centromere and the telomere,[6] a large portion of the repeated sequences in the genome are found among the noncoding DNA.[5]
Inverted repeats have a number of important biological functions. They define the boundaries in transposons and indicate regions capable of self-complementary base pairing (regions within a single sequence which can base pair with each other). These properties play an important role in genome instability[7] and contribute not only to cellular evolution and genetic diversity[8] but also to mutation and disease.[9] In order to study these effects in detail, a number of programs and databases have been developed to assist in discovery and annotation of inverted repeats in various genomes.
Understanding inverted repeats
Example of an inverted repeat
The 5 base-pair sequence on the left is "repeated" and "inverted" to form sequence on the right.
Beginning with this initial sequence: 5'-TTACG-3'
The complement created by base pairing is: 3'-AATGC-5'
The reverse complement is: 5'-CGTAA-3'
And, the inverted repeat sequence is: 5'---TTACGnnnnnnCGTAA---3'
"nnnnnn" represents any number of intervening nucleotides.
Vs. direct repeat
A direct repeat occurs when a sequence is repeated with the same pattern downstream.[1] There is no inversion and no reverse complement associated with a direct repeat. The nucleotide sequence written in bold characters signifies the repeated sequence. It may or may not have intervening nucleotides.
5´ TTACGnnnnnnTTACG 3´
3´ AATGCnnnnnnAATGC 5´
Linguistically, a typical direct repeat is comparable to rhyming, as in "time on a dime".
A direct repeat with no intervening nucleotides between the initial sequence and its downstream copy is a Tandem repeat. The nucleotide sequence written in bold characters signifies the repeated sequence.
5´ TTACGTTACG 3´
3´ AATGCAATGC 5´
Linguistically, a typical tandem repeat is comparable to stuttering, or deliberately repeated words, as in "bye-bye".
An inverted repeat sequence with no intervening nucleotides between the initial sequence and its downstream reverse complement is a palindrome.[1] EXAMPLE: Step 1: start with an inverted repeat: 5' TTACGnnnnnnCGTAA 3' Step 2: remove intervening nucleotides: 5' TTACGCGTAA 3' This resulting sequence is palindromic because it is the reverse complement of itself.[1]
5' TTACGCGTAA 3' test sequence (from Step 2 with intervening nucleotides removed)
3' AATGCGCATT 5' complement of test sequence
5' TTACGCGTAA 3' reverse complement This is the same as the test sequence above, and thus, it is a palindrome.
Biological features and functionality
Conditions that favor synthesis
The diverse genome-wide repeats are derived from transposable elements, which are now understood to "jump" about different genomic locations, without transferring their original copies.[10] Subsequent shuttling of the same sequences over numerous generations ensures their multiplicity throughout the genome.[10] The limited recombination of the sequences between two distinct sequence elements known as conservative site-specific recombination (CSSR) results in inversions of the DNA segment, based on the arrangement of the recombination recognition sequences on the donor DNA and recipient DNA.[10] Again, the orientation of two of the recombining sites within the donor DNA molecule relative to the asymmetry of the intervening DNA cleavage sequences, known as the crossover region, is pivotal to the formation of either inverted repeats or direct repeats.[10] Thus, recombination occurring at a pair of inverted sites will invert the DNA sequence between the two sites.[10]Very stable chromosomes have been observed with comparatively fewer numbers of inverted repeats than direct repeats, suggesting a relationship between chromosome stability and the number of repeats.[11]
Regions where presence is obligatory
Terminal inverted repeats have been observed in the DNA of various eukaryotic transposons, even though their source remains unknown.[12] Inverted repeats are principally found at the origins of replication of cell organism and organelles that range from phage plasmids, mitochondria, and eukaryotic viruses to mammalian cells.[13] The replication origins of the phage G4 and other related phages comprise a segment of nearly 139 nucleotide bases that include three inverted repeats that are essential for replication priming.[13]
In the genome
To a large extent, portions of nucleotide repeats are quite often observed as part of rare DNA combinations.[14] The three main repeats which are largely found in particular DNA constructs include the closely precise homopurine-homopyrimidine inverted repeats, which is otherwise referred to as H palindromes, a common occurrence in triple helical H conformations that may comprise either the TAT or CGC nucleotide triads. The others could be described as long inverted repeats having the tendency to produce hairpins and cruciform, and finally direct tandem repeats, which commonly exist in structures described as slipped-loop, cruciform and left-handed Z-DNA.[14]
Common in different organisms
Past studies suggest that repeats are a common feature of eukaryotes unlike the prokaryotes and archaea.[14] Other reports suggest that irrespective of the comparative shortage of repeat elements in prokaryotic genomes, they nevertheless contain hundreds or even thousands of large repeats.[15] Current genomic analysis seem to suggest the existence of a large excess of perfect inverted repeats in many prokaryotic genomes as compared to eukaryotic genomes.[16]
Pseudoknot with four sets of inverted repeats. Inverted repeats 1 and 2 create the stem for stem-loop A and are part of the loop for stem-loop B. Similarly, inverted repeats 3 and 4 form the stem for stem-loop B and are part of the loop for stem-loop A.
