Related Research Articles
Computer vision tasks include methods for acquiring, processing, analyzing and understanding digital images, and extraction of high-dimensional data from the real world in order to produce numerical or symbolic information, e.g. in the forms of decisions. Understanding in this context means the transformation of visual images into descriptions of the world that make sense to thought processes and can elicit appropriate action. This image understanding can be seen as the disentangling of symbolic information from image data using models constructed with the aid of geometry, physics, statistics, and learning theory.
Random sample consensus (RANSAC) is an iterative method to estimate parameters of a mathematical model from a set of observed data that contains outliers, when outliers are to be accorded no influence on the values of the estimates. Therefore, it also can be interpreted as an outlier detection method. It is a non-deterministic algorithm in the sense that it produces a reasonable result only with a certain probability, with this probability increasing as more iterations are allowed. The algorithm was first published by Fischler and Bolles at SRI International in 1981. They used RANSAC to solve the Location Determination Problem (LDP), where the goal is to determine the points in the space that project onto an image into a set of landmarks with known locations.
In computer vision, the fundamental matrix is a 3×3 matrix which relates corresponding points in stereo images. In epipolar geometry, with homogeneous image coordinates, x and x′, of corresponding points in a stereo image pair, Fx describes a line on which the corresponding point x′ on the other image must lie. That means, for all pairs of corresponding points holds

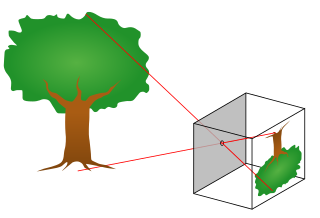
Epipolar geometry is the geometry of stereo vision. When two cameras view a 3D scene from two distinct positions, there are a number of geometric relations between the 3D points and their projections onto the 2D images that lead to constraints between the image points. These relations are derived based on the assumption that the cameras can be approximated by the pinhole camera model.
In computer vision, the essential matrix is a matrix, that relates corresponding points in stereo images assuming that the cameras satisfy the pinhole camera model.

Andrew Blake FREng, FRS, is a British scientist, former laboratory director of Microsoft Research Cambridge and Microsoft Distinguished Scientist, former director of the Alan Turing Institute, Chair of the Samsung AI Centre in Cambridge, honorary professor at the University of Cambridge, Fellow of Clare Hall, Cambridge, and a leading researcher in computer vision.

Image rectification is a transformation process used to project images onto a common image plane. This process has several degrees of freedom and there are many strategies for transforming images to the common plane. Image rectification is used in computer stereo vision to simplify the problem of finding matching points between images, and in geographic information systems to merge images taken from multiple perspectives into a common map coordinate system.

The Department of Engineering Science is the engineering department of the University of Oxford. It is part of the university's Mathematical, Physical and Life Sciences Division. The department was ranked third best institute in the UK for engineering in the 2021 Research Excellence Framework.
The pinhole camera model describes the mathematical relationship between the coordinates of a point in three-dimensional space and its projection onto the image plane of an ideal pinhole camera, where the camera aperture is described as a point and no lenses are used to focus light. The model does not include, for example, geometric distortions or blurring of unfocused objects caused by lenses and finite sized apertures. It also does not take into account that most practical cameras have only discrete image coordinates. This means that the pinhole camera model can only be used as a first order approximation of the mapping from a 3D scene to a 2D image. Its validity depends on the quality of the camera and, in general, decreases from the center of the image to the edges as lens distortion effects increase.
In photogrammetry and computer stereo vision, bundle adjustment is simultaneous refining of the 3D coordinates describing the scene geometry, the parameters of the relative motion, and the optical characteristics of the camera(s) employed to acquire the images, given a set of images depicting a number of 3D points from different viewpoints. Its name refers to the geometrical bundles of light rays originating from each 3D feature and converging on each camera's optical center, which are adjusted optimally according to an optimality criterion involving the corresponding image projections of all points.
Object recognition – technology in the field of computer vision for finding and identifying objects in an image or video sequence. Humans recognize a multitude of objects in images with little effort, despite the fact that the image of the objects may vary somewhat in different view points, in many different sizes and scales or even when they are translated or rotated. Objects can even be recognized when they are partially obstructed from view. This task is still a challenge for computer vision systems. Many approaches to the task have been implemented over multiple decades.
In computer vision, the trifocal tensor is a 3×3×3 array of numbers that incorporates all projective geometric relationships among three views. It relates the coordinates of corresponding points or lines in three views, being independent of the scene structure and depending only on the relative motion among the three views and their intrinsic calibration parameters. Hence, the trifocal tensor can be considered as the generalization of the fundamental matrix in three views. It is noted that despite the tensor being made up of 27 elements, only 18 of them are actually independent.

Leonidas John Guibas is the Paul Pigott Professor of Computer Science and Electrical Engineering at Stanford University. He heads the Geometric Computation group in the Computer Science Department.
Brian A. Barsky is a professor at the University of California, Berkeley, working in computer graphics and geometric modeling as well as in optometry and vision science. He is a Professor of Computer Science and Vision Science and an Affiliate Professor of Optometry. He is also a member of the Joint Graduate Group in Bioengineering, an inter-campus program, between UC Berkeley and UC San Francisco.
Andrew Zisserman is a British computer scientist and a professor at the University of Oxford, and a researcher in computer vision. As of 2014 he is affiliated with DeepMind.
Camera auto-calibration is the process of determining internal camera parameters directly from multiple uncalibrated images of unstructured scenes. In contrast to classic camera calibration, auto-calibration does not require any special calibration objects in the scene. In the visual effects industry, camera auto-calibration is often part of the "Match Moving" process where a synthetic camera trajectory and intrinsic projection model are solved to reproject synthetic content into video.

In the field of computer vision, any two images of the same planar surface in space are related by a homography. This has many practical applications, such as image rectification, image registration, or camera motion—rotation and translation—between two images. Once camera resectioning has been done from an estimated homography matrix, this information may be used for navigation, or to insert models of 3D objects into an image or video, so that they are rendered with the correct perspective and appear to have been part of the original scene.

Sir John Michael Brady is an emeritus professor of oncological imaging at the University of Oxford. He has been a Fellow of Keble College, Oxford, since 1985 and was elected a foreign associate member of the French Academy of Sciences in 2015. He was formerly BP Professor of Information Engineering at Oxford from 1985 to 2010 and a senior research scientist in the MIT Computer Science and Artificial Intelligence Laboratory (CSAIL) in Cambridge, Massachusetts, from 1980 to 1985.
Christopher Kenneth Ingle Williams is a professor at the School of Informatics, University of Edinburgh, working in Artificial intelligence, and particularly the areas of Machine learning and Computer vision.
References
- ↑ "Department of Computer Science - December 7, 2010 - Richard Hartley". Johns Hopkins Whiting School of Engineering. Retrieved 30 August 2014.
- ↑ WorldCat book entry
- ↑ "Richard Hartley". Australian Academy of Science. Retrieved 14 March 2023.
- ↑ "Decoding dragons and devils, what triggers volcanoes, and more: Australia's stars of science". Australian Academy of Science. 14 March 2023. Retrieved 14 March 2023.
- ↑ "Richard Hartley".
- ↑ Multiple View Geometry in Computer Vision Second Edition. Retrieved May 20, 2009.