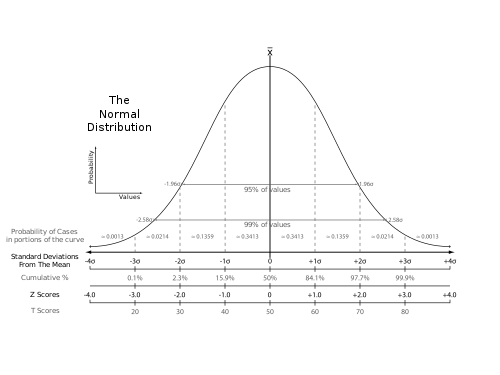
In statistics, the standard score or z-score is the number of standard deviations by which the value of a raw score (i.e., an observed value or data point) is above or below the mean value of what is being observed or measured. Raw scores above the mean have positive standard scores, while those below the mean have negative standard scores.
It is calculated by subtracting the population mean from an individual raw score and then dividing the difference by the population standard deviation. This process of converting a raw score into a standard score is called standardizing or normalizing (however, "normalizing" can refer to many types of ratios; see Normalization for more).
Standard scores are most commonly called z-scores; the two terms may be used interchangeably, as they are in this article. Other equivalent terms in use include z-value, z-statistic, normal score, standardized variable and pull in high energy physics.[1][2]
Computing a z-score requires knowledge of the mean and standard deviation of the complete population to which a data point belongs; if one only has a sample of observations from the population, then the analogous computation using the sample mean and sample standard deviation yields the t-statistic.
Calculation
If the population mean and population standard deviation are known, a raw score x is converted into a standard score by[3]
The absolute value of z represents the distance between that raw score x and the population mean in units of the standard deviation. z is negative when the raw score is below the mean, positive when above.
Calculating z using this formula requires use of the population mean and the population standard deviation, not the sample mean or sample deviation. However, knowing the true mean and standard deviation of a population is often an unrealistic expectation, except in cases such as standardized testing, where the entire population is measured.
When the population mean and the population standard deviation are unknown, the standard score may be estimated by using the sample mean and sample standard deviation as estimates of the population values.[4][5][6][7]
Though it should always be stated, the distinction between use of the population and sample statistics often is not made. In either case, the numerator and denominator of the equations have the same units of measure so that the units cancel out through division and z is left as a dimensionless quantity.
The z-score is often used in the z-test in standardized testing – the analog of the Student's t-test for a population whose parameters are known, rather than estimated. As it is very unusual to know the entire population, the t-test is much more widely used.
Prediction intervals
The standard score can be used in the calculation of prediction intervals. A prediction interval [L,U], consisting of a lower endpoint designated L and an upper endpoint designated U, is an interval such that a future observation X will lie in the interval with high probability , i.e.
In process control applications, the Z value provides an assessment of the degree to which a process is operating off-target.
Comparison of scores measured on different scales: ACT and SAT
The z score for Student A was 1, meaning Student A was 1 standard deviation above the mean. Thus, Student A performed in the 84.13 percentile on the SAT.
When scores are measured on different scales, they may be converted to z-scores to aid comparison. Dietz et al.[9] give the following example, comparing student scores on the (old) SAT and ACT high school tests. The table shows the mean and standard deviation for total scores on the SAT and ACT. Suppose that student A scored 1800 on the SAT, and student B scored 24 on the ACT. Which student performed better relative to other test-takers?
SAT
ACT
Mean
1500
21
Standard deviation
300
5
The z score for Student B was 0.6, meaning Student B was 0.6 standard deviation above the mean. Thus, Student B performed in the 72.57 percentile on the SAT.
The z-score for student A is
The z-score for student B is
Because student A has a higher z-score than student B, student A performed better compared to other test-takers than did student B.
Percentage of observations below a z-score
Continuing the example of ACT and SAT scores, if it can be further assumed that both ACT and SAT scores are normally distributed (which is approximately correct), then the z-scores may be used to calculate the percentage of test-takers who received lower scores than students A and B.
Cluster analysis and multidimensional scaling
"For some multivariate techniques such as multidimensional scaling and cluster analysis, the concept of distance between the units in the data is often of considerable interest and importance… When the variables in a multivariate data set are on different scales, it makes more sense to calculate the distances after some form of standardization."[10]
Principal components analysis
In principal components analysis, "Variables measured on different scales or on a common scale with widely differing ranges are often standardized."[11]
Relative importance of variables in multiple regression: standardized regression coefficients
Standardization of variables prior to multiple regression analysis is sometimes used as an aid to interpretation.[12] (page 95) state the following.
"The standardized regression slope is the slope in the regression equation if X and Y are standardized … Standardization of X and Y is done by subtracting the respective means from each set of observations and dividing by the respective standard deviations … In multiple regression, where several X variables are used, the standardized regression coefficients quantify the relative contribution of each X variable."
However, Kutner et al.[13] (p 278) give the following caveat: "… one must be cautious about interpreting any regression coefficients, whether standardized or not. The reason is that when the predictor variables are correlated among themselves, … the regression coefficients are affected by the other predictor variables in the model … The magnitudes of the standardized regression coefficients are affected not only by the presence of correlations among the predictor variables but also by the spacings of the observations on each of these variables. Sometimes these spacings may be quite arbitrary. Hence, it is ordinarily not wise to interpret the magnitudes of standardized regression coefficients as reflecting the comparative importance of the predictor variables."
If the random variable under consideration is the sample mean of a random sample of X:
then the standardized version is
Where the standardised sample mean's variance was calculated as follows:
T-score
"T-score" redirects here; not to be confused with t-statistic.
In educational assessment, T-score is a standard score Z shifted and scaled to have a mean of 50 and a standard deviation of 10.[14][15][16] It is also known as hensachi(ja; zh) in Japanese, where the concept is much more widely known and used in the context of high school and university admissions.[17]
In bone density measurement, the T-score is the standard score of the measurement compared to the population of healthy 30-year-old adults, and has the usual mean of 0 and standard deviation of 1.[18]
↑Spiegel, Murray R.; Stephens, Larry J (2008), Schaum's Outlines Statistics (Fourthed.), McGraw Hill, ISBN978-0-07-148584-5
↑Mendenhall, William; Sincich, Terry (2007), Statistics for Engineering and the Sciences (Fifthed.), Pearson / Prentice Hall, ISBN978-0131877061
↑Glantz, Stanton A.; Slinker, Bryan K.; Neilands, Torsten B. (2016), Primer of Applied Regression & Analysis of Variance (Thirded.), McGraw Hill, ISBN978-0071824118
↑Aho, Ken A. (2014), Foundational and Applied Statistics for Biologists (Firsted.), Chapman & Hall / CRC Press, ISBN978-1439873380
↑Afifi, Abdelmonem; May, Susanne K.; Clark, Virginia A. (2012), Practical Multivariate Analysis (Fifthed.), Chapman & Hall/CRC, ISBN978-1439816806
↑Kutner, Michael; Nachtsheim, Christopher; Neter, John (204), Applied Linear Regression Models (Fourthed.), McGraw Hill, ISBN978-0073014661{{citation}}: ISBN / Date incompatibility (help)
Larsen, Richard J.; Marx, Morris L. (2000). An Introduction to Mathematical Statistics and Its Applications (Thirded.). Prentice Hall. p.282. ISBN0-13-922303-7.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.