Small molecules, proteins, and nucleic acids have also been found to stimulate levels of frameshifting. In December 2023, it was reported that in vitro-transcribed (IVT) mRNAs in response to BNT162b2 (Pfizer–BioNTech) anti-COVID-19 vaccine caused ribosomal frameshifting.[4]
Process overview
Proteins are translated by reading tri-nucleotides on the mRNA strand, also known as codons, from one end of the mRNA to the other (from the 5' to the 3' end) starting with the amino acid methionine as the start (initiation) codon AUG. Each codon is translated into a single amino acid. The code itself is considered degenerate, meaning that a particular amino acid can be specified by more than one codon. However, a shift of any number of nucleotides that is not divisible by 3 in the reading frame will cause subsequent codons to be read differently.[5] This effectively changes the ribosomal reading frame.
Sentence example
In this example, the following sentence of three-letter words makes sense when read from the beginning:
|Start|THE CAT AND THE MAN ARE FAT ... |Start|123 123 123 123 123 123 123 ...
However, if the reading frame is shifted by one letter to between the T and H of the first word (effectively a +1 frameshift when considering the 0 position to be the initial position of T),
T|Start|HEC ATA NDT HEM ANA REF AT... -|Start|123 123 123 123 123 123 12...
then the sentence reads differently, making no sense.
|Start|AAC GAA AAT CTG TTC GCT TCA ... |Start|123 123 123 123 123 123 123 ... | AA | N E N L F A S ...
However, let's change the reading frame by starting one nucleotide downstream (effectively a "+1 frameshift" when considering the 0 position to be the initial position of A):
A|Start|ACG AAA ATC TGT TCG CTT CA... -|Start|123 123 123 123 123 123 12... | AA | T K I C S L ...
Because of this +1 frameshifting, the DNA sequence is read differently. The different codon reading frame therefore yields different amino acids.
Effect
In the case of a translating ribosome, a frameshift can either result in nonsense mutation, a premature stop codon after the frameshift, or the creation of a completely new protein after the frameshift. In the case where a frameshift results in nonsense, the nonsense-mediated mRNA decay (NMD) pathway may destroy the mRNA transcript, so frameshifting would serve as a method of regulating the expression level of the associated gene.[6]
If a novel or off-target protein is produced, it can trigger other unknown consequences.[4]
Function in viruses and eukaryotes
In viruses this phenomenon may be programmed to occur at particular sites and allows the virus to encode multiple types of proteins from the same mRNA. Notable examples include HIV-1 (human immunodeficiency virus),[7] RSV (Rous sarcoma virus)[8] and the influenza virus (flu),[9] which all rely on frameshifting to create a proper ratio of 0-frame (normal translation) and "trans-frame" (encoded by frameshifted sequence) proteins. Its use in viruses is primarily for compacting more genetic information into a shorter amount of genetic material.
In eukaryotes it appears to play a role in regulating gene expression levels by generating premature stops and producing nonfunctional transcripts.[3][10]
Types of frameshifting
The most common type of frameshifting is −1 frameshifting or programmed −1 ribosomal frameshifting (−1 PRF). Other, rarer types of frameshifting include +1 and −2 frameshifting.[2] −1 and +1 frameshifting are believed to be controlled by different mechanisms, which are discussed below. Both mechanisms are kinetically driven.
Programmed −1 ribosomal frameshifting
Tandem slippage of 2 tRNAs at rous sarcoma virus slippery sequence. After the frameshift, new base pairings are correct at the first and second nucleotides but incorrect at wobble position. E, P, and A sites of the ribosome are indicated. Location of growing polypeptide chain is not indicated in image because there is not yet consensus on whether the −1 slip occurs before or after polypeptide is transferred from P-site tRNA to A-site tRNA (in this case from the Asn tRNA to the Leu tRNA).
In −1 frameshifting, the ribosome slips back one nucleotide and continues translation in the −1 frame. There are typically three elements that comprise a −1 frameshift signal: a slippery sequence, a spacer region, and an RNA secondary structure. The slippery sequence fits a X_XXY_YYH motif, where XXX is any three identical nucleotides (though some exceptions occur), YYY typically represents UUU or AAA, and H is A, C or U. Because the structure of this motif contains 2 adjacent 3-nucleotide repeats it is believed that −1 frameshifting is described by a tandem slippage model, in which the ribosomal P-site tRNA anticodon re-pairs from XXY to XXX and the A-site anticodon re-pairs from YYH to YYY simultaneously. These new pairings are identical to the 0-frame pairings except at their third positions. This difference does not significantly disfavor anticodon binding because the third nucleotide in a codon, known as the wobble position, has weaker tRNA anticodon binding specificity than the first and second nucleotides.[2][11] In this model, the motif structure is explained by the fact that the first and second positions of the anticodons must be able to pair perfectly in both the 0 and −1 frames. Therefore, nucleotides 2 and 1 must be identical, and nucleotides 3 and 2 must also be identical, leading to a required sequence of 3 identical nucleotides for each tRNA that slips.[12]
+1 ribosomal frameshifting
+1 frameshift occurs as ribosome and P-site tRNA pause to wait for arrival of rare arginine tRNA. The A-site codon in the new frame pairs to anticodon of more common glycine tRNA, and translation continues.
