
Intermediate filament family orphan 1 is a protein that in humans is encoded by the IFFO1 gene. IFFO1 has uncharacterized function and a weight of 61.98 kDa. IFFO1 proteins play an important role in the cytoskeleton and the nuclear envelope of most eukaryotic cell types.

Chromosome 9 open reading frame 152 is a protein that in humans is encoded by the C9orf152 gene. The exact function of the protein is not completely understood.

Uncharacterized protein C2orf73 is a protein that in humans is encoded by the C2orf73 gene. The protein is predicted to be localized to the nucleus.

Transmembrane protein 255A is a protein that is encoded by the TMEM255A gene. TMEM255A is often referred to as family with sequence similarity 70, member A (FAM70A). The TMEM255A protein is transmembrane and is predicted to be located the nuclear envelope of eukaryote organisms.
Proline-rich protein 30 is a protein in humans that is encoded for by the PRR30 gene. PRR30 is a member in the family of Proline-rich proteins characterized by their intrinsic lack of structure. Copy number variations in the PRR30 gene have been associated with an increased risk for neurofibromatosis.

Chromosome 21 Open Reading Frame 58 (C21orf58) is a protein that in humans is encoded by the C21orf58 gene.

SHLD1 or shieldin complex subunit 1 is a gene on chromosome 20. The C20orf196 gene encodes an mRNA that is 1,763 base pairs long, and a protein that is 205 amino acids long.

Chromosome 19 open reading frame 44 is a protein that in humans is encoded by the C19orf44 gene. C19orf44 is an uncharacterized protein with an unknown function in humans. C19orf44 is non-limiting implying that the protein exists in other species besides human. The protein contains one domain of unknown function (DUF) that is highly conserved throughout its orthologs. This protein is most highly expressed in the testis and ovary, but also has significant expression in the thyroid and parathyroid. Other names for this protein include: LOC84167.
WD Repeat and Coiled-coiled containing protein (WDCP) is a protein which in humans is encoded by the WDCP gene. The function of the protein is not completely understood, but WDCP has been identified in a fusion protein with anaplastic lymphoma kinase found in colorectal cancer. WDCP has also been identified in the MRN complex, which processes double-stranded breaks in DNA.
C12orf24 is a gene in humans that encodes a protein known as FAM216A. This gene is primarily expressed in the testis and brain, but has constitutive expression in 25 other tissues. FAM216A is an intracellular protein that has been predicted to reside within the nucleus of cells. The exact function of C12orf24 is unknown. FAM216A is highly expressed in Sertoli cells of the testis as well as different stage spermatids.

C6orf136 is a protein in humans encoded by the C6orf136 gene. The gene is conserved in mammals, mollusks, as well some porifera. While the function of the gene is currently unknown, C6orf136 has been shown to be hypermethylated in response to FOXM1 expression in Head Neck Squamous Cell Carcinoma (HNSCC) tissue cells. Additionally, elevated expression of C6orf136 has been associated with improved survival rates in patients with bladder cancer. C6orf136 has three known isoforms.
FAM237A is a protein coding gene which encodes a protein of the same name. Within Homo sapiens, FAM237A is believed to be primarily expressed within the brain, with moderate heart and lesser testes expression,. FAM237A is hypothesized to act as a specific activator of receptor GPR83.
TBC1D30 is a gene in the human genome that encodes the protein of the same name. This protein has two domains, one of which is involved in the processing of the Rab protein. Much of the function of this gene is not yet known, but it is expressed mostly in the brain and adrenal cortex.
TEKTIP1, also known as tektin-bundle interacting protein 1, is a protein that in humans is encoded by the TEKTIP1 gene.
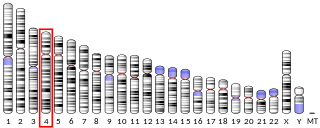
Chromosome 4 Open Reading Frame 45 (C4orf45) is a protein which in humans is encoded by the C4orf45 gene. It is predicted to be localized in the cytoplasm and nucleus of a cell

C13orf42 is a protein which, in humans, is encoded by the gene chromosome 13 open reading frame 42 (C13orf42). RNA sequencing data shows low expression of the C13orf42 gene in a variety of tissues. The C13orf42 protein is predicted to be localized in the mitochondria, nucleus, and cytosol. Tertiary structure predictions for C13orf42 indicate multiple alpha helices.
Chromosome 12 open reading frame 71 (c12orf71) is a protein which in humans is encoded by c12orf71 gene. The protein is also known by the alias LOC728858.

THAP domain-containing protein 3 (THAP3) is a protein that, in Homo sapiens (humans), is encoded by the THAP3 gene. The THAP3 protein is as known as MGC33488, LOC90326, and THAP domain-containing, apoptosis associated protein 3. This protein contains the Thanatos-associated protein (THAP) domain and a host-cell factor 1C binding motif. These domains allow THAP3 to influence a variety of processes, including transcription and neuronal development. THAP3 is ubiquitously expressed in H. sapiens, though expression is highest in the kidneys.
Chromosome 13 Open Reading Frame 46 is a protein which in humans is encoded by the C13orf46 gene. In humans, C13orf46 is ubiquitously expressed at low levels in tissues, including the lungs, stomach, prostate, spleen, and thymus. This gene encodes eight alternatively spliced mRNA transcript, which produce five different protein isoforms.

Chromosome 5 Open Reading Frame 47, or C5ORF47, is a protein which, in humans, is encoded by the C5ORF47 gene. It also goes by the alias LOC133491. The human C5ORF47 gene is primarily expressed in the testis.






