The likelihood function is the joint probability of the observed data viewed as a function of the parameters of a statistical model.
In statistics, maximum likelihood estimation (MLE) is a method of estimating the parameters of an assumed probability distribution, given some observed data. This is achieved by maximizing a likelihood function so that, under the assumed statistical model, the observed data is most probable. The point in the parameter space that maximizes the likelihood function is called the maximum likelihood estimate. The logic of maximum likelihood is both intuitive and flexible, and as such the method has become a dominant means of statistical inference.

In probability theory and statistics, the beta distribution is a family of continuous probability distributions defined on the interval [0, 1] in terms of two positive parameters, denoted by alpha (α) and beta (β), that appear as exponents of the variable and its complement to 1, respectively, and control the shape of the distribution.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the base form
In probability theory and statistics, a Gaussian process is a stochastic process, such that every finite collection of those random variables has a multivariate normal distribution, i.e. every finite linear combination of them is normally distributed. The distribution of a Gaussian process is the joint distribution of all those random variables, and as such, it is a distribution over functions with a continuous domain, e.g. time or space.
In probability and statistics, an exponential family is a parametric set of probability distributions of a certain form, specified below. This special form is chosen for mathematical convenience, including the enabling of the user to calculate expectations, covariances using differentiation based on some useful algebraic properties, as well as for generality, as exponential families are in a sense very natural sets of distributions to consider. The term exponential class is sometimes used in place of "exponential family", or the older term Koopman–Darmois family. The terms "distribution" and "family" are often used loosely: specifically, an exponential family is a set of distributions, where the specific distribution varies with the parameter; however, a parametric family of distributions is often referred to as "a distribution", and the set of all exponential families is sometimes loosely referred to as "the" exponential family. They are distinct because they possess a variety of desirable properties, most importantly the existence of a sufficient statistic.
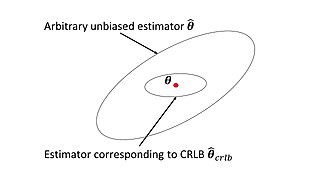
In estimation theory and statistics, the Cramér–Rao bound (CRB) relates to estimation of a deterministic parameter. The result is named in honor of Harald Cramér and C. R. Rao, but has also been derived independently by Maurice Fréchet, Georges Darmois, and by Alexander Aitken and Harold Silverstone. It states that the precision of any unbiased estimator is at most the Fisher information; or (equivalently) the inverse of the Fisher information is a lower bound on its variance.
In mathematical statistics, the Fisher information is a way of measuring the amount of information that an observable random variable X carries about an unknown parameter θ of a distribution that models X. Formally, it is the variance of the score, or the expected value of the observed information.
In mathematical statistics, the Kullback–Leibler divergence, denoted , is a type of statistical distance: a measure of how one probability distribution P is different from a second, reference probability distribution Q. A simple interpretation of the KL divergence of P from Q is the expected excess surprise from using Q as a model when the actual distribution is P. While it is a distance, it is not a metric, the most familiar type of distance: it is not symmetric in the two distributions, and does not satisfy the triangle inequality. Instead, in terms of information geometry, it is a type of divergence, a generalization of squared distance, and for certain classes of distributions, it satisfies a generalized Pythagorean theorem.
In statistics, the score test assesses constraints on statistical parameters based on the gradient of the likelihood function—known as the score—evaluated at the hypothesized parameter value under the null hypothesis. Intuitively, if the restricted estimator is near the maximum of the likelihood function, the score should not differ from zero by more than sampling error. While the finite sample distributions of score tests are generally unknown, they have an asymptotic χ2-distribution under the null hypothesis as first proved by C. R. Rao in 1948, a fact that can be used to determine statistical significance.
In decision theory and estimation theory, Stein's example is the observation that when three or more parameters are estimated simultaneously, there exist combined estimators more accurate on average than any method that handles the parameters separately. It is named after Charles Stein of Stanford University, who discovered the phenomenon in 1955.
In Bayesian probability, the Jeffreys prior, named after Sir Harold Jeffreys, is a non-informative prior distribution for a parameter space; its density function is proportional to the square root of the determinant of the Fisher information matrix:
In statistics, the delta method is a result concerning the approximate probability distribution for a function of an asymptotically normal statistical estimator from knowledge of the limiting variance of that estimator.
In statistics, M-estimators are a broad class of extremum estimators for which the objective function is a sample average. Both non-linear least squares and maximum likelihood estimation are special cases of M-estimators. The definition of M-estimators was motivated by robust statistics, which contributed new types of M-estimators. However, M-estimators are not inherently robust, as is clear from the fact that they include maximum likelihood estimators, which are in general not robust. The statistical procedure of evaluating an M-estimator on a data set is called M-estimation. 48 samples of robust M-estimators can be found in a recent review study.
In information theory and statistics, Kullback's inequality is a lower bound on the Kullback–Leibler divergence expressed in terms of the large deviations rate function. If P and Q are probability distributions on the real line, such that P is absolutely continuous with respect to Q, i.e. P << Q, and whose first moments exist, then
A product distribution is a probability distribution constructed as the distribution of the product of random variables having two other known distributions. Given two statistically independent random variables X and Y, the distribution of the random variable Z that is formed as the product is a product distribution.
In probability and statistics, a compound probability distribution is the probability distribution that results from assuming that a random variable is distributed according to some parametrized distribution, with the parameters of that distribution themselves being random variables. If the parameter is a scale parameter, the resulting mixture is also called a scale mixture.

In probability theory and statistics, the Hermite distribution, named after Charles Hermite, is a discrete probability distribution used to model count data with more than one parameter. This distribution is flexible in terms of its ability to allow a moderate over-dispersion in the data.
In statistics, the variance function is a smooth function which depicts the variance of a random quantity as a function of its mean. The variance function is a measure of heteroscedasticity and plays a large role in many settings of statistical modelling. It is a main ingredient in the generalized linear model framework and a tool used in non-parametric regression, semiparametric regression and functional data analysis. In parametric modeling, variance functions take on a parametric form and explicitly describe the relationship between the variance and the mean of a random quantity. In a non-parametric setting, the variance function is assumed to be a smooth function.
In econometrics, the information matrix test is used to determine whether a regression model is misspecified. The test was developed by Halbert White, who observed that in a correctly specified model and under standard regularity assumptions, the Fisher information matrix can be expressed in either of two ways: as the outer product of the gradient, or as a function of the Hessian matrix of the log-likelihood function.





























