
Open content describes any work that others can copy or modify freely by attributing to the original creator, but without needing to ask for permission. This has been applied to a range of formats, including textbooks, academic journals, films and music. The term was an expansion of the related concept of open-source software. Such content is said to be under an open licence.
The Semantic Web is an extension of the World Wide Web through standards set by the World Wide Web Consortium (W3C). The goal of the Semantic Web is to make Internet data machine-readable. To enable the encoding of semantics with the data, technologies such as Resource Description Framework (RDF) and Web Ontology Language (OWL) are used. These technologies are used to formally represent metadata. For example, ontology can describe concepts, relationships between entities, and categories of things. These embedded semantics offer significant advantages such as reasoning over data and operating with heterogeneous data sources.

Data mining is the process of discovering patterns in large data sets involving methods at the intersection of machine learning, statistics, and database systems. Data mining is an interdisciplinary subfield of computer science and statistics with an overall goal to extract information from a data set and transform the information into a comprehensible structure for further use. Data mining is the analysis step of the "knowledge discovery in databases" process or KDD. Aside from the raw analysis step, it also involves database and data management aspects, data pre-processing, model and inference considerations, interestingness metrics, complexity considerations, post-processing of discovered structures, visualization, and online updating.

JSTOR is a digital library founded in 1995. Originally containing digitized back issues of academic journals, it now encompasses books and other primary sources as well as current issues of journals. It provides full-text searches of almost 2,000 journals.

A digital object identifier (DOI) is a persistent identifier or handle used to identify objects uniquely, standardized by the International Organization for Standardization (ISO). An implementation of the Handle System, DOIs are in wide use mainly to identify academic, professional, and government information, such as journal articles, research reports and data sets, and official publications though they also have been used to identify other types of information resources, such as commercial videos.
Species diversity is the number of different species that are represented in a given community. The effective number of species refers to the number of equally abundant species needed to obtain the same mean proportional species abundance as that observed in the dataset of interest. Meanings of species diversity may include species richness, taxonomic or phylogenetic diversity, and/or species evenness. Species richness is a simple count of species. Taxonomic or phylogenetic diversity is the genetic relationship between different groups of species. Species evenness quantifies how equal the abundances of the species are.
Consumer confidence is an economic indicator that measures the degree of optimism that consumers feel about the overall state of the economy and their personal financial situation. If the consumer has confidence in the immediate and near future economy and his/her personal finance, then the consumer will spend more than save.
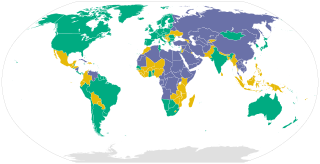
Freedom in the World is a yearly survey and report by the U.S.-based non-governmental organization Freedom House that measures the degree of civil liberties and political rights in every nation and significant related and disputed territories around the world.
Open data is the idea that some data should be freely available to everyone to use and republish as they wish, without restrictions from copyright, patents or other mechanisms of control. The goals of the open-source data movement are similar to those of other "open(-source)" movements such as open-source software, hardware, open content, open education, open educational resources, open government, open knowledge, open access, open science, and the open web. Paradoxically, the growth of the open data movement is paralleled by a rise in intellectual property rights. The philosophy behind open data has been long established, but the term "open data" itself is recent, gaining popularity with the rise of the Internet and World Wide Web and, especially, with the launch of open-data government initiatives such as Data.gov, Data.gov.uk and Data.gov.in.

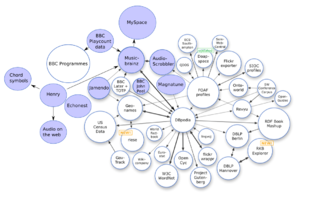
DBpedia is a project aiming to extract structured content from the information created in the Wikipedia project. This structured information is made available on the World Wide Web. DBpedia allows users to semantically query relationships and properties of Wikipedia resources, including links to other related datasets. Tim Berners-Lee described DBpedia as one of the most famous parts of the decentralized Linked Data effort.
The Neuroscience Information Framework is a repository of global neuroscience web resources, including experimental, clinical, and translational neuroscience databases, knowledge bases, atlases, and genetic/genomic resources and provides many authoritative links throughout the neuroscience portal of Wikipedia.
Open data in Canada describes the capacity for the Canadian Federal Government and other levels of government in Canada to provide online access to data collected and created by governments in a standards-compliant Web 2.0 way. Open data requires that machine-readable should be made openly available, simple to access, and convenient to reuse. As of 2016, Canada was ranked 2nd in the world for publishing open data by the World Wide Web Foundation's Open Data Barometer. But as of July 2018, Canada was ranked 7th alongside Norway

The European Climate Assessment and Dataset (ECA&D) is a database of daily meteorological station observations across Europe and is gradually being extended to countries in the Middle East and North Africa. ECA&D has attained the status of Regional Climate Centre for high-resolution observation data in World Meteorological Organization Region VI ].

The Definition of Free Cultural Works is a definition of free content from 2006. The project evaluates and recommends compatible free content licenses.

The Open Government Initiative is an effort by the administration of President of the United States Barack Obama to "[create] an unprecedented level of openness in Government.". The directive starting this initiative was issued on January 20, 2009, Obama's first day in office.
Crown Copyright has been a long-standing copyright protection applied to official works, and at times artistic works, produced under royal or official supervision. In 2006, The Guardian newspaper's Technology section began a "Free Our Data" campaign, calling for data gathered by authorities at public expense to be made freely available for reuse by individuals. In 2010 with the creation of the Open Government Licence and the Data.gov.uk site it appeared that the campaign had been mostly successful, and since 2013 the UK has been consistently named one of the leaders in the open data space.
Open science data is a type of open data focused on publishing observations and results of scientific activities available for anyone to analyze and reuse. A major purpose of the drive for open data is to allow the verification of scientific claims, by allowing others to look at the reproducibility of results, and to allow data from many sources to be integrated to give new knowledge. While the idea of open science data has been actively promoted since the 1950s, the rise of the Internet has significantly lowered the cost and time required to publish or obtain data.
The Global Slavery Index is a global study of modern slavery published by the Minderoo Foundation’s Walk Free initiative. Four editions have been published: in 2013, 2014, 2016 and 2018.
Big data ethics also known as simply data ethics refers to systemizing, defending, and recommending concepts of right and wrong conduct in relation to data, in particular personal data. Since the dawn of the Internet the sheer quantity and quality of data has dramatically increased and is continuing to do so exponentially. Big data describes this large amount of data that is so voluminous and complex that traditional data processing application software is inadequate to deal with them. Recent innovations in medical research and healthcare, such as high-throughput genome sequencing, high-resolution imaging, electronic medical patient records and a plethora of internet-connected health devices have triggered a data deluge that will reach the exabyte range in the near future. Data Ethics is of increasing relevance as the quantity of data increases because of the scale of the impact.

FAIR data are data which meet principles of findability, accessibility, interoperability, and reusability. A March 2016 publication by a consortium of scientists and organizations specified the "FAIR Guiding Principles for scientific data management and stewardship" in Scientific Data, using FAIR as an acronym and making the concept easier to discuss.