For quantification and comparison of inverted repeats between several species, namely on archaea, see [17]
Inverted repeats in pseudoknots
Pseudoknots are common structural motifs found in RNA. They are formed by two nested stem-loops such that the stem of one structure is formed from the loop of the other. There are multiple folding topologies among pseudoknots and great variation in loop lengths, making them a structurally diverse group.[18]
Inverted repeats are a key component of pseudoknots as can be seen in the illustration of a naturally occurring pseudoknot found in the human telomerase RNA component.[19] Four different sets of inverted repeats are involved in this structure. Sets 1 and 2 are the stem of stem-loop A and are part of the loop for stem-loop B. Similarly, sets 3 and 4 are the stem for stem-loop B and are part of the loop for stem-loop A.
Pseudoknots play a number of different roles in biology. The telomerase pseudoknot in the illustration is critical to that enzyme's activity.[19] The ribozyme for the hepatitis delta virus (HDV) folds into a double-pseudoknot structure and self-cleaves its circular genome to produce a single-genome-length RNA. Pseudoknots also play a role in programmed ribosomal frameshifting found in some viruses and required in the replication of retroviruses.[18]
In riboswitches
Inverted repeats play an important role in riboswitches, which are RNA regulatory elements that control the expression of genes that produce the mRNA, of which they are part.[10] A simplified example of the flavin mononucleotide (FMN) riboswitch is shown in the illustration. This riboswitch exists in the mRNA transcript and has several stem-loop structures upstream from the coding region. However, only the key stem-loops are shown in the illustration, which has been greatly simplified to help show the role of the inverted repeats. There are multiple inverted repeats in this riboswitch as indicated in green (yellow background) and blue (orange background).
In the absence of FMN, the Anti-termination structure is the preferred conformation for the mRNA transcript. It is created by base-pairing of the inverted repeat region circled in red. When FMN is present, it may bind to the loop and prevent formation of the Anti-termination structure. This allows two different sets of inverted repeats to base-pair and form the Termination structure.[20] The stem-loop on the 3' end is a transcriptional terminator because the sequence immediately following it is a string of uracils (U). If this stem-loop forms (due to the presence of FMN) as the growing RNA strand emerges from the RNA polymerase complex, it will create enough structural tension to cause the RNA strand to dissociate and thus terminate transcription. The dissociation occurs easily because the base-pairing between the U's in the RNA and the A's in the template strand are the weakest of all base-pairings.[10] Thus, at higher concentration levels, FMN down-regulates its own transcription by increasing the formation of the termination structure.
Mutations and disease
Inverted repeats are often described as "hotspots" of eukaryotic and prokaryotic genomic instability.[7] Long inverted repeats are deemed to greatly influence the stability of the genome of various organisms.[21] This is exemplified in E. coli, where genomic sequences with long inverted repeats are seldom replicated, but rather deleted with rapidity.[21] Again, the long inverted repeats observed in yeast greatly favor recombination within the same and adjacent chromosomes, resulting in an equally very high rate of deletion.[21] Finally, a very high rate of deletion and recombination were also observed in mammalian chromosomes regions with inverted repeats.[21] Reported differences in the stability of genomes of interrelated organisms are always an indication of a disparity in inverted repeats.[11] The instability results from the tendency of inverted repeats to fold into hairpin- or cruciform-like DNA structures. These special structures can hinder or confuse DNA replication and other genomic activities.[7] Thus, inverted repeats lead to special configurations in both RNA and DNA that can ultimately cause mutations and disease.[9]
Inverted repeat changing to/from an extruded cruciform. A: Inverted Repeat Sequences; B: Loop; C: Stem with base pairing of the inverted repeat sequences
The illustration shows an inverted repeat undergoing cruciform extrusion. DNA in the region of the inverted repeat unwinds and then recombines, forming a four-way junction with two stem-loop structures. The cruciform structure occurs because the inverted repeat sequences self-pair to each other on their own strand.[22]
