
In probability theory and statistics, variance is the expected value of the squared deviation from the mean of a random variable. The standard deviation (SD) is obtained as the square root of the variance. Variance is a measure of dispersion, meaning it is a measure of how far a set of numbers is spread out from their average value. It is the second central moment of a distribution, and the covariance of the random variable with itself, and it is often represented by , , , , or .
The weighted arithmetic mean is similar to an ordinary arithmetic mean, except that instead of each of the data points contributing equally to the final average, some data points contribute more than others. The notion of weighted mean plays a role in descriptive statistics and also occurs in a more general form in several other areas of mathematics.

In probability theory and statistics, the geometric distribution is either one of two discrete probability distributions:

In probability theory, a log-normal (or lognormal) distribution is a continuous probability distribution of a random variable whose logarithm is normally distributed. Thus, if the random variable X is log-normally distributed, then Y = ln(X) has a normal distribution. Equivalently, if Y has a normal distribution, then the exponential function of Y, X = exp(Y), has a log-normal distribution. A random variable which is log-normally distributed takes only positive real values. It is a convenient and useful model for measurements in exact and engineering sciences, as well as medicine, economics and other topics (e.g., energies, concentrations, lengths, prices of financial instruments, and other metrics).
Covariance in probability theory and statistics is a measure of the joint variability of two random variables.
In mathematics, a generating function is a representation of an infinite sequence of numbers as the coefficients of a formal power series. Unlike an ordinary series, the formal power series is not required to converge: in fact, the generating function is not actually regarded as a function, and the "variable" remains an indeterminate. Generating functions were first introduced by Abraham de Moivre in 1730, in order to solve the general linear recurrence problem. One can generalize to formal power series in more than one indeterminate, to encode information about infinite multi-dimensional arrays of numbers.

In mathematics, the error function, often denoted by erf, is a function defined as:

In statistics, the logistic model is a statistical model that models the log-odds of an event as a linear combination of one or more independent variables. In regression analysis, logistic regression is estimating the parameters of a logistic model. Formally, in binary logistic regression there is a single binary dependent variable, coded by an indicator variable, where the two values are labeled "0" and "1", while the independent variables can each be a binary variable or a continuous variable. The corresponding probability of the value labeled "1" can vary between 0 and 1, hence the labeling; the function that converts log-odds to probability is the logistic function, hence the name. The unit of measurement for the log-odds scale is called a logit, from logistic unit, hence the alternative names. See § Background and § Definition for formal mathematics, and § Example for a worked example.
In probability theory, the probability generating function of a discrete random variable is a power series representation (the generating function) of the probability mass function of the random variable. Probability generating functions are often employed for their succinct description of the sequence of probabilities Pr(X = i) in the probability mass function for a random variable X, and to make available the well-developed theory of power series with non-negative coefficients.
In mathematics, a Gaussian function, often simply referred to as a Gaussian, is a function of the base form
In probability theory and statistics, the cumulantsκn of a probability distribution are a set of quantities that provide an alternative to the moments of the distribution. Any two probability distributions whose moments are identical will have identical cumulants as well, and vice versa.
The Basel problem is a problem in mathematical analysis with relevance to number theory, concerning an infinite sum of inverse squares. It was first posed by Pietro Mengoli in 1650 and solved by Leonhard Euler in 1734, and read on 5 December 1735 in The Saint Petersburg Academy of Sciences. Since the problem had withstood the attacks of the leading mathematicians of the day, Euler's solution brought him immediate fame when he was twenty-eight. Euler generalised the problem considerably, and his ideas were taken up more than a century later by Bernhard Riemann in his seminal 1859 paper "On the Number of Primes Less Than a Given Magnitude", in which he defined his zeta function and proved its basic properties. The problem is named after Basel, hometown of Euler as well as of the Bernoulli family who unsuccessfully attacked the problem.

In probability theory, Buffon's needle problem is a question first posed in the 18th century by Georges-Louis Leclerc, Comte de Buffon:
In probability theory, a compound Poisson distribution is the probability distribution of the sum of a number of independent identically-distributed random variables, where the number of terms to be added is itself a Poisson-distributed variable. The result can be either a continuous or a discrete distribution.
In probability theory, the multinomial distribution is a generalization of the binomial distribution. For example, it models the probability of counts for each side of a k-sided dice rolled n times. For n independent trials each of which leads to a success for exactly one of k categories, with each category having a given fixed success probability, the multinomial distribution gives the probability of any particular combination of numbers of successes for the various categories.
In queueing theory, a discipline within the mathematical theory of probability, a Jackson network is a class of queueing network where the equilibrium distribution is particularly simple to compute as the network has a product-form solution. It was the first significant development in the theory of networks of queues, and generalising and applying the ideas of the theorem to search for similar product-form solutions in other networks has been the subject of much research, including ideas used in the development of the Internet. The networks were first identified by James R. Jackson and his paper was re-printed in the journal Management Science’s ‘Ten Most Influential Titles of Management Sciences First Fifty Years.’
In natural language processing, latent Dirichlet allocation (LDA) is a Bayesian network for modeling automatically extracted topics in textual corpora. The LDA is an example of a Bayesian topic model. In this, observations are collected into documents, and each word's presence is attributable to one of the document's topics. Each document will contain a small number of topics.
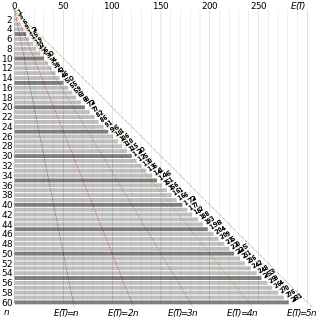
In probability theory, the coupon collector's problem refers to mathematical analysis of "collect all coupons and win" contests. It asks the following question: If each box of a brand of cereals contains a coupon, and there are n different types of coupons, what is the probability that more than t boxes need to be bought to collect all n coupons? An alternative statement is: Given n coupons, how many coupons do you expect you need to draw with replacement before having drawn each coupon at least once? The mathematical analysis of the problem reveals that the expected number of trials needed grows as . For example, when n = 50 it takes about 225 trials on average to collect all 50 coupons.
The purpose of this page is to provide supplementary materials for the ordinary least squares article, reducing the load of the main article with mathematics and improving its accessibility, while at the same time retaining the completeness of exposition.






























































