
In computing, multitasking is the concurrent execution of multiple tasks over a certain period of time. New tasks can interrupt already started ones before they finish, instead of waiting for them to end. As a result, a computer executes segments of multiple tasks in an interleaved manner, while the tasks share common processing resources such as central processing units (CPUs) and main memory. Multitasking automatically interrupts the running program, saving its state and loading the saved state of another program and transferring control to it. This "context switch" may be initiated at fixed time intervals, or the running program may be coded to signal to the supervisory software when it can be interrupted.
In computing, a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point, and then restoring a different, previously saved, state. This allows multiple processes to share a single central processing unit (CPU), and is an essential feature of a multiprogramming or multitasking operating system. In a traditional CPU, each process - a program in execution - utilizes the various CPU registers to store data and hold the current state of the running process. However, in a multitasking operating system, the operating system switches between processes or threads to allow the execution of multiple processes simultaneously. For every switch, the operating system must save the state of the currently running process, followed by loading the next process state, which will run on the CPU. This sequence of operations that stores the state of the running process and the loading of the following running process is called a context switch.

In digital computers, an interrupt is a request for the processor to interrupt currently executing code, so that the event can be processed in a timely manner. If the request is accepted, the processor will suspend its current activities, save its state, and execute a function called an interrupt handler to deal with the event. This interruption is often temporary, allowing the software to resume normal activities after the interrupt handler finishes, although the interrupt could instead indicate a fatal error.
In computing, interrupt latency refers to the delay between the start of an Interrupt Request (IRQ) and the start of the respective Interrupt Service Routine (ISR). For many operating systems, devices are serviced as soon as the device's interrupt handler is executed. Interrupt latency may be affected by microprocessor design, interrupt controllers, interrupt masking, and the operating system's (OS) interrupt handling methods.
An operating system (OS) is system software that manages computer hardware and software resources, and provides common services for computer programs.
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
In computing, a segmentation fault or access violation is a fault, or failure condition, raised by hardware with memory protection, notifying an operating system (OS) the software has attempted to access a restricted area of memory. On standard x86 computers, this is a form of general protection fault. The operating system kernel will, in response, usually perform some corrective action, generally passing the fault on to the offending process by sending the process a signal. Processes can in some cases install a custom signal handler, allowing them to recover on their own, but otherwise the OS default signal handler is used, generally causing abnormal termination of the process, and sometimes a core dump.

In computing, a process is the instance of a computer program that is being executed by one or many threads. There are many different process models, some of which are light weight, but almost all processes are rooted in an operating system (OS) process which comprises the program code, assigned system resources, physical and logical access permissions, and data structures to initiate, control and coordinate execution activity. Depending on the OS, a process may be made up of multiple threads of execution that execute instructions concurrently.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. The implementation of threads and processes differs between operating systems. In Modern Operating Systems, Tanenbaum shows that many distinct models of process organization are possible. In many cases, a thread is a component of a process. The multiple threads of a given process may be executed concurrently, sharing resources such as memory, while different processes do not share these resources. In particular, the threads of a process share its executable code and the values of its dynamically allocated variables and non-thread-local global variables at any given time.
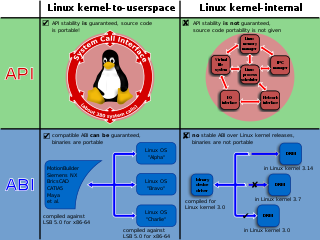
In computing, a system call is the programmatic way in which a computer program requests a service from the operating system on which it is executed. This may include hardware-related services, creation and execution of new processes, and communication with integral kernel services such as process scheduling. System calls provide an essential interface between a process and the operating system.