Extruded cruciforms can lead to frameshift mutations when a DNA sequence has inverted repeats in the form of a palindrome combined with regions of direct repeats on either side. During transcription, slippage and partial dissociation of the polymerase from the template strand can lead to both deletion and insertion mutations.[9] Deletion occurs when a portion of the unwound template strand forms a stem-loop that gets "skipped" by the transcription machinery. Insertion occurs when a stem-loop forms in a dissociated portion of the nascent (newly synthesized) strand causing a portion of the template strand to be transcribed twice.[9]
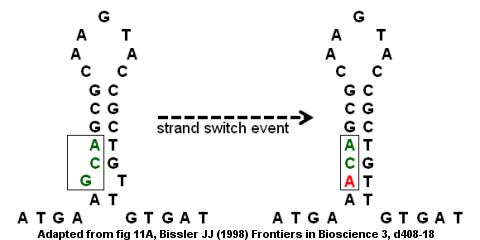
Antithrombin deficiency from a point mutation
Imperfect inverted repeats can lead to mutations through intrastrand and interstrand switching.[9] The antithrombin III gene's coding region is an example of an imperfect inverted repeat as shown in the figure on the right. The stem-loop structure forms with a bump at the bottom because the G and T do not pair up. A strand switch event could result in the G (in the bump) being replaced by an A which removes the "imperfection" in the inverted repeat and provides a stronger stem-loop structure. However, the replacement also creates a point mutation converting the GCA codon to ACA. If the strand switch event is followed by a second round of DNA replication, the mutation may become fixed in the genome and lead to disease. Specifically, the missense mutation would lead to a defective gene and a deficiency in antithrombin which could result in the development of venous thromboembolism (blood clots within a vein).[9]
Osteogenesis imperfecta from a frameshift mutation
Mutations in the collagen gene can lead to the disease Osteogenesis Imperfecta, which is characterized by brittle bones.[9] In the illustration, a stem-loop formed from an imperfect inverted repeat is mutated with a thymine (T) nucleotide insertion as a result of an inter- or intrastrand switch. The addition of the T creates a base-pairing "match up" with the adenine (A) that was previously a "bump" on the left side of the stem. While this addition makes the stem stronger and perfects the inverted repeat, it also creates a frameshift mutation in the nucleotide sequence which alters the reading frame and will result in an incorrect expression of the gene.[9]
Programs and databases
The following list provides information and external links to various programs and databases for inverted repeats:
non-B DB A Database for Integrated Annotations and Analysis of non-B DNA Forming Motifs.[23] This database is provided by The Advanced Biomedical Computing Center (ABCC) at then Frederick National Laboratory for Cancer Research (FNLCR). It covers the A-DNA and Z-DNA conformations otherwise known as "non-B DNAs" because they are not the more common B-DNA form of a right-handed Watson-Crick double-helix. These "non-B DNAs" include left-handed Z-DNA, cruciform, triplex, tetraplex and hairpin structures.[23] Searches can be performed on a variety of "repeat types" (including inverted repeats) and on several species.
Inverted Repeats DatabaseArchived 2020-09-01 at the Wayback Machine Boston University. This database is a web application that allows query and analysis of repeats held in the PUBLIC DATABASE project. Scientists can also analyze their own sequences with the Inverted Repeats Finder algorithm.[24]
EMBOSS is the "European Molecular Biology Open Software Suite" which runs on UNIX and UNIX-like operating systems.[26] Documentation and program source files are available on the EMBOSS website. Applications specifically related to inverted repeats are listed below:
EMBOSS palindrome: Finds palindromes such as stem loop regions in nucleotide sequences. The program will find sequences that include sections of mismatches and gaps that may correspond to bulges in a stem loop.[26]
References
1234Ussery, David W.; Wassenaar, Trudy; Borini, Stefano (2008-12-22). "Word Frequencies, Repeats, and Repeat-related Structures in Bacterial Genomes". Computing for Comparative Microbial Genomics: Bioinformatics for Microbiologists. Computational Biology. Vol.8 (1ed.). Springer. pp.133–144. ISBN978-1-84800-254-8.
1234567School, James D. Watson, Cold Spring Harbor Laboratory, Tania A. Baker, Massachusetts Institute of Technology, Stephen P. Bell, Massachusetts Institute of Technology, Alexander Gann, Cold Spring Harbor Laboratory, Michael Levine, University of California, Berkeley, Richard Losik, Harvard University; with Stephen C. Harrison, Harvard Medical (2014). Molecular biology of the gene (Seventhed.). Boston: Benjamin-Cummings Publishing Company. ISBN978-0-321-76243-6.{{cite book}}: CS1 maint: multiple names: authors list (link)
↑Hosseini, M; Pratas, D; Pinho, AJ (2017). "On the Role of Inverted Repeats in DNA Sequence Similarity". 11th International Conference on Practical Applications of Computational Biology & Bioinformatics. Advances in Intelligent Systems and Computing. Vol.616. Springer. pp.228–236. doi:10.1007/978-3-319-60816-7_28. ISBN978-3-319-60815-0.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.