The slippery sequence for a +1 frameshift signal does not have the same motif, and instead appears to function by pausing the ribosome at a sequence encoding a rare amino acid.[13] Ribosomes do not translate proteins at a steady rate, regardless of the sequence. Certain codons take longer to translate, because there are not equal amounts of tRNA of that particular codon in the cytosol.[14] Due to this lag, there exist in small sections of codons sequences that control the rate of ribosomal frameshifting. Specifically, the ribosome must pause to wait for the arrival of a rare tRNA, and this increases the kinetic favorability of the ribosome and its associated tRNA slipping into the new frame.[13][15] In this model, the change in reading frame is caused by a single tRNA slip rather than two.
Controlling mechanisms
Ribosomal frameshifting may be controlled by mechanisms found in the mRNA sequence (cis-acting). This generally refers to a slippery sequence, an RNA secondary structure, or both. A −1 frameshift signal consists of both elements separated by a spacer region typically 5–9 nucleotides long.[2] Frameshifting may also be induced by other molecules which interact with the ribosome or the mRNA (trans-acting).
Frameshift signal elements
This is a graphical representation of the HIV1 frameshift signal. A −1 frameshift in the slippery sequence region results in translation of the pol instead of the gag protein-coding region, or open reading frame (ORF). Both gag and pol proteins are required for reverse transcriptase, which is essential to HIV1 replication.
Slippery sequence
Slippery sequences can potentially make the reading ribosome "slip" and skip a number of nucleotides (usually only 1) and read a completely different frame thereafter. In programmed −1 ribosomal frameshifting, the slippery sequence fits a X_XXY_YYH motif, where XXX is any three identical nucleotides (though some exceptions occur), YYY typically represents UUU or AAA, and H is A, C or U. In the case of +1 frameshifting, the slippery sequence contains codons for which the corresponding tRNA is more rare, and the frameshift is favored because the codon in the new frame has a more common associated tRNA.[13] One example of a slippery sequence is the polyA on mRNA, which is known to induce ribosome slippage even in the absence of any other elements.[16]
RNA secondary structure
Efficient ribosomal frameshifting generally requires the presence of an RNA secondary structure to enhance the effects of the slippery sequence.[12] The RNA structure (which can be a stem-loop or pseudoknot) is thought to pause the ribosome on the slippery site during translation, forcing it to relocate and continue replication from the −1 position. It is believed that this occurs because the structure physically blocks movement of the ribosome by becoming stuck in the ribosome mRNA tunnel.[2] This model is supported by the fact that strength of the pseudoknot has been positively correlated with the level of frameshifting for associated mRNA.[3][17]
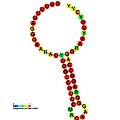
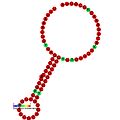
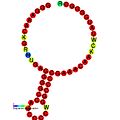
Below are examples of predicted secondary structures for frameshift elements shown to stimulate frameshifting in a variety of organisms. The majority of the structures shown are stem-loops, with the exception of the ALIL (apical loop-internal loop) pseudoknot structure. In these images, the larger and incomplete circles of mRNA represent linear regions. The secondary "stem-loop" structures, where "stems" are formed by a region of mRNA base pairing with another region on the same strand, are shown protruding from the linear DNA. The linear region of the HIV ribosomal frameshift signal contains a highly conserved UUU UUU A slippery sequence; many of the other predicted structures contain candidates for slippery sequences as well.
The mRNA sequences in the images can be read according to a set of guidelines. While A, T, C, and G represent a particular nucleotide at a position, there are also letters that represent ambiguity which are used when more than one kind of nucleotide could occur at that position. The rules of the International Union of Pure and Applied Chemistry (IUPAC) are as follows:[18]
Small molecules, proteins, and nucleic acids have been found to stimulate levels of frameshifting. For example, the mechanism of a negative feedback loop in the polyamine synthesis pathway is based on polyamine levels stimulating an increase in +1 frameshifts, which results in production of an inhibitory enzyme. Certain proteins which are needed for codon recognition or which bind directly to the mRNA sequence have also been shown to modulate frameshifting levels. MicroRNA (miRNA) molecules may hybridize to an RNA secondary structure and affect its strength.[6]
Recode2 — Database of recoded genes, including those that require programmed Translational frameshift.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.