A memory management unit (MMU), sometimes called paged memory management unit (PMMU), is a computer hardware unit that examines all memory references on the memory bus, translating these requests, known as virtual memory addresses, into physical addresses in main memory.
Execution in computer and software engineering is the process by which a computer or virtual machine reads and acts on the instructions of a computer program. Each instruction of a program is a description of a particular action which must be carried out, in order for a specific problem to be solved. Execution involves repeatedly following a 'fetch–decode–execute' cycle for each instruction done by control unit. As the executing machine follows the instructions, specific effects are produced in accordance with the semantics of those instructions.
RTLinux is a hard realtime real-time operating system (RTOS) microkernel that runs the entire Linux operating system as a fully preemptive process. The hard real-time property makes it possible to control robots, data acquisition systems, manufacturing plants, and other time-sensitive instruments and machines from RTLinux applications. The design was patented. Despite the similar name, it is not related to the Real-Time Linux project of the Linux Foundation.

A general protection fault (GPF) in the x86 instruction set architectures (ISAs) is a fault initiated by ISA-defined protection mechanisms in response to an access violation caused by some running code, either in the kernel or a user program. The mechanism is first described in Intel manuals and datasheets for the Intel 80286 CPU, which was introduced in 1983; it is also described in section 9.8.13 in the Intel 80386 programmer's reference manual from 1986. A general protection fault is implemented as an interrupt. Some operating systems may also classify some exceptions not related to access violations, such as illegal opcode exceptions, as general protection faults, even though they have nothing to do with memory protection. If a CPU detects a protection violation, it stops executing the code and sends a GPF interrupt. In most cases, the operating system removes the failing process from the execution queue, signals the user, and continues executing other processes. If, however, the operating system fails to catch the general protection fault, i.e. another protection violation occurs before the operating system returns from the previous GPF interrupt, the CPU signals a double fault, stopping the operating system. If yet another failure occurs, the CPU is unable to recover; since 80286, the CPU enters a special halt state called "Shutdown", which can only be exited through a hardware reset. The IBM PC AT, the first PC-compatible system to contain an 80286, has hardware that detects the Shutdown state and automatically resets the CPU when it occurs. All descendants of the PC AT do the same, so in a PC, a triple fault causes an immediate system reset.
In computing, a memory barrier, also known as a membar, memory fence or fence instruction, is a type of barrier instruction that causes a central processing unit (CPU) or compiler to enforce an ordering constraint on memory operations issued before and after the barrier instruction. This typically means that operations issued prior to the barrier are guaranteed to be performed before operations issued after the barrier.
Signals are standardized messages sent to a running program to trigger specific behavior, such as quitting or error handling. They are a limited form of inter-process communication (IPC), typically used in Unix, Unix-like, and other POSIX-compliant operating systems.
In computer science, asynchronous I/O is a form of input/output processing that permits other processing to continue before the transmission has finished. A name used for asynchronous I/O in the Windows API is overlapped I/O.
In computer security, executable-space protection marks memory regions as non-executable, such that an attempt to execute machine code in these regions will cause an exception. It makes use of hardware features such as the NX bit, or in some cases software emulation of those features. However, technologies that emulate or supply an NX bit will usually impose a measurable overhead while using a hardware-supplied NX bit imposes no measurable overhead.
DioneOS is a multitasking preemptive, real-time operating system (RTOS). The system is designed for microcontrollers, originally released on 2 February 2011 for the Texas Instruments TI MSP430x, and then on 29 March 2013 for the ARM Cortex-M3. Target microcontroller platforms have limited resources, i.e., system clock frequency of tens of MHz, and memory amounts of tens to a few hundred kilobytes (KB). The RTOS is adapted to such conditions by providing a compact and efficient image. The efficiency term here means minimizing further central processing unit (CPU) load caused by system use. According to this definition, the system is more effective when it consumes less CPU time to execute its internal parts, e.g., managing threads.

The ARM Cortex-R is a family of 32-bit and 64-bit RISC ARM processor cores licensed by Arm Holdings. The cores are optimized for hard real-time and safety-critical applications. Cores in this family implement the ARM Real-time (R) profile, which is one of three architecture profiles, the other two being the Application (A) profile implemented by the Cortex-A family and the Microcontroller (M) profile implemented by the Cortex-M family. The ARM Cortex-R family of microprocessors currently consists of ARM Cortex-R4(F), ARM Cortex-R5(F), ARM Cortex-R7(F), ARM Cortex-R8(F), ARM Cortex-R52(F), and ARM Cortex-R82(F).