In statistics, mean absolute error (MAE) is a measure of errors between paired observations expressing the same phenomenon. Examples of Y versus X include comparisons of predicted versus observed, subsequent time versus initial time, and one technique of measurement versus an alternative technique of measurement. MAE is calculated as the sum of absolute errors (i.e., the Manhattan distance) divided by the sample size:[1]It is thus an arithmetic average of the absolute errors , where is the prediction and the true value. Alternative formulations may include relative frequencies as weight factors. The mean absolute error uses the same scale as the data being measured. This is known as a scale-dependent accuracy measure and therefore cannot be used to make comparisons between predicted values that use different scales.[2] The mean absolute error is a common measure of forecast error in time series analysis,[3] sometimes used in confusion with the more standard definition of mean absolute deviation. The same confusion exists more generally.
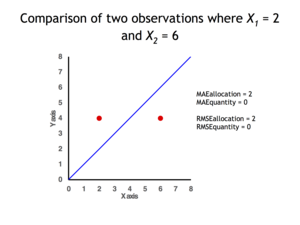
Two data points for which quantity disagreement is 0 and allocation disagreement is 2 for both MAE and RMSE.
In remote sensing the MAE is sometimes expressed as the sum of two components: quantity disagreement and allocation disagreement. Quantity disagreement is the absolute value of the mean error:[4]Allocation disagreement is MAE minus quantity disagreement.
It is also possible to identify the types of difference by looking at an plot. Quantity difference exists when the average of the X values does not equal the average of the Y values. Allocation difference exists if and only if points reside on both sides of the identity line.[4][5]
Related measures
The mean absolute error is one of a number of ways of comparing forecasts with their eventual outcomes. Well-established alternatives are the mean absolute scaled error (MASE), mean absolute log error (MALE), and the mean squared error. These all summarize performance in ways that disregard the direction of over- or under- prediction; a measure that does place emphasis on this is the mean signed difference.
Where a prediction model is to be fitted using a selected performance measure, in the sense that the least squares approach is related to the mean squared error, the equivalent for mean absolute error is least absolute deviations.
MAE is not identical to root-mean square error (RMSE), although some researchers report and interpret it that way. The MAE is conceptually simpler and also easier to interpret than RMSE: it is simply the average absolute vertical or horizontal distance between each point in a scatter plot and the Y=X line. In other words, MAE is the average absolute difference between X and Y. Furthermore, each error contributes to MAE in proportion to the absolute value of the error. This is in contrast to RMSE which involves squaring the differences, so that a few large differences will increase the RMSE to a greater degree than the MAE.[4]
Optimality property
The mean absolute error of a real variable c with respect to the random variableX isProvided that the probability distribution of X is such that the above expectation exists, then m is a median of X if and only if m is a minimizer of the mean absolute error with respect to X.[6] In particular, m is a sample median if and only if m minimizes the arithmetic mean of the absolute deviations.[7]
More generally, a median is defined as a minimum ofas discussed at Multivariate median (and specifically at Spatial median). This optimization-based definition of the median is useful in statistical data-analysis, for example, in k-medians clustering.
↑ Willmott, C. J.; Matsuura, K. (January 2006). "On the use of dimensioned measures of error to evaluate the performance of spatial interpolators". International Journal of Geographical Information Science. 20: 89–102. doi:10.1080/13658810500286976. S2CID15407960.
This page is based on this Wikipedia article Text is available under the CC BY-SA 4.0 license; additional terms may apply. Images, videos and audio are available under their respective licenses.